
又到了数据库时代,本文数据库集群原理以及数据分片方案
当然,还是先来架构图。
MySQL复制
主从复制
复制,我们都知道,从一个地方拷贝对应文件到另外一个地方,称为副本。数据库复制那拷贝什么呢?
拷贝的是binlog,主从之间通过binlog进行数据同步,来达到数据库读写分离,从而使得数据库有更强大的访问负载能力,支撑更多的用户访问。
如下图,就是一个典型的一主一从数据拷贝流程图:
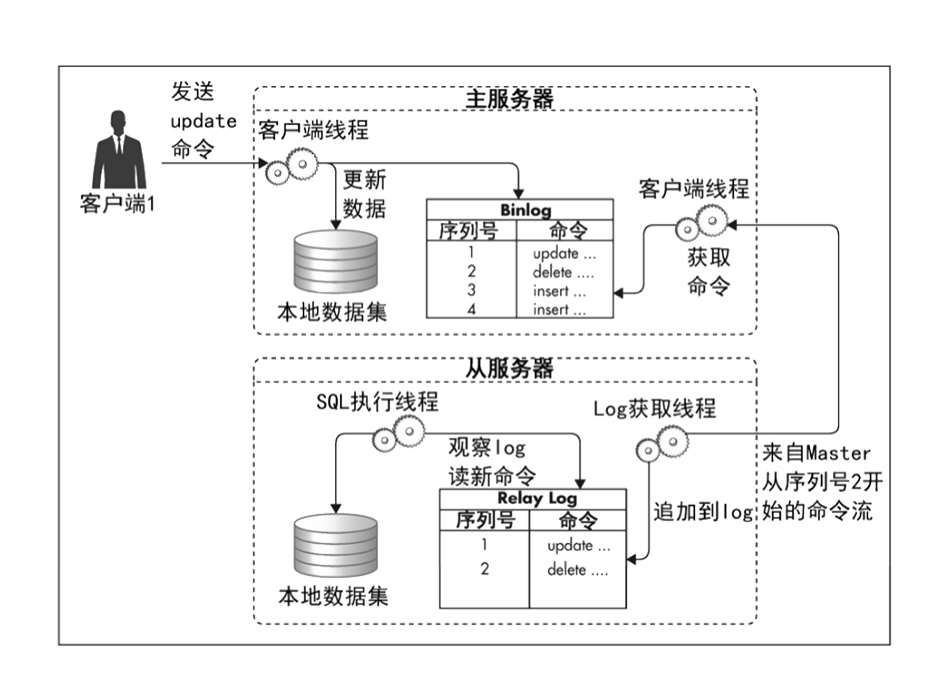
- 客户端发送update命令(insert、delete皆是如此),主服务器在更新本地数据集的同时,会把命令更新到binlog中。
- 从服务器有个线程,专门监听主服务器binlog变化,又变化后,该线程把数据同步到从服务器的relay log 中继日志中。
- 从服务器还有一个执行线程,从中继日志中读取命令,再更新到从库的本地数据集里面。相当于同步执行和主库一样的命令。
从而实现主库向从库的复制,让从库和主库的数据保持一样。
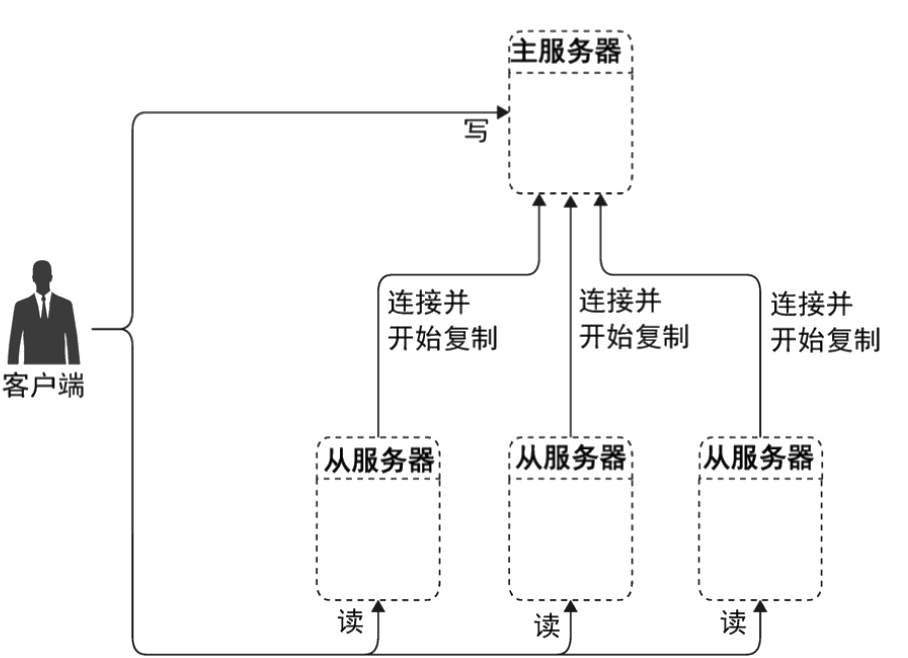
一主多从复制
和一主一从一样,每个从数据库都去监听主库的binlog变化信息,然后拷贝回来。
如下图所示,多个从数据库关联到主数据库后,将主数据库上的 Binlog 日志同步地复制到了多个从数据库上,通过执行日志,每个从数据库的数据都和主数据库上的数据保持了一致。这里面的数据更新操作表示的是所有数据库的更新操作,除了 SELECT 之类的查询读操作以外,其他的 INSERT、DELETE、UPDATE 这样的 DML 写操作,以及 CREATE TABLE、DROPT ABLE、ALTER TABLE 等 DDL 操作都可以同步复制到从数据库上去。
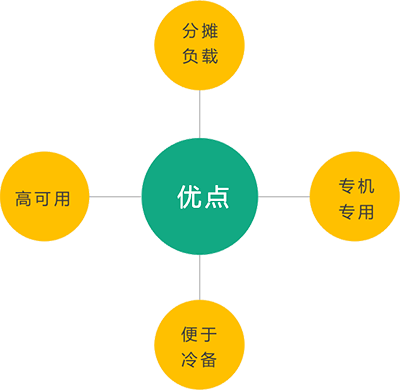
一主多从优点
优点很明显,就是:分摊负载、专机专用、便于冷备、高可用。
分摊负载
将只读操作分步在多个从库上面,从而将负载分摊到多台服务器中,一般来说,对数据库做主从复制的时候,都是为了进行读写分离,数据库的写操作链接到主库上面,读操作链接到从库上面,而我们大部分的数据库操作,都是读操作。读写分离就可以降低数据库的负载压力,减轻整个数据库的访问压力。
专机专用
