
在当前分布式架构中,我们经常面临并发、并行处理数据的需求,这就涉及到临界资源访问的时候,进行非幂等性的修改、读写操作,就会对一致性造成破坏。
分布式锁
背景
为什么需要分布式锁?
我们来看看不加锁的情况下,并发计数会发生什么情况:
func main() {
var count int
var wg sync.WaitGroup
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
count++
wg.Done()
}()
}
wg.Wait()
fmt.Println(count)
}
PS E:\workspaces\goland\study_demo> go run main.go
984
PS E:\workspaces\goland\study_demo> go run main.go
996
PS E:\workspaces\goland\study_demo> go run main.go
986
很明显,并非正常的统计计数次数,因为我们循环了1000次。 那么加锁之后呢?
func main() {
var count int
var wg sync.WaitGroup
var l sync.Mutex
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
l.Lock()
count++
l.Unlock()
wg.Done()
}()
}
wg.Wait()
fmt.Println(count)
}
PS E:\workspaces\goland\study_demo> go run main.go
1000
很明显,可以得出正确的结果了。
分布式锁机制,多并发、并行下,处理临界值的时候,增加一道关卡,在真正访问临界值的时候,由一种混乱的访问模式变为有秩序的串行访问模式。当然,这不管是单机还是分布式锁,都是要解决这个问题。
只不过,分布式锁,是在分布式场景中,触发的场景式来自多个物理节点,所以我们就需要依赖类似于redis、mysql这样的状态存储组件,来标记锁的状态,是释放了,还是占用了等等状态,或者是zookeeper、etcd等等第三方服务来实现,在此基础上实现所谓的“分布式锁”技术。
相对于分布式,单机锁相对简单点,单机锁一般是同一个进程内的并发线程、goroutine中去建立一个锁的契约机制。
核心性质
分布式锁应当具备如下几个核心的机制:
- 独占性:之所以为锁,它的核心特征就是在同一时刻,同一把锁只能被一个取锁方占用。这也是最基础的一个性质。
- 健壮性:可能在分布式场景中,或者单机也是一样,不能出现死锁(这个名称听起来就毛骨悚然),也就是某个占有锁的使用方因为宕机而无法主动执行解锁动作,锁也应该能够正常被正常传承下去,被其他使用方延续使用。而不是陷入长久的,毫无希望的等待中。
- 对称性:非常关键,也就是和锁交互的时候,加锁和解锁的使用方应该是同一个身份,A加的锁,只能A来解锁,不允许B非法释放他人持有的分布式锁。
- 高可用:延伸的性质,既然是分布式的,那对于可用性是比较敏感的,所以对于分布式锁的服务的基础组件中如果出现少量节点发生故障,不应该影响到分布式锁服务的稳定性。
实现模式
正常来说,分布式锁有两种类型,就是主动轮询型和监听回调型。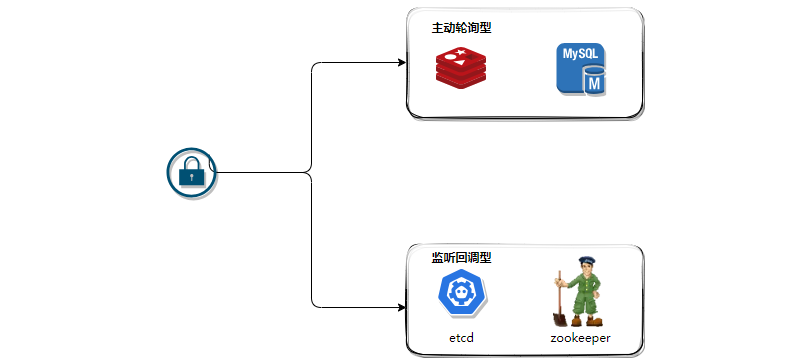
主动轮询型
该模式类似于单机锁中的主动轮询+cas乐观锁模式,取锁方会持续对分布式锁发出尝试获取动作,既然是尝试,那就是不断的去获取,如果锁已经被占用则不断发起重试,根据策略,时马上重试还是休眠时间,直到取锁成功为止。像不像非阻塞io。
监听回调型
该模式时取锁方先发起一轮尝试,当发现锁已经被他人占用时,会创建监听器订阅锁的释放事件,因为不知道什么时候释放,随后不再发起主动取锁的尝试,当锁被释放后,取锁方能通过之前创建的监听感知这一变化,然后在重新发起取锁的尝试动作。像不像epoll。
这两种实现模式,各有优劣,当然也是相对而言的,也就是没有最好的实现方案,只有更适合的实现方案。
不过在分布式场景中,监听回调型在实现策略上,会优于主动轮询型,因为在分布式场景中的轮询这个动作相比单机锁而言要高很多,背后不单单只是一次尝试取锁,可能涉及到网络IO等等。如果是采用监听回调的方式,在确保锁被释放,自身才有机会取锁的情况下,才会重新发出尝试取锁的请求,比较精准这样能在很大程度上避免无意义的轮询损耗。当然,这也是在并发比较激烈的情况下。
当然,主动轮询在并发比较轻的时候,使用他也会更加保证使用方始终占据流程的主动权,整个流程可以更加轻盈灵活,此外监听机制在实现过程中需要建立长链接完成监听动作,也会存在一定的资源损耗,而且更严重的是,当多个尝试取锁方监听同一把锁的时候,一旦锁被释放,那么所有监听锁的获取方全部一拥而上,导致一次锁的施放事件可能会引起"惊群效应",这可真是一时惊起千波浪,引起性能抖动,造成系统不稳定。
具体实现
主动轮询实现思路
我们以redis为例子吧,如下图:
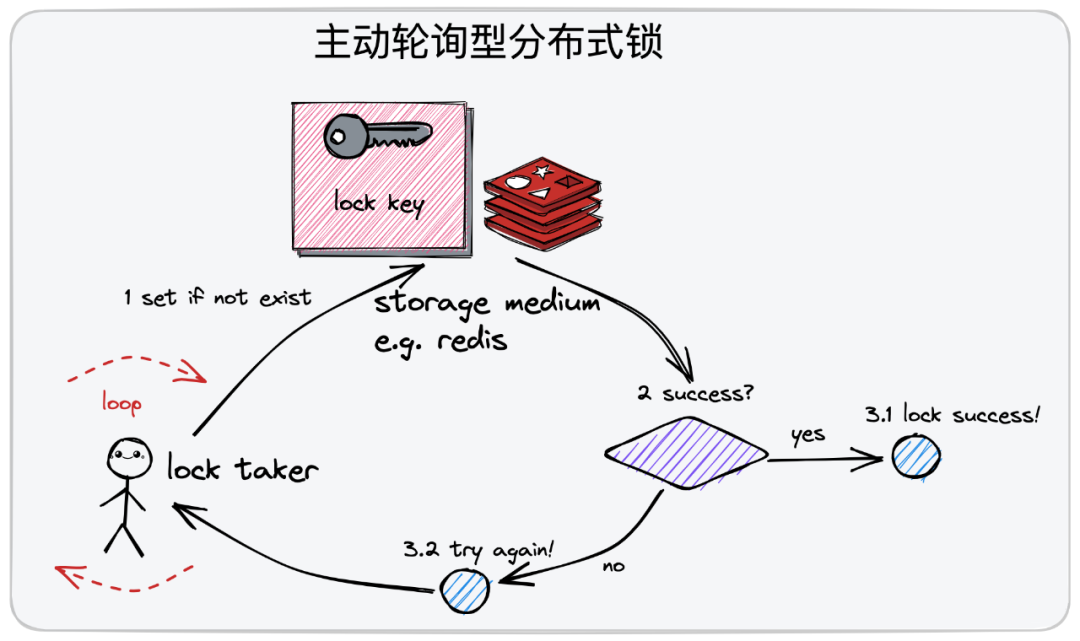
首先尝试取锁,建立一个自旋的主动轮询loop。可能会成功,也可能会失败,如果失败则通过自己轮询的机制去发起下一次新的尝试。在轮询的过程中,每一次发起一个尝试。
整个流程大概就是:执行一个 set if not exist操作,往redis中设置一组kv对,我们来约定,谁可以在里面设置成功了key,那么把这个完成这个动作的角色认定为它是加锁成功的这一方。如果你在设置kv键值对的时候发现这个key存在,则表明当前这把锁已经被占用了。当然,获取锁的这一方,在你处理完你的业务逻辑后,你有义务去把标识的这个kv键值对给删除掉。
