原本今天想写写codereview相关,但脑海里冒出坏味道的实现,那就先整理下重构相关吧。
在线阅读重构-改善既有代码的设计
写在前面
作者马丁叔(原谅我权游中毒太深)认为,重构是一个过程:在不改变代码外在行为的前提下,对代码做出修改,以改进程序的内部结构。重构是一种经千锤百炼形成的有条不紊的程序整理方法,可以最大限度地减小整理过程中引入错误的概率。本质上说,重构就是在代码写好之后改进它的设计。
我们分析下:
- 不改变代码外在行为为前提
也就是重构后的代码,在业务功能上不能有任何变化,通俗的说,用户是无感知的。如何做到呢?就需要构筑测试体系。 - 对代码做出修改,以改进程序的内部结构
什么时候修改?如何修改?马丁叔给出坏味道的准则,以及针对坏味道给出解决方案。 - 形成的有条不紊的程序整理方法
哪些方法?就是马丁叔在书中的第6-12所描述的方法。 - 重构就是在代码写好之后改进它的设计
这很重要,重构是先有代码再进行,特别是符合我们当前流行的敏捷开发模式。所以重构是有成本的,如果它不能让我们更快更好的开发,那么则是毫无意义,它是一种经济适用行为,并非道德使然。 ,所以重构,应该从两个方向去看待,一个是对个体程序员的意义,一个是整体研发团队的战斗力。
所以牛逼的人就是不一样,一句话总结,点出全书的内容。那么,接下来我们也逐步分解看看吧。
重构的原则是什么?
提高迭代效率
如果你的需求只使用一次,那就不需要重构,没有任何意义。因为重构是有成本的,他的目的并非是你有代码洁癖症,就一定道德使然比如有一些迁移脚本,运营脚本等等,就本次上线的时候使用,后续根本不用去关注,那就遵从快速上线,功能实现即可。
重构一定是需要以提高研发效率为准则,比如我把重复方法进行封装,进行输出,改动该方法的时候,就只需要修改一个地方,而不需要到处寻找副本。
每一次提交代码,都应该使代码变得更好
重构不言大小,小到你修改一个变量名,也可以称之为重构,不要小看修改一个变量名,如果该名字不符合业务所表达的意思,则会造成理解上的偏差。提交好的代码,会让整个架构越来越稳固,从而打破原本的思路“软件会越来越庞大臃肿”,变为“系统会越来越坚固可靠”。所以作者建议拿到一个需求之后,先想好重构思路,再动代码。
增量式重构
大家不敢做重构的原因,就怕动到微小的东西整个大厦就崩塌了。特别是有着很重历史包袱(债务)的系统来说,都抱着系统可以运行,就不要动的想法,或者是这是人家写的代码,我就不动了的理念来看的话,这个系统会慢慢走向臃肿。其实这没什么可怕的,提高程序员开发效率的唯一办法,就是改变代码的结构。只要做好以下几点,大胆去干:
- 搭建自动化测试框架,必须要对整个系统有个正确的认识,对业务了解程度要深入。
- 持续集成,必须保证每次提交的代码,整个系统是可运行的。且每一步要保证足够简单,模块拆分的足够小,想象着可以随时停止,但系统可用的状态。
- TDD驱动重构
代码的坏味道
优雅的代码,就是易于理解,可扩展性良好,傻瓜都可以写给机器看的代码,只有优秀的人才可以写出给人看的代码。
我整理出来书中所说的24种坏味道的代码实现以及解决的方案,当然具体的还是得对着书籍查看,每次提交代码,或者给同事进行codereview的时候,都对着看一遍,看看是否有坏味道的实现,日行一善,从现在开始吧。
github上有整理出来更为完整的文档,可移步 坏味道及重构手法

归类版的坏味道
以上可以归类出如下经常犯错的案例
依赖传递
如A服务和B服务同时依赖了C服务,A服务写入C,B服务从C中读,这也是一种依赖,一旦某个服务产生了变更,则全部服务都需要变。交互产生依赖,多个模块之间的影响被交叉放大。
为什么我们的系统会如此的复杂?《A Philosophy of Software Design》作者john认为,复杂的系统往往具有变更放大、认知负荷、未知的未知这三类非常明显的特征。而模糊性与依赖性是引起复杂的两个主要因素:
- 模糊性产生了最直接的复杂度,让我们很难读懂代码真正想表达的含义,无法读懂这些代码,也意味着我们很难去改变它。一个模块的代码创建者和修改者通常并非一人,对代码的理解并非如最初创建时那么通透,如果没有划分业务owner,随着时间的推移,这块代码会慢慢变得模糊,只能用各种补丁叠加补丁的方式去维护,大家对一个业务模块的代码毫无爱护之心,只能烂下去。
- 依赖性又导致复杂性不断传递,不断外溢的复杂性最终导致系统的无限腐化,一旦代码变成意大利面,七七八八纵横交错依赖,几乎不可能修复,成本将成指数倍增长。
变更放大
指的是看似简单的变更需求,但是要在不同的地方进行代码修改,比如上述的A、B、C服务,一旦修改了C服务,那A、B服务都要跟着修改,万一A服务由依赖了其他几个或者十几个(微服务架构下很有可能),那每个服务都需要拉下来代码修改、测试、上线等,导致效率低下,操作变得极为复杂,又容易遗漏或者失误,这种在领域模型中的描述就是缺少内聚和收拢。 如下坏味道实现,打包的方法,证书分为应用和系统证书,打包成一个证书。其中应用证书和系统证书可能是不同的服务进行生成,此时如果一旦新增了第三类型的证书,那么这个方法的变更会指数倍的放大。我们的系统变得复杂,极大部分原因是变更放大导致的。
func packCert(appCert,sysCert)*certInfo {
}
关注放大
为了完成一次迭代任务,需要通读修改点附近上下文的代码,而附近的代码又需要关注附近的附近代码。又涉及到开发人员的知识储备或业务熟悉度,如果是模块代码的创建者可能一分钟就可以改好,但对于刚接手的人,可能通常为了弄清修改点的影响范围,需要理解超出此次迭代任务10倍以上的代码量。需要关注过度的上下文,造成心智负担,能以测试、调试,上线又极易出错。这怪新手咯?不能够吧,如果你的代码模块划分清楚,函数封装有道,命名足够准确,有没有神秘代码,强引用弱耦合,那可能改起来会非常顺畅和自信。否则,还会引起更加糟糕的情况就是未知的未知,特别是当你维护一个有20年历史的项目时,这种问题出现就没那么意外了,代码的混乱和文档的缺失,且代码本身也没有明显表现出它们应该要阐述的内容,你不知道改动这行代码能否让程序正常运转,也不知道这行代码的改动是否会引起新的问题,上线后,只能祈祷上帝了。

神秘命名
如果注释是对的,还好,如果注释都是错的,那就真的需要祭天。可能当时写这段代码的时候,你和上帝都知道这是什么意思,现在,只有上帝知道了。 有博客指出,好的命名,应该有三种境界,我深以为然:信、达、雅。
- 信: 准确无误地表达清楚行为的意义,做到见名之意。
- 达: 通达,考虑命名对整体架构的影响,与架构的设计哲学风格统一。
- 雅: 生动形象,看到名字即可准确理解其在整个程序之中的作用,并能产生辅助理解的形象。
过度设计
一条准则:第一次做某件事时只管去做;第二次做类似的事会产生反感,但无论如何还是可以去做;第三次再做类似的事,你就应该重构。正如老话说的:事不过三,三则重构。
过分的考虑程序未来所要面对的需求时,将陷入过度设计的陷阱,要相信其实你百分之六七十的设计在未来可能都使用不上,而且使当下的程序变得复杂。有的公司在技术评审的时候,有一条准则就是当前的设计,要满足未来五年都不需要改变。这简直就是扯淡,当时设计这个技术方案的人都不一定可以待够五年,当他离职了,后续该如何设计呢?所以按照互联网的迭代速度,满足接下来1年的需求变化,就可以了。
过分放大未来的某行风险,这些风险发生的概率过低,在项目可见的生命周期内都不可能遇到,则完全没必要设计。
Bad Case
1:证书的签发时长,如使用Duration来表示两个间隔的时长,使用纳秒计算最多可以表示290年,你非要签发300年后的证书,从而使用其他的设计去计算间隔时长,那就完全没有必要了,因为在项目可见的生命周期,这个项目应该是不会活过290年的。
// A Duration represents the elapsed time between two instants
// as an int64 nanosecond count. The representation limits the
// largest representable duration to approximately 290 years.