可以针对不同类型的查询,使用不同的从服务器。比如有一台服务器专门用来做应用程序的读操作,另一个服务器专门用来执行数据报表类的操作,还有的服务器可能专门执行数据备份。通过这样的方式,将不同的操作连接到不同的从数据库上,从而实现了专机专用,也进一步改善了用户的体验。虽然这种情况不是很常见,但也是一个方案。
便于冷备
我们一般都会对数据进行备份,便于出现问题时候回滚,但是在dump数据的时候,会产生全表锁,如果直接对主库进行备份,那当前系统可能直接奔溃了。所以一般来说都会针对于某个从库进行全库备份。以前的做法是停机冷备,也就是停止数据库的写操作,将数据文件拷贝出去后,再重新打开数据访问。而现在使用一主多从的复制就就可以实现零停机时间的备份。只需要关闭数据的数据复制进程,文件就处于关闭状态了,然后进行数据文件拷贝,拷贝完成后再重新打开数据复制就可以了。
高可用
这个才是重点,一台服务器宕机了,只要不发请求给这台服务器就不会出问题。当这台服务器恢复的时候,再重新发请求到这台服务器。所以,在一主多从的情况下,某一台从服务器宕机不可用,对整个系统的影响是非常小的。
多主复制
一主一从下,如果主节点的宕机了,那所有的写操作都完蛋,所以在高并发高流量下,我们一般提倡多主复制,一主多从的架构进行高可用。
所谓的主主复制方案是指两台服务器都当作主服务器,任何一台服务器上收到的写操作都会复制到另一台服务器上。
如下图流程所示: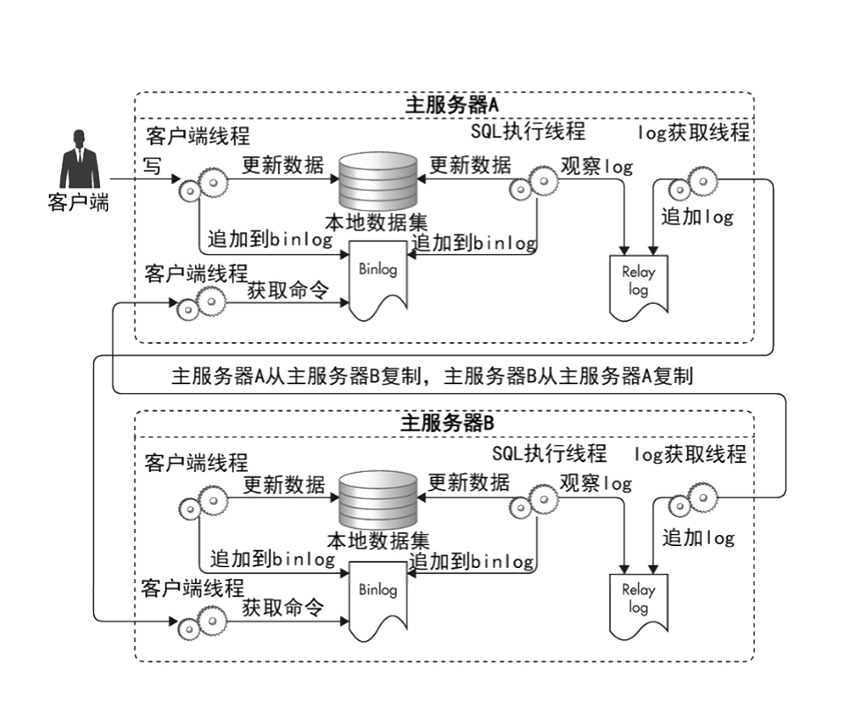
- 当客户端程序对主服务器 A 进行数据更新操作的时候,主服务器 A 会把更新操作写入到 Binlog 日志中
- 然后 Binlog 会将数据日志同步到主服务器 B,写入到主服务器B的 Relay log 中,然后执行 Relay log,获得 Relay log 中的更新日志,执行 SQL 操作写入到数据库服务器 B 的本地数据库中。
- B 服务器上的更新也同样通过 Binlog 复制到了服务器 A 的 Relay log 中,然后通过 Relay log 将数据更新到服务器 A 中
- 通过这种方式,服务器 A 或者 B 任何一台服务器收到了数据的写操作都会同步更新到另一台服务器,实现了数据库主主复制。
主主复制可以提高系统的写可用,实现写操作的高可用。
但有个问题,就是在多主复制架构下,数据库服务器突然失效了如何应对?