当然,如果你set未成功,则表明这把锁已经被占用了,你继续发起下一轮的尝试吧。
再次阐述下主动轮询分布式锁的实现思路为:
- 针对同一把分布式锁,使用同一条数据进行标识,如使用同一个key对应的kv数据记录。
- 加入在存储介质中成功插入该条数据,也就是之前key对应的数据不存在,则被认定为加锁成功。
- 当然加锁成功后,在解锁的时候,需要删除这条数据。
- 如果在插入的时候,发现数据已经存在了,说明这把锁被他人持有了,则持续轮询,直到发现数据被他人删除,也就是释放锁了,你自己完成数据插入动作为止,表示你已经取锁成功了。
由于是并发场景,需要保证:
- 1:检查数据是否被插入
- 2:数据不存在则插入数据
这两个步骤之间应该是原子性的,不可拆分的,我们redis中是通过 set only if not exist SETNX操作来完成的。
主动轮询实现技术
一般来说,主动轮询分布式锁,我们常用的组件为 redis和mysql。下面我们逐步的讲解下两个方式的具体实现吧。
redis
实现轮询,redis应该是最常用的主键了,因为redis基于内存实现数据的存储,足够高轻便高效,且redis基于单线程模型完成数据处理工作,支持 setnx 原子指令,能够很轻便的支持分布式锁的加锁操作。使用文档 redis setnx 文档
当然,官方在2.6.12版本已经弃用了,建议使用 set 后面跟上 NX来表示

刚刚聊过,分布式需要有加锁和解锁的对称性,那么解锁该如何操作呢?
我们可以这样,key作为加锁的标识,value可以作为当前节点的唯一标识码来存储,后续解锁的时候,需要检查当前的kv对中的value是否是当前使用方本身的唯一标识。 如果不是,则是非法的使用方。
所以解锁也分为了两步骤,一个是校验当前锁是否属于你,一个是属于自己,则删除记录,完成解锁的语义。这两个动作也应该是原子化的,不能拆分的,我们可以使用redis当中提供的能力,就是使用lua脚本自定义组装同一个redis节点下的多笔操作具备原子性的一个事务。
mysql
当然,通过经典的关系型数据库 mysql也能实现redis类似的效果
- 先建立一张存储分布式锁记录的数据表,是一个很明确的用途。
- 以分布式锁的标识键作为表中的唯一键,类似redis中的key。也就是具有互斥的,不会有相同的两个数据同时插入到表中。
- 基于唯一键的特性,同一把锁只能被插入一条数据,会被mysql表的唯一键锁拦截报错,因此也就只能由一个使用方持有锁。
- 当然也需要增加一列表示锁持有方的身份,用于解锁。完整的解锁动作可以基于mysql事务保证原子性
当然,解锁也是两步,第一检查释放锁动作的身份。第二身份合法才进行解锁。
所以,分布式锁的对称性质得到保证。
主动轮询问题
死锁问题
如何避免死锁导致分布式锁不可用,是一个值得探讨的问题。
如果你已经获得锁了,但是在处理业务中出现了问题,导致锁迟迟不能释放,又占着茅坑不拉屎,这就陷入了死锁了。我们刚刚上面讨论的redis和mysql,为啥redis使用广泛?因为redis有过期机制,而mysql就显得捉襟见肘了。
过期时间的设定,可以解决使用方因为异常原因导致的无法正常解锁,所对应的数据项也会在达到过期时间阈值后被自动删除,实现释放分布式锁的效果。
当然,我们设置过期时间,需要偏保守一点,远长于我们处理业务逻辑的时间,比如你设置1ms,那还玩个锤子,过期时间只是用于兜底。不是一个完美的方案,因为做不到精确性。因为设置过期时间,是一个经验值,不能精确的判断自己持有锁处理业务逻辑的实际耗时,因为偏保守,可能造成性能问题。
但是还有严重的问题一个问题,就是取得锁使用方,会有异常的问题,不是宕机,比如gc了,或者超时了等等,这个业务逻辑执行时间,超过了过期时间设置值,就会导致锁被提前释放,其他取锁方可能取锁成功,最终引起数据不一致的并发问题。
针对这个问题,在分布式锁工具 redisson中给出解决的方案 -- 看门狗策略,在锁的持有方未完成业务逻辑的处理时,会持续对分布式锁的过期阈值进行延期操作。
redis弱一致性问题
我们大部分都是采用redis来作为分布式锁机制,回顾下redis设计思路,为避免单点故障问题,redis会基于主从复制的方式实现数据备份,然后哨兵机制监听master节点,如果master发生故障,扶持slave节点上位,这块不明白的,可以移步 redis分布式缓存。 在CAP体系中,redis走的是AP路线,也就是保证了分区容错性和可用性,而不保证一致性。所以为了保证服务的吞吐性能,主从节点之间的数据同步是异步延迟进行的。
那么,有问题了,有一种场景,就是使用方 张三 在redis master节点加锁成功,但是对应的kv记录在同步slave之前,此时redis master节点挂掉了,未同步的slave上位,这样分布式锁 张三 就凭空消失了,于是不知情的 李四 、王五 、马六 都有可能加锁成功,这也就出现了一把锁被多方同时持有的问题,导致分布式锁最基本的独占性被破坏掉了。
这个问题,我们可能是不能接受的,因为基本的都保证不了了,也有一个经典的解决方案,就是:redis的红锁 redlock。 博主也只是了解。 不展开了。
show code
redis
当然,有很多redis实现分布式锁的框架,比如 redigo 。 用于和redis组件进行交互。
当然,也有大神小徐先生,自己在基于redigo基础上面再次封装。 redis_lock
我们主要基于 redis_lock进行学习。
package redis_lock
import (
"context"
"errors"
"time"
"github.com/gomodule/redigo/redis"
)
// Client Redis 客户端.
