
在db中进行搜索,大数据下,怕是扛不住。所谓术业有专攻,elasticsearch就是为搜索而生。
博主之前项目中有用到过ES,但是仅仅是前人写的代码用过而已,对其原理及大范围的使用不甚了解,今天就一起来学习下吧。
本文从零开始,使用docker搭建,使用go语言作为demo进行讲解。
前言
elasticsearch :简称ES,是一个开源的高扩展的分布式全文检索引擎,近乎实时的存储、检索数据,它的目的是通过简单的restful api来隐藏底层的复杂性,从而让全文搜索变得简单。底层是开源库Lucene (apache旗下的全文索引检索工具),当然,Lucene不在讨论之内,只要知道ES是Lucene的封装。
ES的诞生,背后也有一个美好的爱情故事,传说,多年以前,有个小伙开发者叫做 shay banon,他刚结婚不久就被优化了,他的美丽的妻子是一名厨师,要去伦敦进修学习,但在网上寻找食谱的过程中比较艰难,于是乎,他就想给妻子搭建一个搜索引擎,就是早期的 Lucene ,且发布了一个早期的开源项目“Compass”。后来 shay找到了一份工作,这份工作出在高性能和内存数据网格的分布环境中,所以高性能、实时的、分布式的搜索引擎也是理所当然的,然后他就决定重写compass库,使其成为一个独立的服务,也就是目前要学习的elasticsearch。
再后来,第一个公开版本在2010年出现了,并且成为github最受欢迎的项目之一。他的端口9200,都是他妻子的九宫格输入的缩写,然而,他的妻子还在等着他的食谱搜索...

安装
看过其他博客的都知道,我比较喜欢把应用软件安装在docker中,当然ES也不例外。
ES的安装
创建docker网络,后面用于KiBana的连接
docker network create elastic拉取镜像
docker pull elasticsearch:7.12.0创建容器
docker run --name es --net elastic -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms84m -Xmx512m" -d elasticsearch:7.12.0
ok,此次,如果你的防火墙都配置好了,可以访问http://124.223.47.250:9200/
// 20231022101607
// http://124.223.47.250:9200/
{
"name": "faf1e4fd326a",
"cluster_name": "docker-cluster",
"cluster_uuid": "cD_YOwPyS7S-nXhibURXaA",
"version": {
"number": "7.12.0",
"build_flavor": "default",
"build_type": "docker",
"build_hash": "78722783c38caa25a70982b5b042074cde5d3b3a",
"build_date": "2021-03-18T06:17:15.410153305Z",
"build_snapshot": false,
"lucene_version": "8.8.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
安装浏览器插件 elasticsearch-head
当然,我们也是需要有一些可视化界面的,可以安装谷歌浏览器插件 Multi Elasticsearch Head
这个插件,在学习的时候完全可以替代客户端,可以查看多少索引、数据展示,在上面做查询、新建等等。完全可以当做一个数据展示工具。
当然,查询的话,使用Kibana会更好一点。
KiBana
针对ES的开源分析及可视化平台,用来搜索、查看交互存储在ES索引中的数据(这个head也是可以的),而且通过KiBana,可以通过各种图表进行高级数据分析及展示,KiBana让海量数据更容易理解。操作简单,基于浏览器的用户界面可以快速创建仪表盘,实时显示ES查询动态,安装设置也非常简单。
更多的介绍,直接去Kibana官网吧. 只是我们使用的KiBana,最好是和ES的版本一致。
1:拉取镜像docker pull docker.elastic.co/kibana/kibana:7.12.0
2:运行docker run --name kibana01 --net elastic -p 5601:5601 -d docker.elastic.co/kibana/kibana:7.12.0
3:进入容器内,修改/usr/share/kibana/config/kibana.yml配置,elasticsearch.hosts: [ "http://es:9200" ]或者是真实的ip:9200。
4:修改防火墙后直接访问5601端口,如: http://124.223.47.250:5601/app/home#/
至此,环境搭建完成。
ES基本概念
前面环境ok了,那es如何存储数据,数据结构又是什么?如何实现搜索的呢?等等等等,先别急,先了解相关概念吧。
数据我们熟悉了,可以把他当成数据库,以下是对比:
| MySQL | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types(弃用了),因为索引就可以关联文档了 |
| 行(rows) | 文档(documents) |
| 字段(columns) | fields |
所以,ES是面向文档的,简而言之,一切都是JSON。
既然是面向文档的,那意味着索引的最小单位就是文档,ES中文档有几个重要的属性:
- 自我包含,一篇文档同时包含字段和对应的值,简单理解,就是同时包含key:value.