比如两台服务器A、B。某天A服务器由于某些不可抗拒原因宕机了。我们来看看流程图:
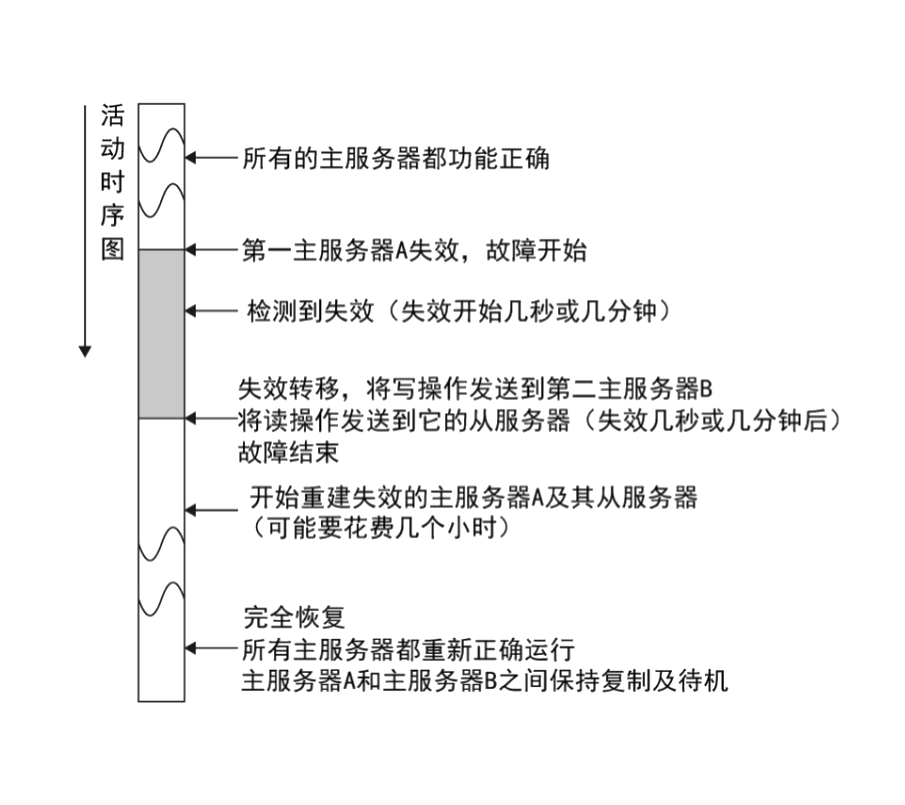
- 开始的时候所欲主服务器都是正常访问。
- 当服务器A失效,进入故障状态,应用程序检测到主服务器A失效,检测可能需要几秒或者几分钟。
- 应用程序需要进行失效转移,将写操作发送到另一主服务器B上面,读操作发送到B的从库上面。
- 程序员经过修复,A服务器恢复使用,A库需要重建数据,
重建就是把自己当做从服务器去B服务器上面同步数据。 - A 恢复后,此时还是备份服务器,B已经是第一主库服务器了。
注意事项
- 不要对两个数据库同时进行写操作,可能会导致数据冲突。
- 复制只是增加了数据的读并发处理能力,并没有增加写并发的能力和系统存储能力。
- 更新数据表的结构会导致巨大的同步延迟。
数据分片
以上是主从复制、多主复制,总体来说各主之间的数据都是一样的,并不能提高写的并发能力以及整个数据从存储能力。如果我们数据库的写操作压力很大,单一的服务器甚至一张表都无法存储,就需要进行数据分片了,也就是我们熟知的分库分表操作。
数据分片的主要目标是,将一张数据表切分成较小的片,不同的片存储到不同的服务器上面去,通过分片的方式使用多台服务器存储一张数据表,避免一台服务器记录存储处理整张数据表带来的存储及访问压力。
分片方案
分片目前来说,一般指的是分库分表,在下面又有两种方案,一种是垂直拆分,一种是水平拆分。