type Client struct {
ClientOptions
pool *redis.Pool
}
func NewClient(network, address, password string, opts ...ClientOption) *Client {
c := Client{
ClientOptions: ClientOptions{
network: network,
address: address,
password: password,
},
}
for _, opt := range opts {
opt(&c.ClientOptions)
}
repairClient(&c.ClientOptions)
pool := c.getRedisPool()
return &Client{
pool: pool,
}
}
func (c *Client) getRedisPool() *redis.Pool {
return &redis.Pool{
MaxIdle: c.maxIdle,
IdleTimeout: time.Duration(c.idleTimeoutSeconds) * time.Second,
Dial: func() (redis.Conn, error) {
c, err := c.getRedisConn()
if err != nil {
return nil, err
}
return c, nil
},
MaxActive: c.maxActive,
Wait: c.wait,
TestOnBorrow: func(c redis.Conn, t time.Time) error {
_, err := c.Do("PING")
return err
},
}
}
func (c *Client) getRedisConn() (redis.Conn, error) {
if c.address == "" {
panic("Cannot get redis address from config")
}
var dialOpts []redis.DialOption
if len(c.password) > 0 {
dialOpts = append(dialOpts, redis.DialPassword(c.password))
}
conn, err := redis.DialContext(context.Background(),
c.network, c.address, dialOpts...)
if err != nil {
return nil, err
}
return conn, nil
}
func (c *Client) GetConn(ctx context.Context) (redis.Conn, error) {
return c.pool.GetContext(ctx)
}
// 只有 key 不存在时,能够 set 成功. set 时携带上超时时间,单位秒.
func (c *Client) SetNEX(ctx context.Context, key, value string, expireSeconds int64) (int64, error) {