- 可以是层次型的,一个文档中包含自文档,负责的逻辑实体就是这么来的。其实就是一个json对象。
- 灵活的结构,文档不依赖预先定义的模式,怎么理解?比如在mysql中,我们要先定义字段才能使用是把,但是在ES中,有时候可以忽略字段,或者动态加一个新的字段,至于类型,ES会自动给你合适的类型。
索引
索引可以理解为mysql的数据库,能搜索的数据必须在索引上,比如新华字典前面的目录,根据A-Z排序,其中A-Z都可以看到单独的一个索引,然后索引中有很多文档。
ES索引的精髓:一切设计都是为了提高搜索的性能。
倒排索引
搜索的核心,就是全文检索,也就是需要在大量的文档中找到包含某个单词出现的位置,在mysql中,我们通过like来实现,但是使用了like可能导致索引实现导致全表扫描,那性能就很低了,而且只能首尾模糊匹配,有点鸡肋。于是乎,倒排索引应运而生。
如何讲明白倒排索引呢,我们先来说说正排索引吧。
正派索引:就是以对象的唯一ID作为索引,所有的文档内容作为记录的结构,比如我们要通过id找user的详情。而倒排索引,就是把user详情的所有单词拆开,每个单词/词组都对应着id,如果有不同id相同词组,则对应着不同id,如下图表达着正排和倒排的区别: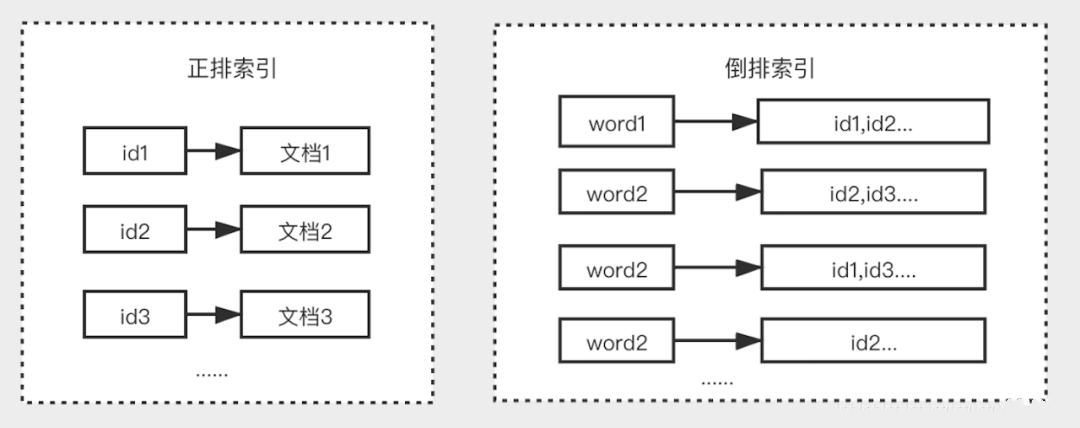
再来举一个例子就明白了:
假设有两个文档的内容:
doc1:中华人民共和国万岁
doc2:中国人民万岁
生成倒排索引,首先都会文档进行分词,分词后续详解,先理解为就是将一段连续的文本,根据语义或者配置文件拆分多个单词或者词组。 然后按照单词来做索引,对应的文档id建立一个链表,就能构成倒排索引结构,如:
| word | documents id |
|---|---|
| 中华 | doc1 |
| 人民 | doc1、doc2 |
| 共和国 | doc1 |
| 万岁 | doc1、doc2 |
| 中国 | doc2 |
所以,如果我们搜索中华则匹配到了doc1,如果要搜索人民、万岁,则doc1和doc2都满足,如果要搜索中国,则doc2满足。