垂直拆分
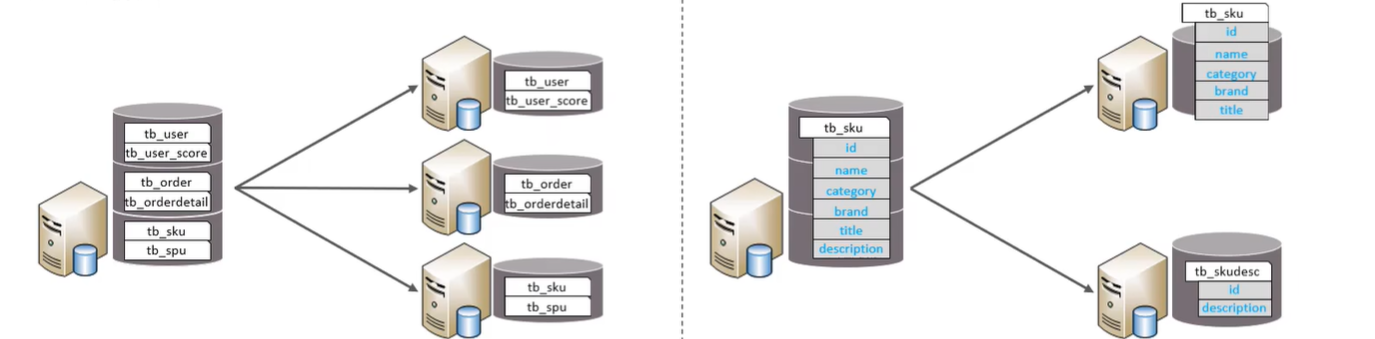
如上图左侧为垂直分库:按照业务的不同,将不同表拆分到不同的库中,比如把用户相关的拆分一个库,订单相关的拆分一个库,商品相关的拆分一个库。具有:
- 每个库的表结构都不一样
- 每个库的数据也不一样
- 所有库的并集是全量数据
上图右侧为垂直分表,就是以字段为依据,根据字段属性将不同字段拆分到不同表中,如把商品的主要信息放一张表,商品的附加信息放一张表,这两张表可以在一个库也可以在不同的库。具有:
- 每个表的结构都不一样
- 每个表的数据页不一样,一般通过一列关联
- 所有表的并集是全量数据
水平拆分
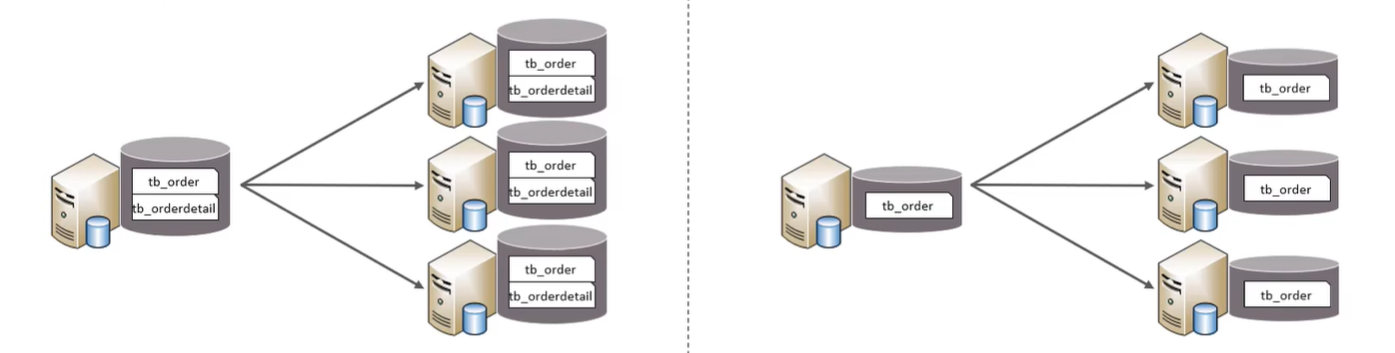
如上图左侧为水平分库:以字段为依据,按照一定的策略,将一个库的数据拆分到多个库中,比如可以按照年份,把去年的数据放一个库,今年的数据放一个库。具有:
- 每个库的表结构都一样
- 每个库的数据都不一样
- 所有库的并集是全量数据
如上图右侧为水平分表:以字段为依据,按照一定的策略将一个表的数据拆分到多个表中。比如可以按照id为1-1000w的数据放一个表,1000w到2000w的数据放一张表。具有:
- 每个表的表结构都一样
- 每个表的数据都不一样
- 所有表的并集是全量数据
那么问题来了。现在有多个库和多个表,我们的应用程序,该如何知道是访问哪个库哪个表呢?