if key == "" || value == "" {
return -1, errors.New("redis SET keyNX or value can't be empty")
}
conn, err := c.pool.GetContext(ctx)
if err != nil {
return -1, err
}
defer conn.Close()
reply, err := conn.Do("SET", key, value, "EX", expireSeconds, "NX") // redis 高版本建议使用 SET 带上时间 带上EX的方式
if err != nil {
return -1, nil
}
r, _ := reply.(int64)
return r, nil
}
// Eval 支持使用 lua 脚本.
func (c *Client) Eval(ctx context.Context, src string, keyCount int, keysAndArgs []interface{}) (interface{}, error) {
args := make([]interface{}, 2+len(keysAndArgs))
args[0] = src
args[1] = keyCount
copy(args[2:], keysAndArgs)
conn, err := c.pool.GetContext(ctx)
if err != nil {
return -1, err
}
defer conn.Close()
return conn.Do("EVAL", args...)
}
- 主要是SetNEX方法,语义就是set with expire time only if key not exist。用于支持分布式锁的加锁操作。
- Eval 是支持lua脚本的方法,用来支持分布式锁的解锁操作
由此看来,作者是将这加锁、解锁两个步骤弄成原子性,组装成事务了。
监听回调型
之前探讨过监听回调和轮询的区别,下面介绍下监听回调的具体实现方式,假设我们采用的是ETCD方式作为事件回调机制,首先我们看看流程图:
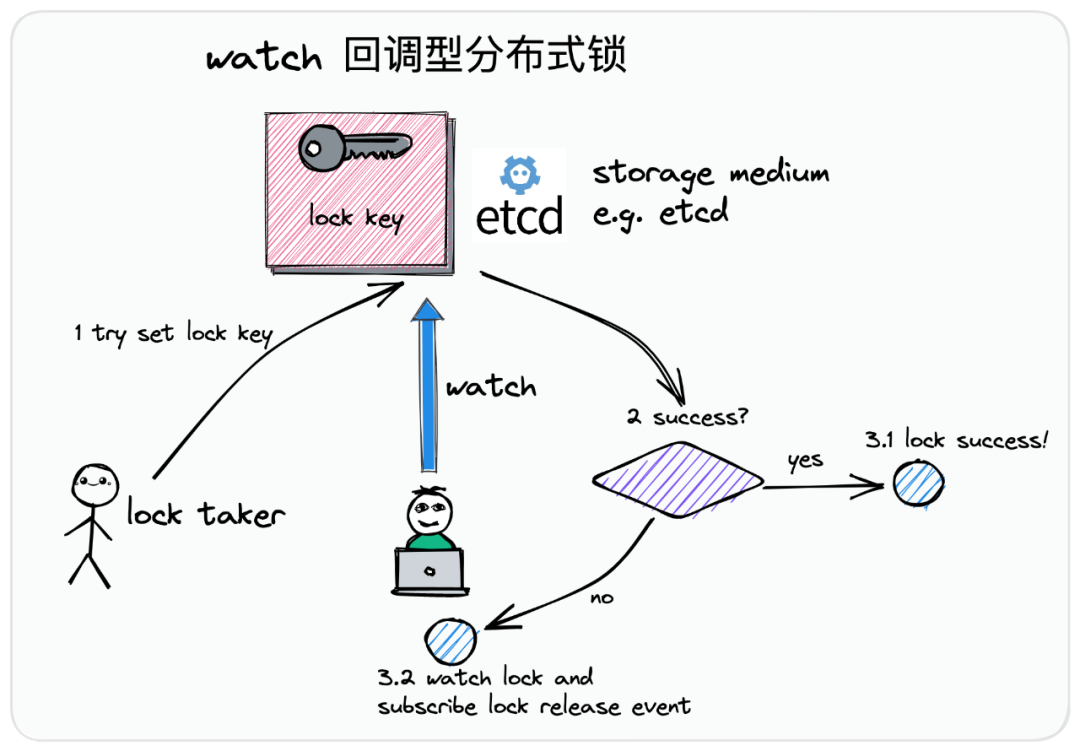
如上图,上述是一个尝试取锁的一个使用方:
- 1:尝试把代表标识锁的记录,插入到etcd之中。
- 2:如果插入成功,就表示已经取锁成功了,这时候你去做你的业务逻辑吧,
- 3.1 插入成功
- 3.2 如果插入失败了,和主动不同了,它会建立一个监听机制,去监听之前的锁的kv数据,监听删除或者释放的一个事件,也不会去发起取锁的一个动作了。
直到,下图:
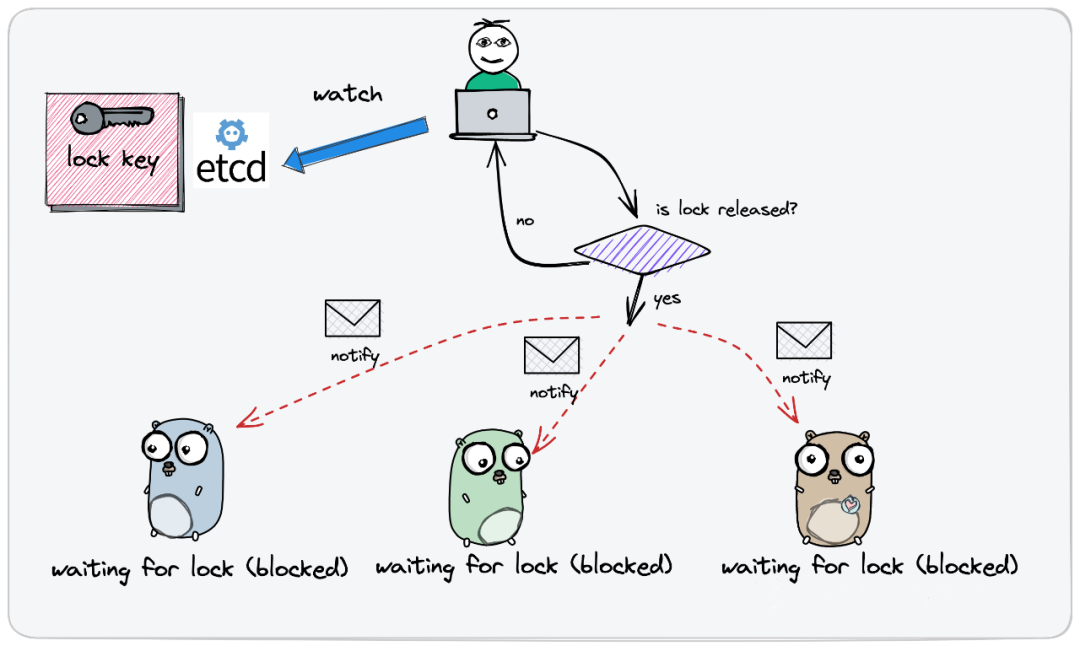
监听器收到锁删除或者释放的消息通知之后,我才会去发起新一轮的尝试。
整个流程再次描述下:
- 针对同一把分布式锁,使用一条相同的数据进行标识,但必须是唯一、明确的key。
- 如果存储介质内成功插入该条记录,当然要求key对应的数据是不存在的,那么这一行为被认定加锁成功,既然你加锁成功的话,你处理完你的业务逻辑后,有义务去表示释放或者删除你的锁。
- 是否或者删除锁,理解为解锁动作
