
redis每天都在用,可却未全面的去了解他,导致一些时候可能会选错了主键。现在,终于可以静下心来去好好整理下相关框架。
简介
NoSQL:not-only-sql,不仅仅是sql。redis就是这个派系的代表之作。
redis:remote dictionary server,远程词典服务器,是一个基于内存的键值型NoSQL数据库。
他的作者是Salvatore Sanfilippo (antirez),虽然他的头发还有很多,但是丝毫不影响他的大牛气质。redis的诞生,也是他和朋友一起开发一个网站,由于mysql的性能导致一个负载问题迟迟得不到解决,从而发明了redis来解决这个问题。
redis有以下特征,成为了nosql的标杆:
- 键值型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存,io多路复用以及良好的编码)
- 支持数据持久化
- 支持主从集群、分片集群
- 支持多语言客户端
安装及启动
redis只有Linux版本的,Windows版本非官方,是微软自己弄出来的。所以我们基于Linux安装。
安装redis
redis是基于c语言编写的,所以先需要安装gcc依赖:
yum install -y gcc tcl安装redis
#更新包:
sudo yum install epel-release
sudo yum install https://rpms.remirepo.net/enterprise/remi-release-7.rpm
sudo yum-config-manager --enable remi
#安装最新版
yum install redis-6.2.6
#查看是否安装成功
[root@VM-4-9-centos /]# redis-server --version
Redis server v=7.2.1 sha=00000000:0 malloc=jemalloc-5.3.0 bits=64 build=ad8cec40cd2b9de2
启动
#启动
systemctl start redis
#停止
systemctl stop redis
#重启
systemctl restart redis
修改配置文件
目前我们是启动了,但是还不能登录,因为还不知道账号密码,也不能远程登录。
修改redis.conf,如果找不到,直接whereis吧,最好先备份。
修改这么几个地方
#监听地址,127.0.0.1只能在本地访问,0.0.0.0任意ip访问
bind 0.0.0.0
# yes为后台运行
daemonize yes
#密码 123456 也可以为空
requirepass 123456
#端口,默认6379,建议不动
port 6379
修改完成后重启即可。
链接
使用命令行客户端
一般来说:redis-cli -a 123456
还有选项:
- -h 指定ip地址,默认127.0.0.1,默认情况下不填写
- -p 指定端口,默认6379可以不填写
- -a 123456 密码,为空情况下不填写
如:redis-cli -h 32.13.55.43 -p 6378 -a 123456
使用可视化工具-推荐
使用redis desktop manager工具链接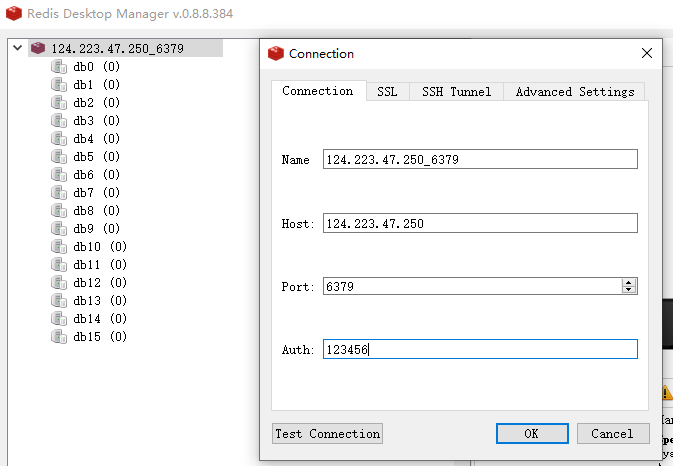
使用各个语言去连接redis
数据结构及其操作
reids支持多种数据类型,主要是如下八种:
- 字符串(String):最基本的数据类型,可以存储文本、二进制数据等。字符串类型是Redis中最常用的数据类型。
- 哈希(Hash): 哈希数据结构用于存储键值对的集合,类似于Python中的字典或JavaScript中的对象。在Redis中,哈希类型的键存储了多个字段和对应的值。
- 列表(List): 列表是一个有序的字符串元素集合,可以在列表的头部或尾部添加或删除元素。它们通常用于实现队列、堆栈等数据结构。
- 集合(Set): 集合是一个无序的字符串元素集合,不允许重复的元素。集合支持添加、删除和检查元素是否存在等操作。
- 有序集合(Sorted Set): 有序集合是类似于集合的数据类型,但每个元素都有一个分数(score),用于对元素进行排序。有序集合通常用于构建排行榜、范围查询等。
- 位图(Bitmap): 位图是一个特殊的字符串,可以用于位操作。它通常用于处理标志、计数器等。
- 超级日志(HyperLogLog): 超级日志是一种用于估计基数(不重复元素的数量)的数据结构。它可以用于统计独立访客数、唯一IP数等。
- 地理空间索引(Geospatial Index): Redis支持地理空间索引,可以用于存储地理位置信息和执行空间查询。
通用命令
通用命令很多,我们可以通过官方文档查看通用命令
| 命令 | 说明 | 示例 | 其他 |
|---|---|---|---|
| kyes | 查看符合模版的所有key | keys a:表示查看可以a,keys * 表示查看所有,keys a* 表示以a开头的模糊查询 | 不建议模糊查询,因为单线程的 |
| del | 删除key,可以删除多个 | del a,del aa ab :删除了aa和ab的key | - |