别急,往下看。
当前下,一般有两个成熟的中间件可以解决:
shardingJDBC:基于AOP原理,在应用程序中对本地执行的SQL进行拦截,解析、改写、路由处理。需要自行编码配置实现,且只支持java语言,性能较高。我会php、go等等后端语言,java没弄过后端,所以门槛较高,后续再整理吧,下次一定。 MyCat:不用调整代码即可实现分库分表,支持多种语言,性能不及前者。哈哈,来吧。
分片扩容
直接使用mycat吧,往里面怼就好了,链接也是到mycat中,扩容后,组件会帮你维护,不用太关心底层原理了。如何使用看下面。
数据库部署方案
单一服务和单一数据库
最简单的就是单一服务和单一数据库。应用服务器可能有多个,但是它们完成的功能是单一的功能。多个完成单一功能的服务器,通过负载均衡对外提供服务。它们只连一台单一数据库服务器,这是应用系统早期用户量比较低的时候的一种架构方法,如下图所示。
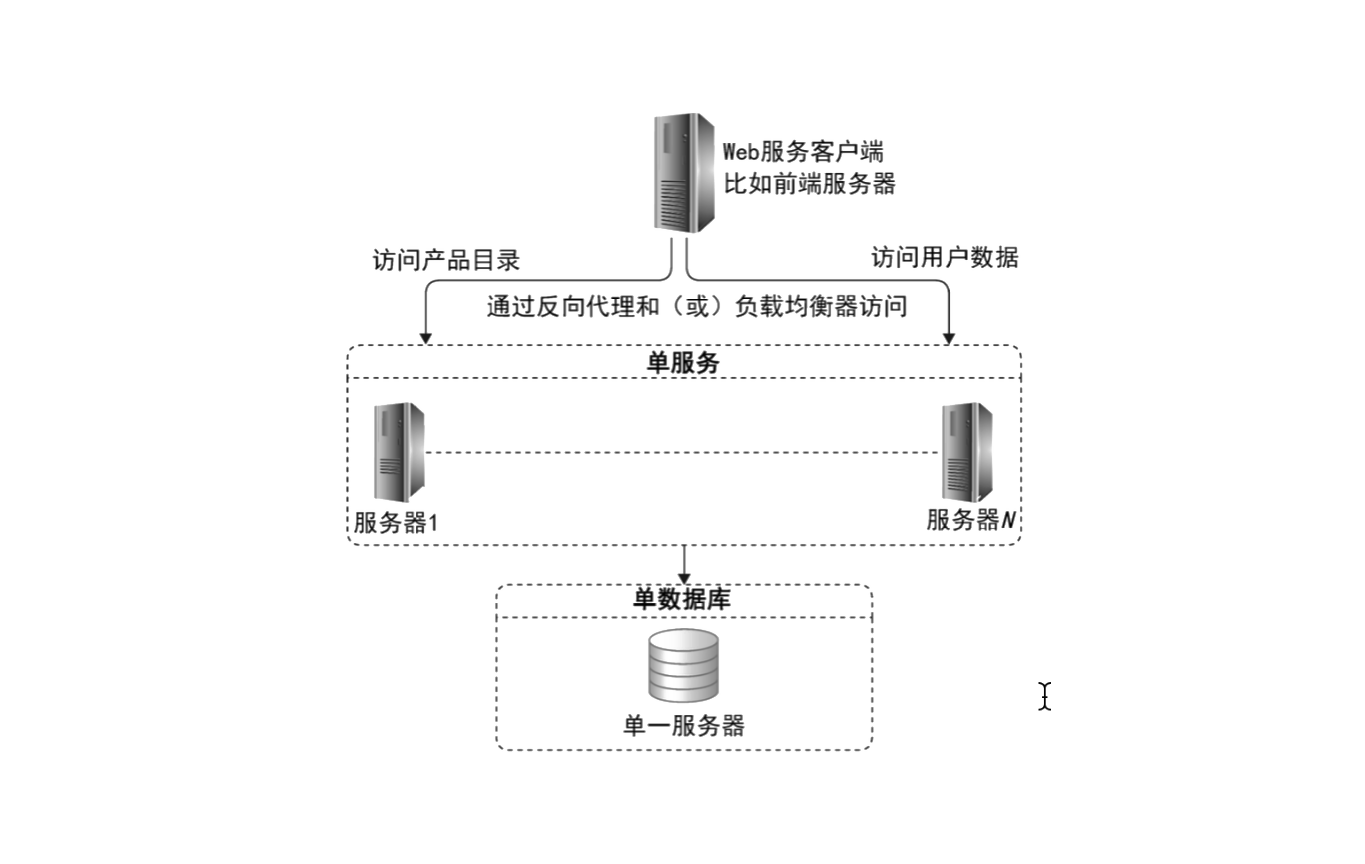
主从复制
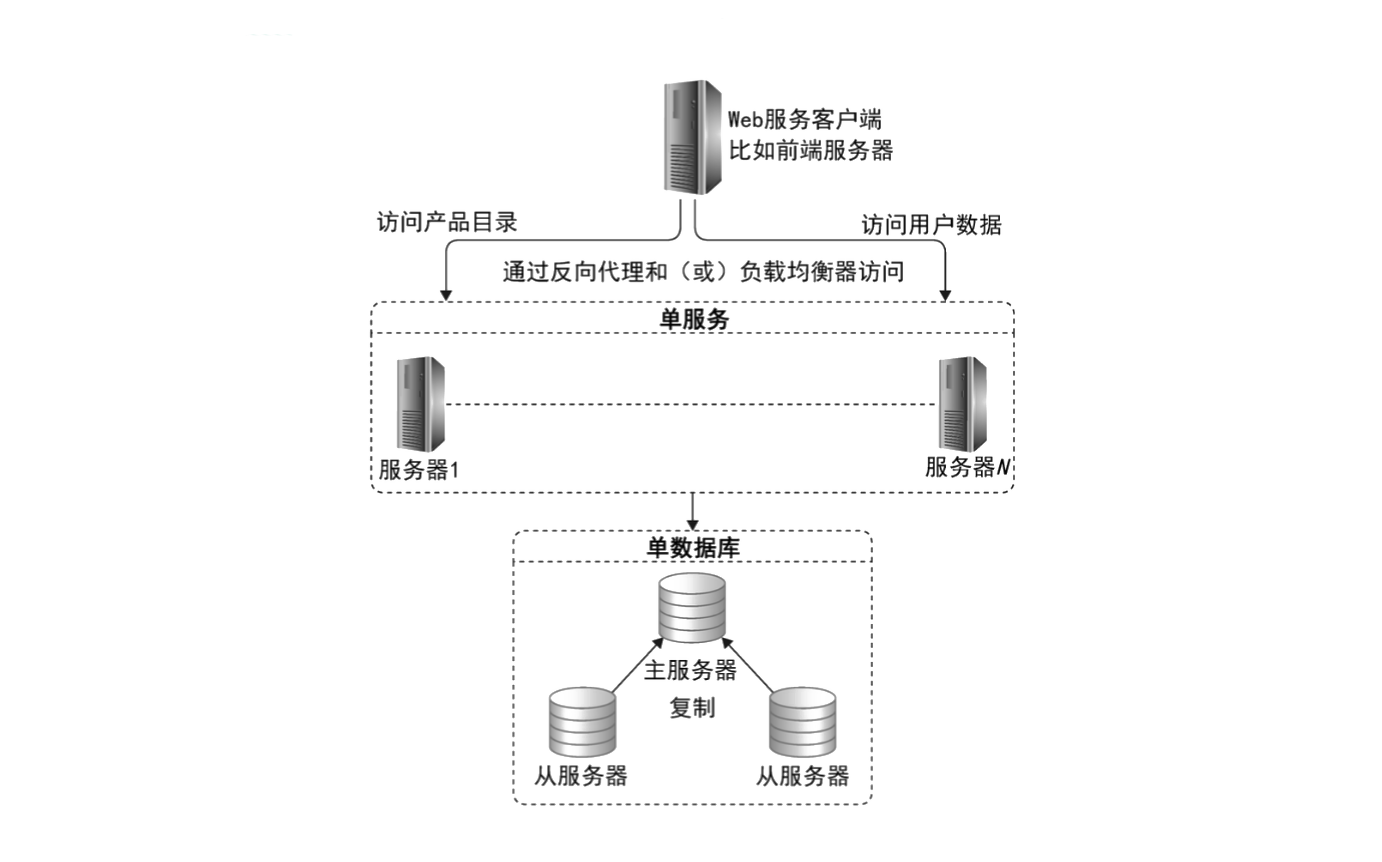
如果对系统的可用性和对数据库的访问性能提出更高要求,就可以通过数据库的主从复制进行初步的伸缩。通过主从复制,实现一主多从。应用服务器的写操作连接主数据库,读操作从从服务器上进行读取,如下图所示