与主动轮询方式不同的是,在取锁失败的时候,监听回调型分布式锁不会持续轮询,而是会监听锁的删除事件。
回调技术方案
实际上,我们需要依赖于提供监听机制的状态存储组件,不仅能够支持数据的存储和去重,还能利用其中的监听回调功能进行释放事件的订阅感知。
明显,mysql不具备,redis虽说有存储、也有发布订阅功能,但是是分开两个独立的功能,所以也不是最优解。 目前业界的有两个,一个是基于etcd,一个是基于zookeeper。下面我们介绍。
基于etcd
etcd官方文档 :是一款适合于共享配置和服务发现的分布式kv存储组件,底层基于分布式共识算法 raft 协议保证了存储服务的强一致性和高可用。
在etcd中,提供了watch监听器的功能,可以针对指定范围的数据,而不是某一条,通过与etcd服务端节点创建grpc长连接的方式持续监听变更事件。而且还支持通过版本机制进行取锁秩序的统筹协调,是很适合于分布式锁的组件。也支持续约的方式,来更好的提供分布式锁的支持。
基于 zookeeper
zk官方文档 : 是一款开源的分布式应用协调服务,底层基于分布式共识算法zab协议保证了数据的强一致性和高可用性。 熟悉的 kafka 也是基于zk作为底层的实现。
zookeeper提供了临时顺序节点类型和watch监听机制,满足watch回调分布式锁需要具备的一切核心能力,也有力的解决我们之前提到的惊群效应。
死锁问题
分布式死锁问题,指的是取锁方由于某些异常问题,导致它加上了锁,但是没有能力去释放锁,这样数据一直存在,而其他待取锁方没办法正常的取锁。
我们看看 etcd是如何解决死锁问题的,如下图:
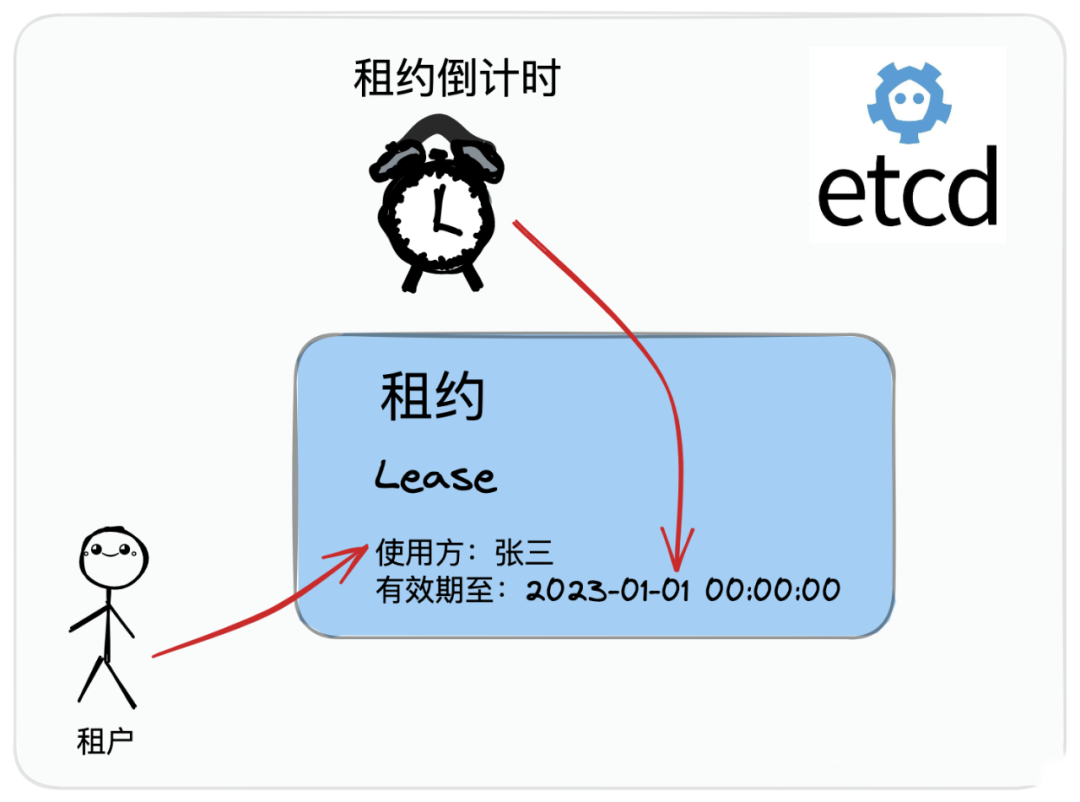
etcd提供了一个租约的机制,既然是租约,就是租的,并不是一直拥有,就好像你租的房子,到期没缴纳房租,房东立马赶你一样,是有一定规则的,有到期时间,也有当前的使用方,也就是租户。
那我到期了,业务还没处理完成怎办?ok,看下图,有续约机制。
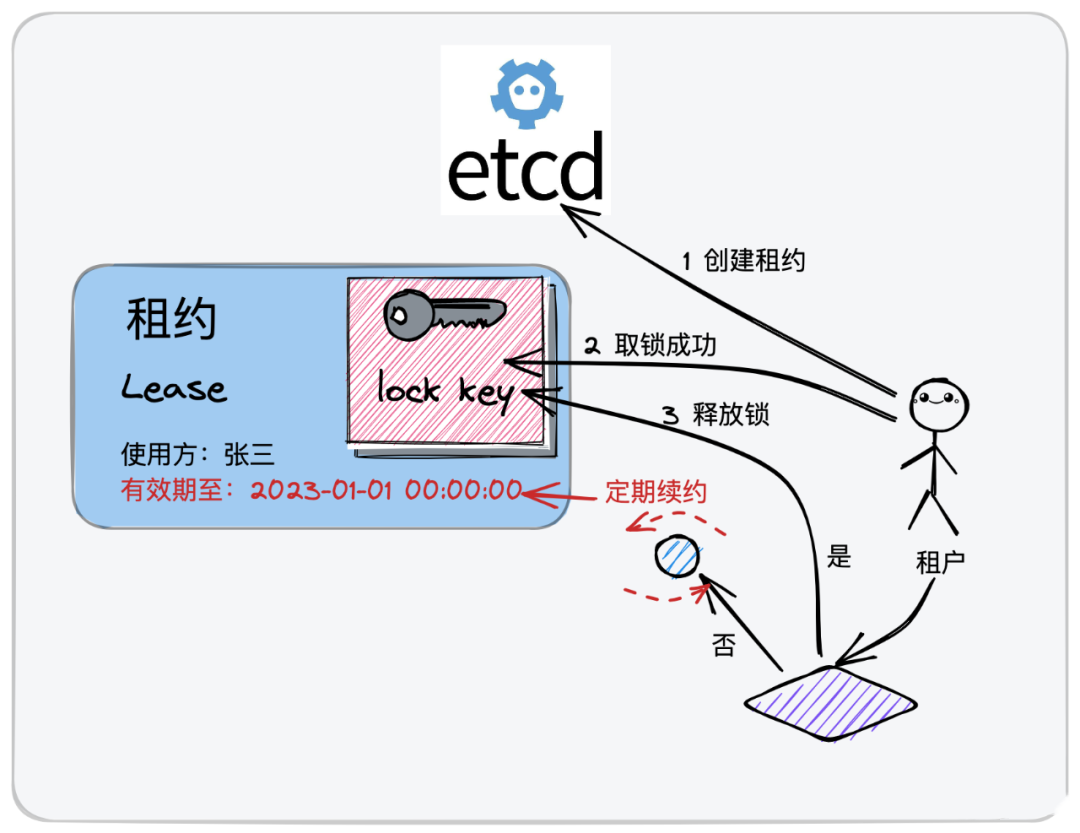
租户取锁成功后,在规定时间内完成了业务逻辑,需要释放锁。租户在一定时间内没有完成,可以继续续约,延长有效期。
- 用户可以先申请一份租约,设定好截止时间,可以偏短一点,乐观一点。
- 取锁方异步启动一个续约协程,用于在业务逻辑处理完成前,按照一定的时间节奏进行续约操作。核心的定位保驾护航,不会出现业务逻辑没处理完成就释放锁,后面一锁多持的现象。
- 在执行取锁动作,处理完你的业务逻辑之后,需要释放锁,删除续约协程。
这样的设定,规避了由于宕机而出现死锁的问题,也避免了一锁多持的现象。
总结下:所以为了避免死锁问题,etcd提供了租约机制,是一份具有时效性的协议,一旦达到租约上规定的截止时间,租约就会失去效力,同时etcd还提供了续约机制,用户可以通过续约操作来延迟租约的过期时间。这是一个很关键的能力。
但是,有一个问题,就是待取锁方同时监听了一把锁,该锁释放之后,会引起多方抢锁,引起惊群现象。因为
惊群效应
又称为羊群效应,羊这玩意是一种纪律性差的动物,平时处于散漫无次序的移动模式,一旦有一只羊出现异动,其他羊不假思索的一哄而上。
在我们监听回调分布式锁的模式下,也会存在这个问题。我们如何解决呢?