如果要搜索 共和国万岁则会匹配doc1和doc2,但是doc1会在前面,因为它的权重(score)更高一点。
所以,倒排索引就只需要查看相关的文档id即可,过滤掉无关的所有数据,提高效率。
至于倒排索引的数据结构和核心算法,本文先列出一张图,后续会出具体的详情介绍: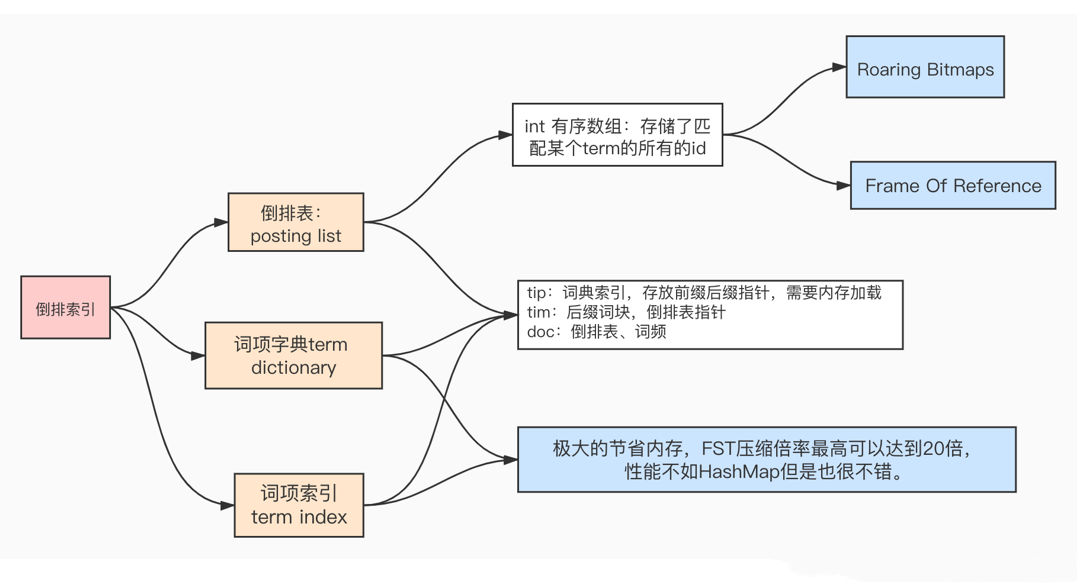 倒排索引分为倒排表(posting_list)、词项字典(term dictionary)、词项索引(term index)三部分组成 ,其中倒排表是一个int类型的有序数组 ,存储了匹配某个term(词汇)的所有文档的id, 词项字典分为三部分组成 tip、tim、doc(各个部分的含义如上图)
倒排索引分为倒排表(posting_list)、词项字典(term dictionary)、词项索引(term index)三部分组成 ,其中倒排表是一个int类型的有序数组 ,存储了匹配某个term(词汇)的所有文档的id, 词项字典分为三部分组成 tip、tim、doc(各个部分的含义如上图)
文档
一个文档就是一个可被索引的基础信息单元,也就是一条数据。文档以json格式来表示,而json是一个导出存在的交互格式。在es中,可以理解为Mysql的一行数据。
分片
分片可以简单理解为数据库中的分表,一张表容纳不下,或者访问效率低了,就需要分表。同理,es叫做分片。
一个索引可以存储超出单个节点硬件限制的大量数据,ES提供将索引划分多分的能力,每一份就是一个分片,创建一个索引的时候,可以指定你想要的分片数量,默认为5。每个分片本身也是一个功能完善并且独立的索引,这个索引可以放置到集群中的任何一个节点上。分片很重要,主要有两个方面的原因:
- 允许水平分割/扩展你的内容容量。
- 允许你在分片之上进行分布式并行的操作,进而提高性能和吞吐量。 至于一个分片如何分步,文档如何聚合和搜索请求,完全有ES管理,用户来说无需关心。
映射 mapping