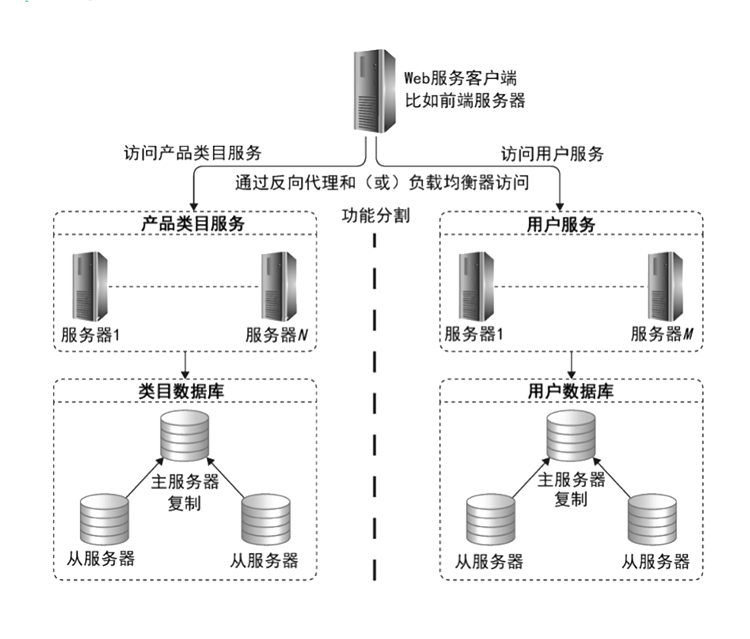
业务分库
随着业务更加复杂,为了提供更高的数据库处理能力,可以进行数据的业务分库。数据的业务分库是一种逻辑上的,是基于功能的一种分割,将不同用途的数据表存储在不同的物理数据库上面去。 在下图的例子中,我们有产品类目服务和用户服务,两个应用服务器集群,对应地,我们将数据库也拆分成两个,一个叫作类目数据库,一个叫作用户数据库。每个数据库依然使用主从复制。通过业务分库的方式,我们在同一个系统中,提供了更多的数据库存储,同时也就提供了更强大的数据访问能力,同时也使系统变得更加简单,系统的耦合变得更低。
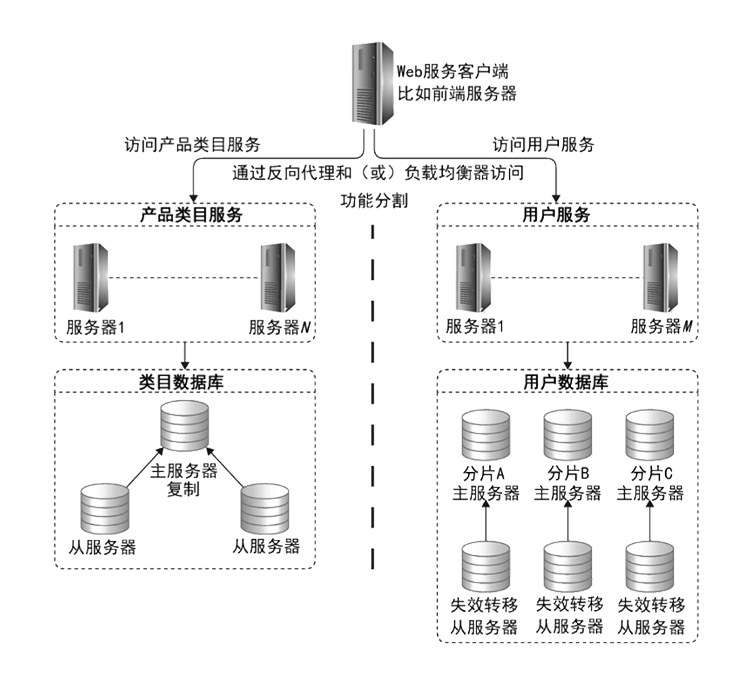
综合部署
而更复杂的综合部署方案,则是根据不同数据的访问特点,使用不同的解决方案进行应对。比如类目数据库,也许通过主从复制就能够满足所有的访问要求,但是如果用户量特别大,进行主从复制或主主复制,还是不能够满足数据存储以及写操作的访问压力,这时候就可以对用户数据库进行数据分片存储了,同时每个分片数据库也使用主从复制的方式进行部署,如下图所示:
NoSQL数据库
NoSQL:翻译为 不仅仅是SQL。
这种数据库和传统的关系数据库不同,它的主要访问方式也不再使用 SQL 进行操作,所以被称作 NoSQL 数据库。NoSQL 数据库主要是解决大规模分布式数据的存储问题。比如redis,就是典型的NoSQL。