etcd中提供了 prefix 机制,以及版本 version 机制 来规避这个问题。
流程如下图:
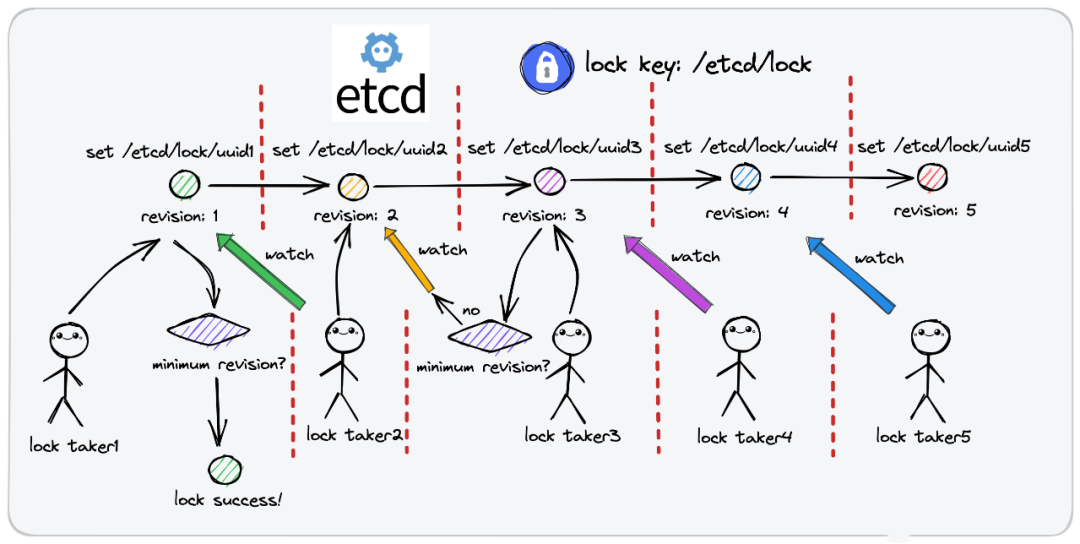
如上图,总共有5个客户,想取得同一把分布式锁,但是分布式锁的key是有一定规则的。根据prefix机制和version机制和你的租户id来命名的。
- 对于同一把分布式锁,所记录数据的可以是有共同的前缀perfix,他们属于同一个分布式锁,作为锁的标识,而不是key。 比如/etc/lock
- 每个取锁方,再在锁前缀的基础上,拼接自身的标识,就是你的身份证id,生成一个完整的lock key,比如/etc/lock/uuid1,所以各取锁方的完整lock key都是不一样的,只是有着相同的前缀,理论上所有取锁方都能够成功的把锁记录插到etcd中。因为前缀一样,但是uuid各不相同的,所以尝试插入,都是可以成功的,那到底是谁加锁成功了呢?别急。
- 每个取锁方把自己的kv对插入的过程中,它会获得一个版本号,它是一个公共前缀 perfix 下的唯一且递增的版本号,比如 /etc/lock/uuid1 版本好就是 1,/etc/lock/uuid2版本号就是2。
- 取锁方拆入加锁记录,并不意味着你就加锁成功了,因为你本身就是一个唯一的key,而是需要再插入数据后,查询一次锁前缀prefix下的记录列表,判断你的自身lock key对应的version是不是其中最小的,如果是的话,才表示加锁成功,因为你排队排第一,你不获取谁获取?
- 当然,如果锁被其他人占用了,取锁方会监听version小于自己,但是最接近自己的那个lock key的删除事件,比如taker3是监听taker2,taker2监听taker1,因为所有都是根据顺序来的,taker3监听taker1没有意义,因为taker1释放了,也不会到你。
就这样,所有的取锁方会在版本机制下协调,根据取锁序号的先后顺序排成一个有顺序的队列,每当锁被释放了,只会惊到下一顺位的取锁方。而不会引起羊群效应。
只能说,这样的设计,真特么的妙。
etcd源码走读
code is cheap show me talking,哦,不对,是talking is cheap show me code。
以上是大概流程分析,接下来我们更为细致的源码走读。 etcd 开源地址。
我们先大致的分析一下整个源码结构下的流程:
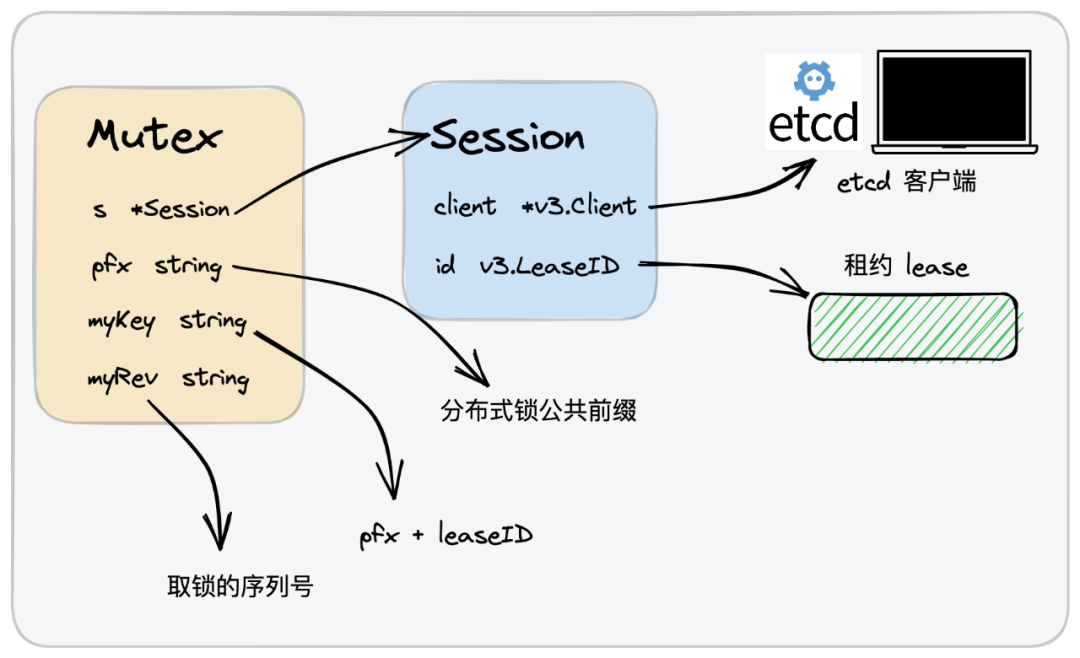
我们主要的结构体就是Mutex,其中:
- Session 就是一次访问中,建立一个租约的机制,包含了用户信息 etcd的 Client和一个租户的id,这个id如果为空,etcd会生成。
- pfx 就是一个分布式锁的公共前缀,不同的使用方使用相同的前缀,则表示竞争同一把锁。
- myKey 表示一个完整的key,也就是前缀+租户ID。
- myRev 表示一个取锁的序列号,也就是排队号。
session
const defaultSessionTTL = 60
// Session represents a lease kept alive for the lifetime of a client.