| exists | 判断一个key是否存在,返回1表示存在,0表示不存在 | exists aa | - |
| expire | 设置key有效期,以秒为单位到期后自动删除 | expire aa 10:表示设置key为aa的有效期为10s | 不过期为-1 |
| ttl | 查看一个key的剩余有效期 | ttl ab | -1为不过期,-2为这个key不存在 |
string 类型
字符串类型,是redis中最简单的存储类型,其value是字符串,不过根据字符串的格式不同,又可以分为三类:
- string:普通字符串,如 hello world
- int:整数类型,可以做自增、自减操作,如10
- float:浮点类型,可以做自增、自减操作,如10.3
不管是哪种格式,底层都是字节数组形式存储,只不过是编码方式不同。字符串类型的最大空间不能超过512M。
用户存储最简单的数据,比如json、计数器、session共享或者是分布式id等等。
常见命令
set:添加或者修改已经存在的一个string类型的键值对。
127.0.0.1:6379> set a "hello world" OK 127.0.0.1:6379> set b 10 OK 127.0.0.1:6379> set c 10.3 OKget:根据key获取string类型的value
124.223.47.250_6379:0>get a "hello world" 124.223.47.250_6379:0>get ab "ab"mset:批量添加多个string类型的键值对
# 表示设置key为c的value为ac 124.223.47.250_6379:0>mset c ac b ab "OK"mget:根据多个key获取多个string类型的value
124.223.47.250_6379:0>mget a ab 1) "hello world" 2) "ab"incr:让一个整形的key自增1
124.223.47.250_6379:0>set d 1 "OK" 124.223.47.250_6379:0>incr d "2" 124.223.47.250_6379:0>get d "2"incrby:让一个整形的key自增并指定步长,例如:incrby num 2,则是让key为num的value增加2
124.223.47.250_6379:0>incrby d 4 "6" 124.223.47.250_6379:0>get d "6"incrbyfloat:让一个浮点类型的数组自增并指定步长
124.223.47.250_6379:0>set f 10.2 "OK" 124.223.47.250_6379:0>incrbyfloat f 3 "13.2" 124.223.47.250_6379:0>get f "13.2"setnx:添加一个string类型的键值对,前提是这个key不存在,否则不执行
# a已经存在,则返回0 124.223.47.250_6379:0>setnx a a "0" #aa不存在,则创建aa,返回1 124.223.47.250_6379:0>setnx aa aa "1"setex:添加一个string类型的键值对,并且指定有效期
其实是一个组合命令,一个是set,一个是expire,这个用的比较多。
124.223.47.250_6379:0>setex name 10 zhangsan "OK" 124.223.47.250_6379:0>get name "zhangsan" 124.223.47.250_6379:0>ttl name "1" 124.223.47.250_6379:0>get name null
最佳实践
string我们在工作中用的相对较多,但也会导致一个问题就是key的重复性,redis不像mysql有主键冲突,比如blog项目中订单管理需要存储user的id为2和product的id为2,总不能使用id作为key吧,这样会造成混淆。
其实,redis的key允许多个单词形成层级结构,最佳实践是多个单词使用:隔开,比如上述案例就可以指明如下:
124.223.47.250_6379:0>set blog:order:user:2 '{"id": 2,"name": "zhangsan"}'
"OK"
124.223.47.250_6379:0>set blog:order:product:2 '{"id": 2,"name": "洗衣机"}'
"OK"
这种在命令行中看上去是没什么的,但是在可视化界面,会自动给我们根据:来进行层级分割,看上去就比较清晰和优雅。
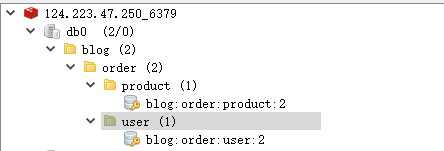
不单单是string类型,所有类型的key都建议使用:来隔开。
Hash类型
hash类型,也叫散列,它的value是一个无序字典,类似java、go中的hashmap
如上例子,在string中,key为blog:order:user:2,如果我想修改name字段为lisi,我需要先拿出来这个json,然后改完json,再存回去。但是如果采用的是hash中就不用,直接根据name字段修改即可。
一般适用于查询缓存对象,或者是一些经常变动的一些信息,比如用户的会话信息,或者是系统的配置信息等等。