type Duration int64
2:对于一个50w DAU的IM系统,下图就是考虑过多的未来因素。并非说这个架构不好,只是说这个架构在目前阶段,是不切实际的,等到用户量上来了再重构,相信也是开着香槟重构吧。当然设计出来符合当前实际业务的架构,是非常吃经验的。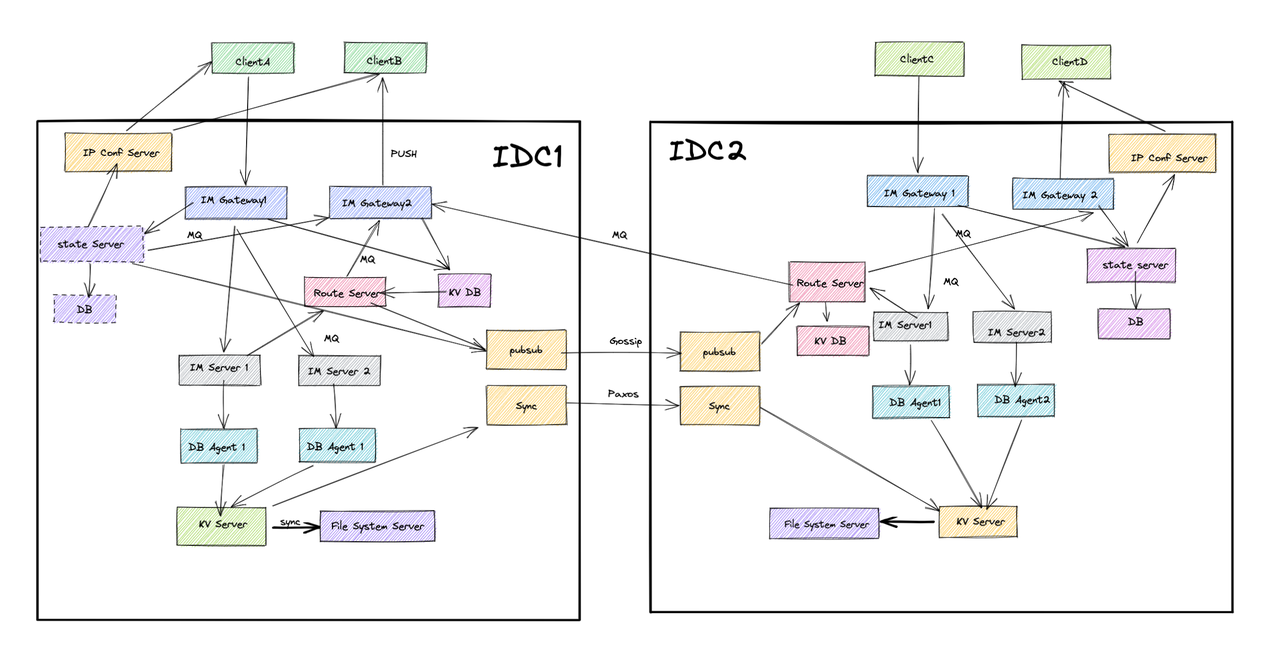
结构泥团
对于核心的数据结构,没有规范化的设计则会导致混乱。怎么理解?如果你在开发的过程中,会经常发现无法正常的在想要的函数里面获得对应的数据,需要各种嵌套调用,类似于数据泥团。如下我想引用一个字段,需要跨域出很多的模块才可以,其实也是关注放大的问题。
a.b.c.d.e()
全局盲区
容易出现在大型项目的开发中,特别是现在微服务的架构,大家都在自己所负责的模块中去迭代,缺乏了全局视角,对数据结构或者接口的设计不可避免的造成冗余或者混乱。比如张三和李四分别自己服务里面开发了一个类似的接口,这就造成了资源的浪费。
或者是各个模块都有着自己统一的架构风格,久而久之整个系统就出现了泥团了,所以一定要有全局概念,局部不等于整体,应该要去追求全局最优解。