// Fault-tolerant applications may use sessions to reason about liveness.
type Session struct {
client *v3.Client
opts *sessionOptions
id v3.LeaseID
cancel context.CancelFunc
donec <-chan struct{}
}
// NewSession gets the leased session for a client.
func NewSession(client *v3.Client, opts ...SessionOption) (*Session, error) {
lg := client.GetLogger()
ops := &sessionOptions{ttl: defaultSessionTTL, ctx: client.Ctx()}
for _, opt := range opts {
opt(ops, lg)
}
id := ops.leaseID
// 如果你的id为0,没有指定你的租约id
if id == v3.NoLease {
resp, err := client.Grant(ops.ctx, int64(ops.ttl)) // 则从etcd服务中获取一个随机的租户id
if err != nil {
return nil, err
}
id = resp.ID
}
ctx, cancel := context.WithCancel(ops.ctx)
keepAlive, err := client.KeepAlive(ctx, id) // 注入Context,或许来关闭流程
if err != nil || keepAlive == nil {
cancel()
return nil, err
}
donec := make(chan struct{})
s := &Session{client: client, opts: ops, id: id, cancel: cancel, donec: donec}
// keep the lease alive until client error or cancelled context
// 异步的启动一个goroutine,进行一个续约的操作流程
go func() {
defer close(donec)
for range keepAlive {
// eat messages until keep alive channel closes
}
}()
return s,nil
}
所以,在我们完成工作后,这个续约的流程需要进行关闭,如何关闭呢?
// Close orphans the session and revokes the session lease.
func (s *Session) Close() error {
s.Orphan()
// if revoke takes longer than the ttl, lease is expired anyway
ctx, cancel := context.WithTimeout(s.opts.ctx, time.Duration(s.opts.ttl)*time.Second)
_, err := s.client.Revoke(ctx, s.id)
cancel()
return err
}
// Orphan ends the refresh for the session lease. This is useful
// in case the state of the client connection is indeterminate (revoke
// would fail) or when transferring lease ownership.
func (s *Session) Orphan() {
s.cancel()
<-s.donec
}
可以看出,通过一个Context来进行关闭上下文。
Mutex
// Mutex implements the sync Locker interface with etcd
type Mutex struct {
s *Session // 内置一个会话的Session
pfx string // 分布式锁的公共前缀
myKey string // 当前锁使用方完整的lock key,由 pfx 和 lease id 两部分拼接而成
myRev int64 // 当前锁使用方 lock key 在公共锁前缀 pfx 下对应的版本 revision
hdr *pb.ResponseHeader
}
func NewMutex(s *Session, pfx string) *Mutex {
return &Mutex{s, pfx + "/", "", -1, nil}
}
之前我们有聊过这些核心的结构体字段。我们主要是看他的成员方法有哪些。
- TryLock:这个方法是尝试取锁的一个方法
func (m *Mutex) TryLock(ctx context.Context) error {
resp, err := m.tryAcquire(ctx) // 尝试插入my key,如果已经存在了就查询,获取my key对应的revision以及当前锁的实际持有者
if err != nil {
return err
}
// if no key on prefix / the minimum rev is key, already hold the lock
ownerKey := resp.Responses[1].GetResponseRange().Kvs
// 如果这个锁是自由态的,也就是还没有取锁方,或者是当前锁的持有者的最小的版本就和我的版本一样,意味着我是最小版本的取锁方,我就取锁。
if len(ownerKey) == 0 || ownerKey[0].CreateRevision == m.myRev {
m.hdr = resp.Header
return nil
}
client := m.s.Client()
// Cannot lock, so delete the key
// 这里表示插锁失败了,我需要删除我的kv对。 这是etcd在实现分布式锁的时候,你不但要插入kv对,而且要你的版本号是全局最小的才会加锁成功
// 你这是一个尝试动作,并非正式加锁,所以需要删除你的数据。
if _, err := client.Delete(ctx, m.myKey); err != nil {
return err
}
m.myKey = "\x00"
m.myRev = -1
return ErrLocked
}
- Lock方法,阻塞加锁,如果分布式锁被占用,则持续阻塞等待时机,直到取锁成功
func (m *Mutex) Lock(ctx context.Context) error {
resp, err := m.tryAcquire(ctx) // 获取一个resp,返回的是当前锁是谁持有,以及版本号。
if err != nil {
return err
}
// if no key on prefix / the minimum rev is key, already hold the lock
ownerKey := resp.Responses[1].GetResponseRange().Kvs
// 一样,如果当前锁没人持有,或者是版本号跟我的相同,那说明我就是持有者,这两个都返回成功。
if len(ownerKey) == 0 || ownerKey[0].CreateRevision == m.myRev {
m.hdr = resp.Header
return nil
}
// 后面都是加锁失败的
client := m.s.Client()
// wait for deletion revisions prior to myKey
// TODO: early termination if the session key is deleted before other session keys with smaller revisions.