常见命令
命令大部分都和string类似,在前面加一个h。
hset key field value:添加或者修改hash类型key的field的值。
124.223.47.250_6379:0>hset blog:order:user:1 id 1 "1" 124.223.47.250_6379:0>hset blog:order:user:1 name zhangsan "1"hget key filed:获取一个hash类型key的field的值
124.223.47.250_6379:0>hget blog:order:user:1 name "zhangsan"hmset:批量添加多个hash类型key的filed的值
hmset key field1 value filed2 value filed3 value# 添加key为blog:order:user:3的id为3,name为lisi 124.223.47.250_6379:0>hmset blog:order:user:3 id 3 name lisi "2"hmget:批量获取多个hash类型的key的field的值
hmget key field1 filed2 filed3124.223.47.250_6379:0>hmget blog:order:user:3 id name 1) "3" 2) "lisi"hgetall:获取一个hash类型的key中所有的filed和value
124.223.47.250_6379:0>hgetall blog:order:user:3 1) "id" 2) "3" 3) "name" 4) "lisi"hkeys:获取一个hash类型的key中所有的field
124.223.47.250_6379:0>hkeys blog:order:user:3 1) "id" 2) "name"hvals:获取一个hash类型的key中所有的value
124.223.47.250_6379:0>hvals blog:order:user:3 1) "3" 2) "lisi"hincrby:让一个hash类型的key的字段值自增并指定步长
124.223.47.250_6379:0>hmset blog:order:user:3 age 18 "OK" 124.223.47.250_6379:0>hget blog:order:user:3 age "18" 124.223.47.250_6379:0>hincrby blog:order:user:3 age 2 "20"hsetnx:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
# age已经存在了,不执行,返回0 124.223.47.250_6379:0>hsetnx blog:order:user:3 age 18 "0" 124.223.47.250_6379:0>hsetnx blog:order:user:3 sex 1 "1"
List类型
有点类似java的linkedlist类型,不熟悉java的可以理解为这是一个双向链表结构,也就是既可以支持正向检索,也可以支持反向检索。
也就是即可当做队列来用,也可当做栈来用。
他具有以下特征:
- 有序,比如朋友圈的点赞、评论,有先后循序。
- 元素可以重复
- 插入和删除比较快,核心命令就两个,一个是push,一个是pop,能不快么。
- 查询速度一般
常见命令
lpush key element...:向列表左侧插入一个或多个元素
最新的在左侧插入,可以理解为栈,每次都在栈顶插入
124.223.47.250_6379:0>lpush user:id 1 2 3 "3"lpop key:移除并返回列表左侧的第一个元素,没有则返回nil
如上,我们取id为user:id的话,那会取出最后插入的,也就是3
124.223.47.250_6379:0>lpop user:id "3" 124.223.47.250_6379:0>lpop user:id "2" 124.223.47.250_6379:0>lpop user:id "1" 124.223.47.250_6379:0>lpop user:id nullrpush key element...:向右侧插入一个或多个元素
最新的在右侧,可以理解为队列,每次都在队尾添加。
124.223.47.250_6379:0>rpush user:id 1 2 3 "3"rpop key:移除并返回列表右侧的第一个元素
如上,我们取id为user:id的话,那会取出最后插入的,也就是3
124.223.47.250_6379:0>rpop user:id "3" 124.223.47.250_6379:0>rpop user:id "2" 124.223.47.250_6379:0>rpop user:id "1" 124.223.47.250_6379:0>rpop user:id nulllrange key star end:返回一段角标范围内的所有元素
怎么理解?比如使用我们使用