mapping是处理数据的方式和规则方面做一些限制,比如某个字段的数据类型、默认值、分析器、是否被索引,哪些字段可以被查询到,哪些字段可以分词,采用什么分词等等,这些映射都可以设置的,其他处理ES里面数据的一些使用规则设置,也叫做映射,按着最优处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
分词器-IK分词器
上述也说了,就是把一段文本划分成一个个的关键字,然后在搜索的时候把自己的信息进行分词,把数据库中所有索引中的数据进行分词,再进行一个个匹配操作。ES默认的内置分词器对中文的分词效果可能不太理想,因为它主要是针对英文设计的,所以我们要在中文获得更好的分词效果,可能使用专门的中文分词插件。其中IK分词器作为代表。IK分词器,是一个开源的中文分词器插件,特别为ES设计和优化,在中文文本的分词处理上表现出色,可能根据中文语言习惯进行精细的分词。
插件下载地址:https://github.com/medcl/elasticsearch-analysis-ik/
注意:需要根据对应的ES版本下载对应的IK分词器包。
我们的IK分词器,提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分。后续有例子。
安装
下载zip包完成后,放入对用的es安装目录的plugins中(/usr/share/elasticsearch/plugins),解压即可。 我是docker安装,所以进入容器后,执行一行命令:bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.0/elasticsearch-analysis-ik-7.12.0.zip
然后重启容器即可,重启完成后,再次进入容器,使用bin/elasticsearch-plugin list 查看是否安装成功。
坑