但是也有一个问题,就是数据可靠性和一致性的问题。
CAP原理和数据一致性
CAP 原理是说,对于一个分布式系统,它不能够同时满足一致性(C)、可用性(A)以及分区耐受性(P)这三个特点。
其中,
- 一致性是说,任何时候集群中所有的数据的备份都是一致的;
- 可用性是说,当分布式集群中某些服务器节点失效的时候,集群依然是可用的;
- 分区耐受性是说所当网络失效的时候,节点无法通信的时候,系统依然是可用的。
而 CAP 原理就是说这三者无法同时满足。通常一个分布式应用系统,可用性是必不可少的,而分区耐受性也是需要满足的。因此在现实中,很多系统是通过对数据的一致性做文章,来提供一个满足要求的分布式系统的。
最终一致性
所以,有人提出了BASE理论,也就是最终一致性,不要求实时一致性。
最终一致是说,在一个分布式系统中,在某个时候,不同服务器上存储的同一个数据可能是不一致的,但是它最终还是一致的,只要不一致的时间不影响应用程序的正确性,我们就是可以接受的,这种一致性叫作最终一致性。
如下图:
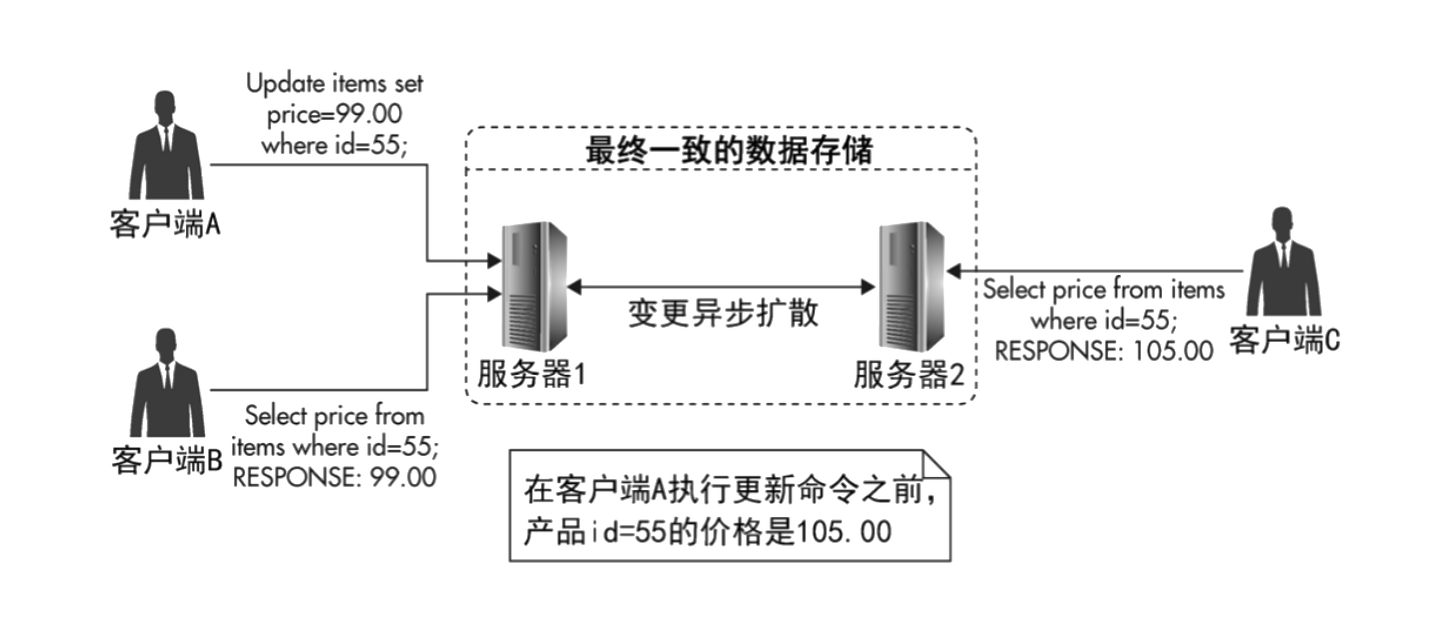
- 客户端 A 连接到服务器 1,客户端 C 连接到服务器 2,客户端 A 对数据作出变更操作。