_, werr := waitDeletes(ctx, client, m.pfx, m.myRev-1) // 这里是监听取锁,后面介绍,这里陷入阻塞了,除非获取锁成功了,就会唤醒,走后面的流程。
// release lock key if wait failed
// 唤醒了
if werr != nil {
m.Unlock(client.Ctx())
return werr
}
// make sure the session is not expired, and the owner key still exists.
gresp, werr := client.Get(ctx, m.myKey)
if werr != nil {
m.Unlock(client.Ctx())
return werr
}
// 唤醒后会再次做一些检查,比如租约是否过期等等
if len(gresp.Kvs) == 0 { // is the session key lost?
return ErrSessionExpired
}
m.hdr = gresp.Header
return nil
}
- tryAcquire 适用法完成锁数据的插入以及revision的获取
func (m *Mutex) tryAcquire(ctx context.Context) (*v3.TxnResponse, error) {
s := m.s
client := m.s.Client()
m.myKey = fmt.Sprintf("%s%x", m.pfx, s.Lease())
cmp := v3.Compare(v3.CreateRevision(m.myKey), "=", 0) // 这里保证当前的kv对是否插入到etcd中,如果插入了就不会再次插入了,只保存首次的插入数据。后面If中判断
// put self in lock waiters via myKey; oldest waiter holds lock
put := v3.OpPut(m.myKey, "", v3.WithLease(s.Lease()))
// reuse key in case this session already holds the lock
get := v3.OpGet(m.myKey)
// fetch current holder to complete uncontended path with only one RPC
getOwner := v3.OpGet(m.pfx, v3.WithFirstCreate()...)
// 这种写法很少见,是基于事务的方式,保持了原子性。
// If,判断之前kv对是否插入了。Then,表示之前没有插入,执行put操作,同时执行getOwner方法,把当前最小的版本kv对获取。
// Else表示已经插入了,那么取得我自己的kv对的结果,同时也执行getOwner方法,把当前最小的版本kv对获取。
// commit,进行提交事务。
resp, err := client.Txn(ctx).If(cmp).Then(put, getOwner).Else(get, getOwner).Commit()
if err != nil {
return nil, err
}
m.myRev = resp.Header.Revision
if !resp.Succeeded {
m.myRev = resp.Responses[0].GetResponseRange().Kvs[0].CreateRevision
}
return resp, nil
}
- waitDeletes 如果取锁方不是自己,则进入该方法进行等待。
// waitDeletes efficiently waits until all keys matching the prefix and no greater
// than the create revision are deleted.
func waitDeletes(ctx context.Context, client *v3.Client, pfx string, maxCreateRev int64) (*pb.ResponseHeader, error) {
getOpts := append(v3.WithLastCreate(), v3.WithMaxCreateRev(maxCreateRev)) // 拿到版本比自己小,且最接近自己的opts。
// 是一个循环阻塞的过程
for {
resp, err := client.Get(ctx, pfx, getOpts...)
if err != nil {
return nil, err
}
if len(resp.Kvs) == 0 {
// 先判断我是否是最小的kv对的持有者,如果是就表明我成功取锁,直接return,我已经取到锁了。
return resp.Header, nil
}
// 寻找当前版本号比我小且是最接近我自己的取锁的key,然后监听他
lastKey := string(resp.Kvs[0].Key)
// waitDelete 就是监听最接近我的取锁key,只需要监听它即可,这个是阻塞的。如果是我监听取锁方删除了,说明下一个就是我了,我就等待着就好了。
if err = waitDelete(ctx, client, lastKey, resp.Header.Revision); err != nil {
return nil, err
}
// 这里设计很牛逼:
// 走到这里,正常来说是上一个取锁方删除了,下一个就到我了,我是否直接返回就可以了?并不是。
// 1:有可能是正常的情况,我正常的取锁。
// 2:有可能是排队的过程中,有可能我自己的租约到期了,自己把自己删除了。也会走到这里。
// 所以,这里并没有返回,而且再次的进行for循环,继续走一遍我是否是最小的kv对持有者。
}
}
- waitDelete 监听最接近我的版本待取锁方
func waitDelete(ctx context.Context, client *v3.Client, key string, rev int64) error {
cctx, cancel := context.WithCancel(ctx) // 通过context的取消上线文的方式进行传入进去,如果取消了,就会唤醒我。
defer cancel()
var wr v3.WatchResponse
wch := client.Watch(cctx, key, v3.WithRev(rev)) // 监听的方式,etcd提供的,这个key是传入的,就是比我小,最接近我的key,监听它
for wr = range wch {
// 通过channel来监听,有变化了才会进来,不会空转。
for _, ev := range wr.Events {
// 监听删除事件,代表我前面的哥们返回了。
if ev.Type == mvccpb.DELETE {
return nil
}
}
}
if err := wr.Err(); err != nil {
return err
}
if err := ctx.Err(); err != nil {
return err
}
return errors.New("lost watcher waiting for delete")
}
- 最后,我们来说解锁 unlock
func (m *Mutex) Unlock(ctx context.Context) error {
if m.myKey == "" || m.myRev <= 0 || m.myKey == "\x00" {
return ErrLockReleased
}
if !strings.HasPrefix(m.myKey, m.pfx) {
return fmt.Errorf("invalid key %q, it should have prefix %q", m.myKey, m.pfx)
}
client := m.s.Client()
if _, err := client.Delete(ctx, m.myKey); err != nil {
return err
}
m.myKey = "\x00"
m.myRev = -1
return nil
这个就简单了,我直接删除就好了。
如何选择?
如果你的业务还在单体服务,体量较少的时候,按照需求使用任意的单机锁就可以了,如最开是demo。
如果你的架构发展到了分布式服务阶段了,但业务规模不是很大,qps较少的情况下,使用哪种方案都差不多,这个时候就看公司内是否有现成的组件,zk、etcd、redis集群,在不影响整体公司架构的情况下,选择一个你擅长的且稳定的组件来满足业务需求。
如果业务发展到一定量级了,就需要从各个维度去考虑,比如你的锁,是否在任何条件下都不允许丢失,不能超时,但还不能死锁,那么redis的方案可能就不太适用了。
对锁数据的可靠性要求极高,只能使用etcd或者zk这种通过一致性协议保证数据可靠性的锁方案,但是影响的可能是较低的吞吐量和较高的延迟,看看业务是否可以接受。
感谢
感谢b站博主,小徐先生,本文大量借助他的视频进行整理。