1:使用docker直接安装后,需要先进入容器中的plugins目录,把elasticsearch-analysis-ik-7.12.0.zip删掉,然后再重启容器,否则会报错,因为无法加载.zip这个鬼。如果你已经踩坑了,恭喜你,ES无法启动了。 不过你可以先将把整个plugin文件夹考出宿主机,然后删掉zip文件后,再次复制回容器内,这样就替换了。
2:如果直接安装,超时的话,可以下载对应的zip包手动拷贝进容器的plugin文件夹,创建ik文件夹,然后使用unzip xxx.zip -d ik来解压进去,然后删除zip包重启,一样的。
[root@VM-4-9-centos ~]# docker exec -it 6784ef81004b /bin/bash
[root@6784ef81004b elasticsearch]# cd plugins/
[root@6784ef81004b plugins]# ls
elasticsearch-analysis-ik-7.12.0.zip
[root@6784ef81004b plugins]# mkdir ik
[root@6784ef81004b plugins]# unzip elasticsearch-analysis-ik-7.12.0.zip -d ik/
[root@6784ef81004b plugins]# rm -rf elasticsearch-analysis-ik-7.12.0.zip
//重启
[root@6784ef81004b elasticsearch]# bin/elasticsearch-plugin list
ik
使用KiBana测试
ik_smart
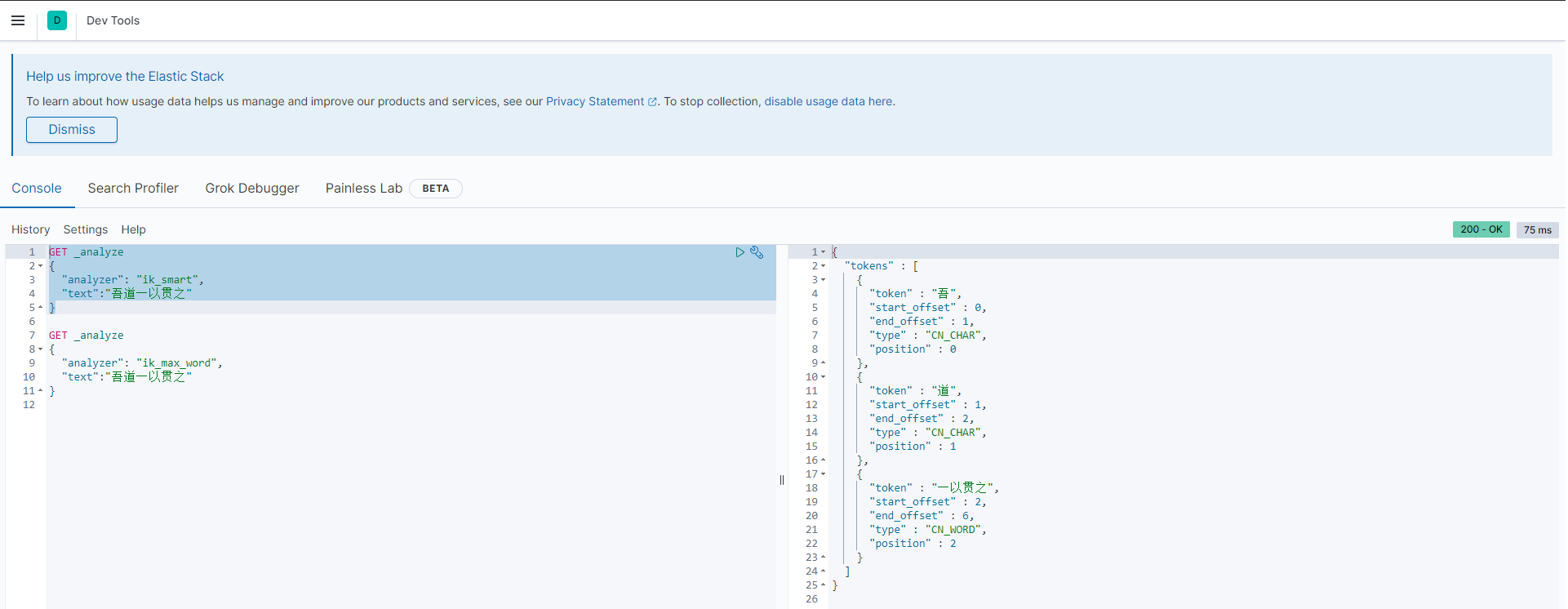
这个就是最少切分,把认为是一个词组的切分一起。没有重复的数据。ik_max_word
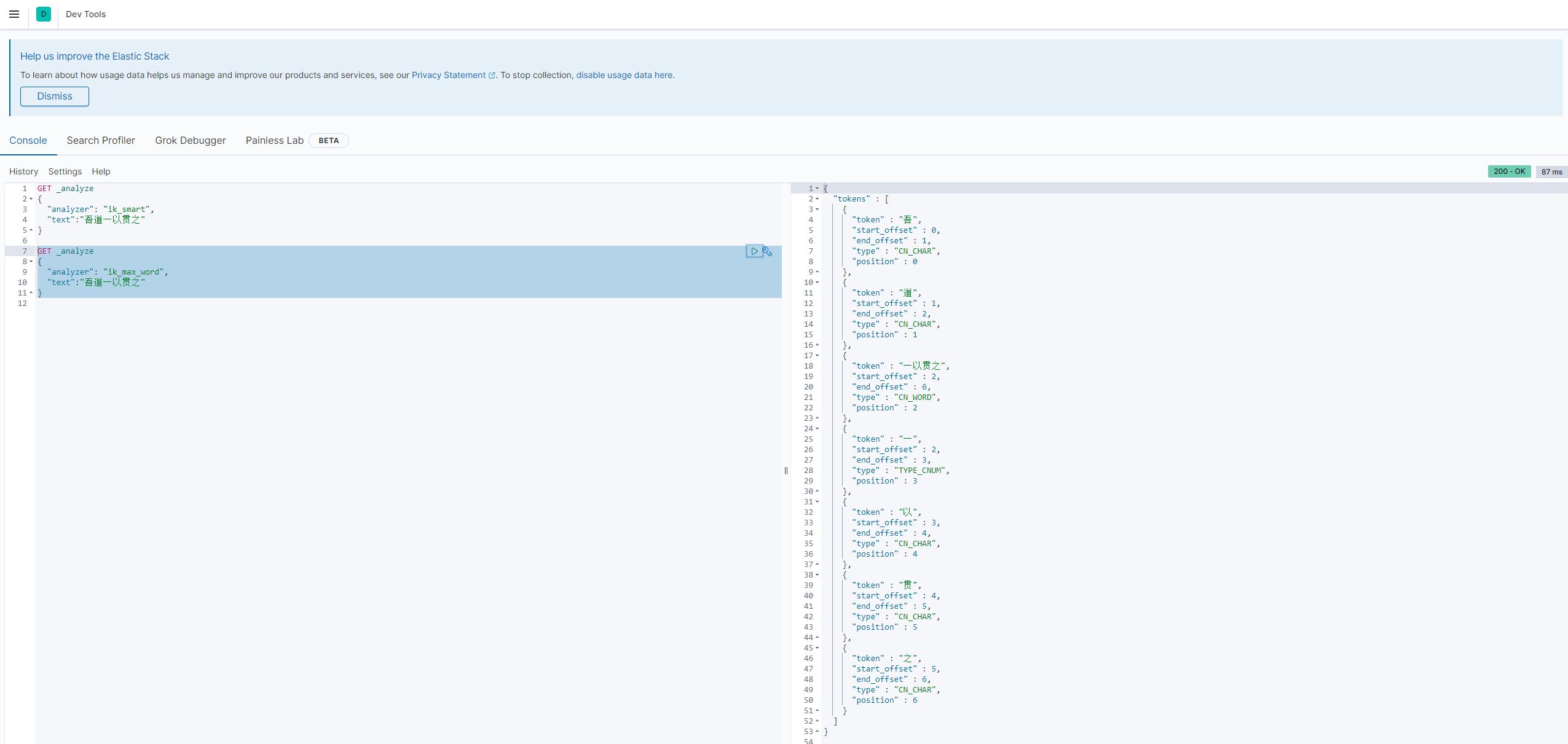
最少粒度切分,穷尽词库的可能。 有可能会有重复的数据
自定义词
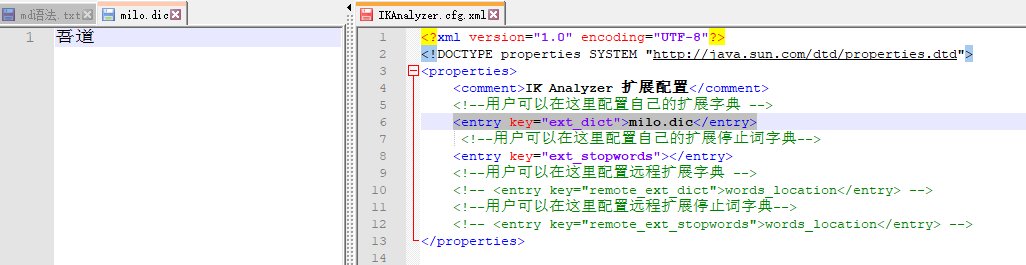
如上,我想让 "吾道" 一词,作为一个不可拆分的词组,怎办?