- 服务器 1 将变更扩散到服务器 2,那么,客户端 C 连接到服务器 2 的时候,可能不会立即得到最新的数据。
- 但是过一会儿,等变更扩散完成了,就可以获得最新的数据了。
但有个问题,就是肯定会有一个时刻,数据是不一致的,如何处理呢?
根据时间戳,最后写入覆盖,在数据复制的时候就会出现数据冲突,这个时候解决冲突的办法就是根据时间戳进行判断,时间戳大的,也就是说最新的数据,覆盖时间戳小的、旧的数据。
通过投票进行解决,典型的就是 Cassandra 中的冲突解决机制。
通过分布式锁的方式,来避免不一致情况的发生。
客户端判断,比如获取两个相同的数据的时候,按照一定的规则去判断。
总结
分布式数据库和分布式存储是分布式系统中难度最大、挑战最大,也是最容易出问题的地方。解决的办法主要是数据库的复制,通过数据库的复制,提升数据库的读性能和系统的可用性。
如果对数据存储和数据库的写操作有更高要求的时候,就需要通过数据分片的方式来实现。在具体的部署过程中,可以混合使用数据复制、数据分库和数据分片几种技术方案。
如果你的应用不是非要使用关系数据库的话,你还可以选择 NoSQL 数据库,NoSQL 数据库会提供更强大的数据存储能力和并发读写能力,但是 NoSQL 数据库因为 CAP 原理的约束可能会遇到数据不一致的问题。数据不一致的问题,可以通过时间戳合并、客户端判断以及投票这样的几种机制解决,实现最终一致性。