lpush user:id 1 2 3 4 5那么每次最新的都在左边,则在内存中的循序是5,4,3,2,1也就是第0为是5...第4为是1。所以如果我们的star是0,end为2的话,那么就是,5 4 3
124.223.47.250_6379:0>lrange user:id 0 2 1) "5" 2) "4" 3) "3"blpop和brpop,与lpop和rpop类似,区别是前者是阻塞的,没有元素时阻塞等待指定时间,而不是返回nil。
也就是如果user:id没有值,我等待2s,等完后还是没有的话,我就返回,如果这2s期间有新的数据插入的话,我就返回对应的数据。
124.223.47.250_6379:0>blpop user:id 2
思考下
如何利用list结构模拟一个栈?
栈,先进后出,后进先出。那么可以:
进lpush,出的话使用lpop
124.223.47.250_6379:0>lpush user:id 1 2 3 "3" 124.223.47.250_6379:0>lpop user:id "3" 124.223.47.250_6379:0>lpop user:id "2" 124.223.47.250_6379:0>lpop user:id "1" 124.223.47.250_6379:0>lpop user:id null进使用rpush,出使用rpop
124.223.47.250_6379:0>rpush user:id 1 2 3 "3" 124.223.47.250_6379:0>rpop user:id "3" 124.223.47.250_6379:0>rpop user:id "2" 124.223.47.250_6379:0>rpop user:id "1" 124.223.47.250_6379:0>rpop user:id null
简单理解为:出口入口同一边 更为简单的:你去喝酒,喝完吐了,入口出口同一个口就是栈。
如何利用list结构模拟一个队列?
队列,先进先出,后进后出,那么可以:
- 进lpush,出rpop
- 进rpush,出lpop
简单理解为:出口入口不在同一边 更为简单的:你去喝酒,喝完生理排除,入口出口不是同一个口就是队列。
如何利用list结构模拟一个阻塞队列?
- 首先他是队列,入口和出口不在同一边
- 其次阻塞,也就是出队列的时候,采用blpop或者brpop。
set类型
redis的set结构和java中的hashset类型,可以看做一个value为null的hashmap,也可以理解为go语言中的map[string]struct{},因为不关心value值关心key。所以:
- 它是无序的,存储和插入循序无关
- 元素不可重复
- 查找快,时间复杂度为0(1),连value都没有,能不快么。
- 支持交集、并集、差集等功能。
比较适合场景如:实现类似我和某人共同关注、朋友圈点赞等等功能。
常用命令
- sadd key member ...: 向set中添加一个或多个元素。
- srem key member ...: 移除set中的指定元素。
- scard key:返回set中的元素个数
- sismember key member:判断一个元素是否存在于set中
- smembers:获取set中的所有元素
124.223.47.250_6379:0>sadd user:ids 1 2 3 4 5 #添加
"5"
124.223.47.250_6379:0>srem user:ids 1 #移除指定元素
"1"
124.223.47.250_6379:0>smembers user:ids #获取所有元素
1) "2"
2) "3"
3) "4"
4) "5"
124.223.47.250_6379:0>scard user:ids # 返回元素个数
"4"
124.223.47.250_6379:0>sismember user:ids 1 #判断元素是否在key中,0不存在,1存在。
"0"
124.223.47.250_6379:0>sismember user:ids 2
"1"
- sinter key1 key2 ... :求key1和key2的交集
- sdiff key1 key2 ... :求key1和key2的差集
- sunion key1 key2 ... :求key1和key2的并集
124.223.47.250_6379:0>sadd user1:ids 1 3 4 5 6
"5"
124.223.47.250_6379:0>sadd user2:ids 1 2 5 8 9
"5"
124.223.47.250_6379:0>sinter user1:ids user2:ids #交集
1) "1"
2) "5"
124.223.47.250_6379:0>sdiff user1:ids user2:ids #差集
1) "3"
2) "4"
3) "6"
124.223.47.250_6379:0>sunion user1:ids user2:ids #并集
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "8"
8) "9"
SortedSet
是一个可排序的set集合,和java的treeset类似。但sortedset每个元素都带了一个score属性,基于score属性对元素进行排序。具备:
- 可排序
- 元素不重复
- 查询速度快 使用场景,微信运动的排行榜,福布斯财富排行榜。
常见命令
- zadd key score member:添加一个或多个元素到sortedset,如果已经存在则更新score值
- zrem key member:删除sorted set中的一个指定元素
- zscore key member:获取sortedset中指定元素的score值
- zrank key member:获取sorted set中的指定元素排名
- zcard key:获取sorted set中的元素个数
- zcount key min max:获取sortedset中给定范围内的所有元素个数
- zincrby key increment member:让sortedset中的指定元素自增,步长为指定的increment值
- zrange key min max:按照score排序后,获取指定排名范围内的元素
- zrangebyscore key min max:按照score 排序后,获取指定score范围内的元素
- zdiff、zinter、zunion:求差集、交集、并集
124.223.47.250_6379:0>zadd student 95 zhangsan 90 lisi 85 wangwu 50 maliu 100 guijiaoqi # 添加多个元素
"5"
124.223.47.250_6379:0>zrem student guijiaoqi # 删除一个指定元素
"1"
124.223.47.250_6379:0>zscore student zhangsan # 获取指定元素的score
"95"
124.223.47.250_6379:0>zrank student zhangsan # 获取指定元素排名
"3"
124.223.47.250_6379:0>zcard student # 获取元素个数
"4"
124.223.47.250_6379:0>zcount student 90 100 # 根据score的min和max获取中间的元素个数
"2"
124.223.47.250_6379:0>zincrby student 2 zhangsan # 根据指定的步长让元素自增
"97"
124.223.47.250_6379:0>zrange student 0 5 # 按照根据score从小到大排好序后,根据指定元素获取值
1) "maliu"
2) "wangwu"
3) "lisi"
4) "zhangsan"
124.223.47.250_6379:0>zrangebyscore student 90 100 # 指定元素的score范围获取值
1) "lisi"
2) "zhangsan"
所有的排序都是从小到大正序,如果需要降序则在z后面添加rev,比如 zrevrange student 0 5
go语言来连接redis
首先需要导入redis库 go get github.com/go-redis/redis/v8
简单演示操作string和hash吧。
链接redis
func initRedis() *redis.Client {
rClint := redis.NewClient(&redis.Options{
Addr: "124.223.47.250:6379", // Redis服务器地址和端口
Password: "123456", // Redis服务器密码(如果有的话)
DB: 0, // 使用的数据库编号,默认为0
})
return rClint
}
操作string
func operateString(ctx context.Context, redisClient *redis.Client) {
if err := redisClient.Set(ctx, "go:user:name", "hello redis", 0).Err(); err != nil {
return
}
value, err := redisClient.Get(ctx, "go:user:name").Result()
if err != nil {
return
}
fmt.Println(value)
}
操作hash
func operateHash(ctx context.Context, redisClient *redis.Client) {
if err := redisClient.HSet(ctx, "blog:order:user:1", "id", 1, "name", "zhangsan", "age", 18).Err(); err != nil {
return
}
//value, err := redisClient.HGet(ctx, "blog:order:user:1", "name").Result() // 获取单个字段
value, err := redisClient.HGetAll(ctx, "blog:order:user:1").Result() //获取所有字段,map返回
if err != nil {
return
}
fmt.Println(value)
}