那就需要自己加到我们ik分词器的字典中。
先到plugin路径下,找到刚刚创建的ik文件夹,然后进入config目录。
- 新增一个自己的字典,比如milo.dic,里面添加 吾道 词组,放在一行。
- 找到 IKAnalyzer.cfg.xml 目录,并把 milo.dic 加入到自定义key中,如下图即可,并重启es。
- 测试,吾道二字,并未分开。
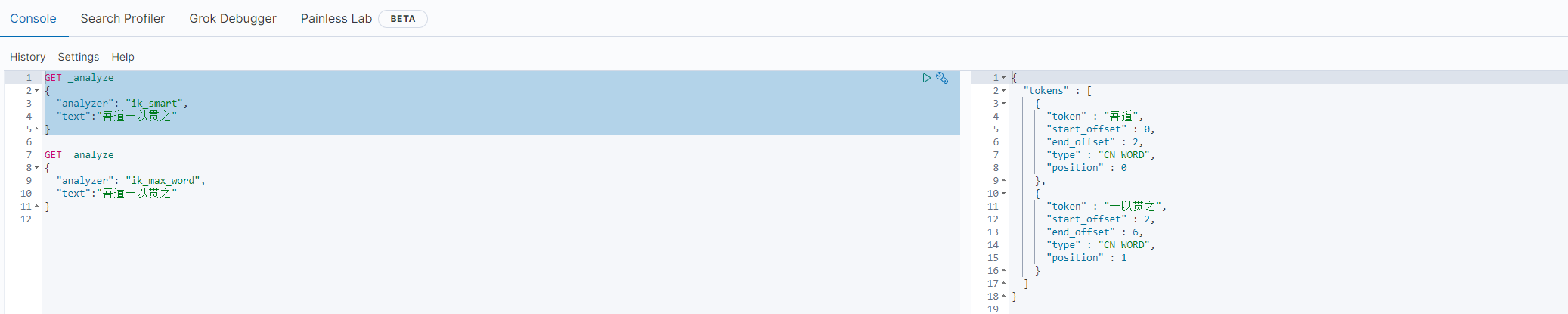
就是,编写自己的字典,加入到配置文件中。
开干
之前说过,ES是通过restful风格的,所以我们就像调用接口一样去调用ES即可。这里你可以使用KiBana也可以使用postman等等去调用。
前缀为es地址,如pre=localhost:9200
| method | url | 描述 |
|---|---|---|
| PUT | pre/索引名称 | pre/user:创建一个user索引 |
| POST | pre/索引名称 | 创建文档,id随机 |
| 锁机制 | 行锁 | 表锁 |
索引
之前我们对比过,索引理解为库,存数据都需要在库里面(es没有表概念了)。
创建索引
创建索引就一条命令 /索引名称
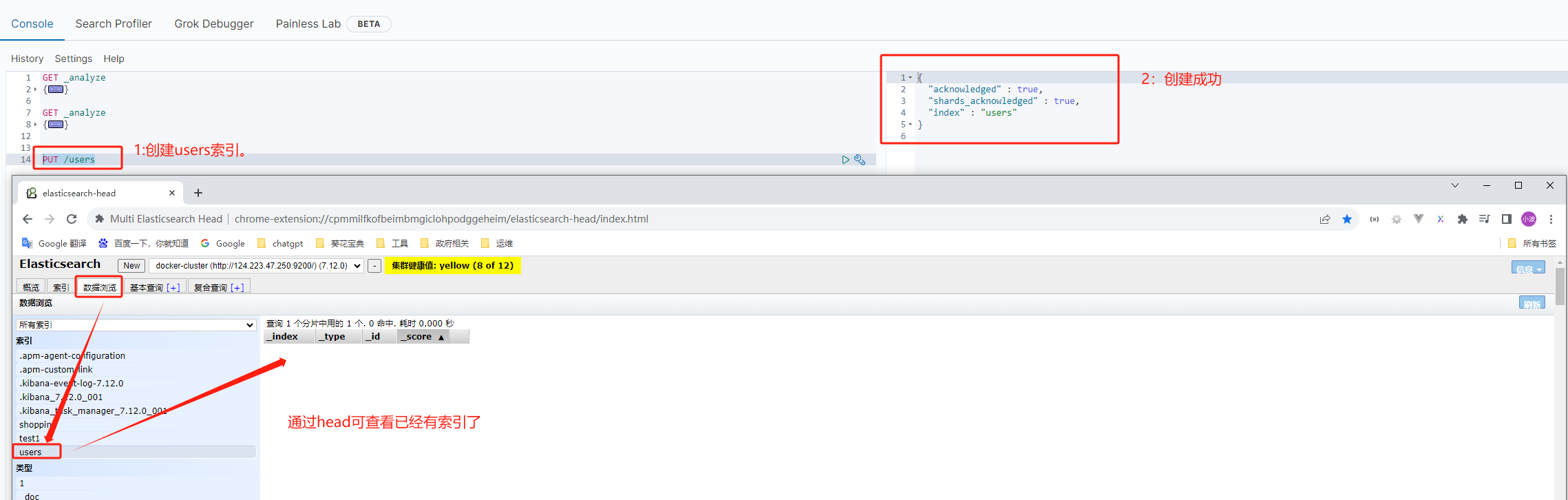
创建索引PUT是支持幂等的,再次创建则会报错。
查询索引信息
- 根据索引名称获取索引:
GET /users - 获取所有索引信息:
GET /_cat/indices?v
删除索引
这个有点删库跑路的意思了,不过无所谓,es的数据可以重做的。DELETE /users
文档
我们主要的是文档操作。当然文档操作主要的是查询,本章节会提下查询,至于详细查询则在下一章节。
创建文档
创建随机id的文档
POST /users/_doc { "id": 1, "name": "zhangsan", "age": 30, "category": "程序员", "info": "这是一个匿名的首选,任劳任怨,优秀的代号,张三同学。" }非幂等性的,es会随机生成一个id,重复提交都会返回不同的id。虽然这个通过这个id获取数据,但比较麻烦,因为和我们的真实数据地方不好关联上,所以一般情况下不会通过这个创建文档。
创建指定id文档
一般来说,有如下几种方式,任君选择
# 指定id,多次返回id一样。也是幂等操作,id存在则更新,不存在则创建 POST /users/_doc/7 { "id": 1, "name": "zhangsan", "age": 31, "category": "程序员", "info": "这是一个匿名的首选,任劳任怨,优秀的代号,张三同学。" } # 支持幂等,可重复调用,id存在则更新,不存在则创建 PUT /users/_doc/6 { "id": 2, "name": "lisi", "age": 33, "category": "程序员", "info": "这是一个匿名的次选,仅次于zhangsan,也是一个优秀的代号,李四同学。" } # 指明的说要创建,只能创建一次,如果这个id存在,再次调用则报错。 PUT /users/_create/4 { "id": 3, "name": "wangwu", "age": 32, "category": "测试工程师", "info": "王五同学,和大刀王五同名,三个匿名必有其一位。" }
查询文档
通过id来查询,类似于主键查询。
GET /users/_doc/1注意的是,如果id不存在,则返回中的found为false
查询索引下全部的数据,类似于select * 了.
GET /users/_search,这个查询有点耗时了。不建议这么干,当然在实际中也不会这么干,没啥意义。
更新文档
全量修改
全量修改数据完全覆盖,一般用的不多,我们更新都是更新局部的数据,有一些比如id的数据是不会变的,全量修改其实我们上面创建的时候,也用到过。
PUT /users/_doc/2 { "id": 2, "name": "lisi2", "age": 33, "category": "程序员", "info": "这是一个匿名的次选,仅次于zhangsan,也是一个优秀的代号,李四同学。" }局部更新
参数中明确告知为更新,且在doc中指明修改的属性。参数中如果是doc,可能会新增。
POST /users/_update/2 { "doc":{ "name": "lisi3" } }如果id不存在,则会报错
删除文档
不支持幂等,重复请求,则会标明 not_found,因为没有删除的数据
DELETE /users/_doc/YXFzX4sB6hrbgWqiCyCZ
查询相关
我们使用es,主要就是为了查询相关,所以本文列举了大量的例子,绝大部分都是在工作中需要用到的。 使用最基础的查询,先抛砖引玉吧。
查询类别为测试的所有记录
GET /users/_search?q=category:测试
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.7076306,
"hits" : [
{
"_index" : "users",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.7076306,
"_source" : {
"id" : 3,
"name" : "wangwu",
"age" : 32,
"category" : "测试工程师",
"info" : "王五同学,和大刀王五同名,三个匿名必有其一位。"
}
}
]
}
}
这样明显是不行的,哪有把信息放到url中,所以我们要封装
把参数放入请求体中
GET /users/_search { "query":{ "match":{ "category": "测试" } } }和上面的例子效果一样。但如果我想查询全部的数据呢?
查询全部数据
GET /users/_search { "query":{ "match_all":{ } } }如果数据量太大的话,一次性查询全部的性能很低,所以我们要分页。
分页查询
GET /users/_search { "query":{ "match_all":{ } }, "from": 0, "size": 2 }- from从哪里开始,size表示每页查询多少数据。
- 如果查询第二页,则from公式为:(页码-1) * 每页数据条数 ,mysql也是一样的
这样相当于字段是全部的,如果想要固定某些字段呢?不想要select *
指定查看字段,比如name、age
GET /users/_search { "query":{ "match_all":{ } }, "from": 2, "size": 2, "_source" : ["name","age"] }- 在_source中指明要查询的字段名
如果查询完后,需要排序咋整?比如按照年龄排序
根据字段排序,如年龄倒序
GET /users/_search { "query":{ "match_all":{ } }, "from": 0, "size": 10, "_source" : ["name","age"], "sort":{ "age":{ "order":"desc" } } }- 在sort标签中,填上字段名和order的规则,和mysql一样
同时查询多个条件,比如类型为程序员,info为zhangsan的,类似sql的 where and
GET /users/_search { "query":{ "bool":{ "must":[ { "match": { "category": "程序员" } }, { "match": { "info": "zhangsan" } } ] } } }- 使用must标签,然后在里面使用match,指明字段和value
如果是或者呢?类似where or
并集查询多个条件,or,如类型为程序员,info为优秀的
GET /users/_search { "query":{ "bool":{ "should":[ { "match": { "category": "程序员" } }, { "match": { "info": "优秀" } } ] } } }范围查询,比如age大于31的
GET /users/_search { "query":{ "bool":{ "filter":[ { "range": { "age": { "gt":31 } } } ] } } }- gt: > 大于(greater than)
- lt: < 小于(less than)
- gte: >= 大于或等于(greater than or equal to)
- lte: <= 小于或等于(less than or equal to)
那如果等于呢?等于就不是范围查询了,就不是range了
精确查询,age等于31的
GET /users/_search { "query":{ "bool":{ "must": [{ "term": { "age": "31" } }] } } }全文匹配,如类型为程序员
GET /users/_search { "query":{ "match":{ "category": "程序员" } } }由于ik分词器查询,程序员的话会把测试工程师也查出来的。
如果想完全匹配呢?就是不想测试工程师也出来?精确匹配
GET /users/_search { "query":{ "match_phrase":{ "category": "程序员" } } }高亮查询,如百度的时候,会把关键字和类关键字高亮
GET /users/_search { "query":{ "match_phrase":{ "category": "序员" } }, "highlight": { "fields": { "category": {} } } }其实就是在结果后面增加css语法,前端拿着直接显示即可
{ "_index" : "users", "_type" : "_doc", "_id" : "1", "_score" : 1.0155436, "_source" : { "id" : 1, "name" : "zhangsan", "age" : 31, "category" : "程序员", "info" : "这是一个匿名的首选,任劳任怨,优秀的代号,张三同学。" }, "highlight" : { "category" : [ "程<em>序</em><em>员</em>" ] }聚合统计,把结果进行统计分析
GET /users/_search { "aggs":{ "age_group":{ "terms": { "field": "age" } } }, "size":0 }- aggs 聚合操作
- category_group 自定义起名
- terms 分组的关键字
- field 分组字段
- size :0表示不查找原始数据,只需要统计的数据
结果如下:
"aggregations" : { "age_group" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : 31, "doc_count" : 1 }, { "key" : 32, "doc_count" : 1 }, { "key" : 33, "doc_count" : 1 } ] }求平均值,如年龄的平均值
GET /users/_search { "aggs":{ "age_avg":{ "avg": { "field": "age" } } }, "size":0 }查看mapping
GET /users/_mapping{ "users" : { "mappings" : { "properties" : { "age" : { "type" : "long" }, "category" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "id" : { "type" : "long" }, "info" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "name" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } } }
最后
如需了解go语言操作es,可移步go语言操作es

