
前面我们讲到了zookeeper的入门,下面我们讲解实战篇。
实现分布式锁
背景
在分布式环境下,如何实现互斥访问共享资源?对了,锁机制。在分布式环境下,多个节点或者进程可能需要协调它们的操作,以确保某个时刻只有一个节点访问共享资源,避免数据不一致或冲突的问题。
分布式锁通常具有以下特征:
互斥性
在任何时刻,只有一个节点能够持有锁,其他节点无法获得锁。
可靠性
系统在各种条件下都能正确工作,即使在节点故障或者网络分区的情况下也能够保证锁的正确性。
容错性
能够处理节点故障或者网络故障,确保锁的正确分配
性能
提供高效的锁管理机制,不会引入过多的延迟。
那么分布式锁的方法很多,常见的有:
基于数据库的锁
使用数据库的事务特性来实现分布式锁,但是由于ttl很难设定,容易造成死锁,固很少使用。
基于缓存的锁
使用redis,操作共享数据的时候加锁,如果加锁失败则说明已经有其他方获得锁了。比较常见,使用简单。
基于分布式算法的锁
使用分布式算法,比如raft来实现分布式锁。
基于zookeeper的锁
利用zookeeper的临时节点和顺序节点特性,实现分布式锁,我们等下聊。
zk中锁的种类
读锁
也是共享锁,大家都可以读,想要上读锁的前提是,之前的锁没有写锁。
写锁
只有得到写锁的才能写,上写锁的前提是之前没有任何锁。
举个例子:
张三、李四、王五都喜欢村里的小芳,现在都是单身的情况下,他们三都可以和小芳约会,约会就是读锁。
但是有一天张三和小芳结婚了,那么李四和王五还能和小芳约会吗?不能,理解为结婚就是写锁。只有离婚,也就是释放锁了,小芳才可以约会。
现在离婚状态了,李四和小芳正在约会,那张三和小芳还能复婚吗?不能,因为还没断干净怎么结婚,也就是有读锁了就不能上写锁。
zk如何上读锁
先看图: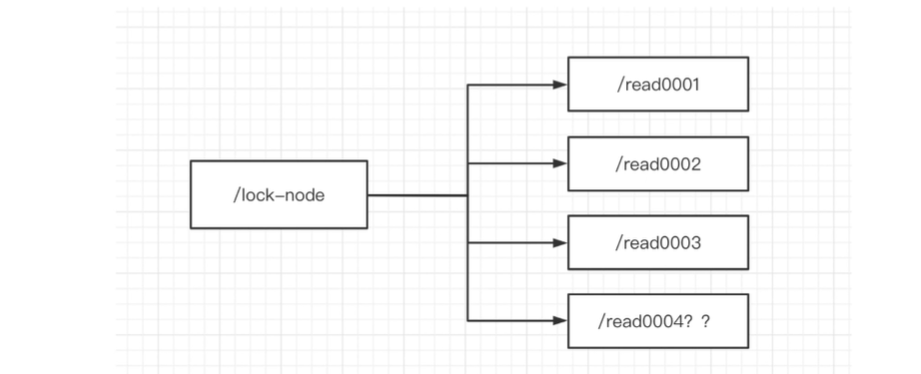
先看步骤吧。
首先创建一个临时序号节点,也就是会话结束后会删除,节点的数据是read,表示读锁。
上图,我们先创建/read0001,先假装没有后面的0002等等,那么这个锁是可以上成功的,因为前面没有任何锁。
其次获取当前zk中的序号比自己小的所有节点。
也就是/read0003过来了,它获取/read0001和/read0002节点。
判断最小节点是否是读锁。
/read0003为什么要判断最小是否是读锁呢?不应该判断比自己所有小的节点是否是读锁吗?
因为如果最小锁是读锁的话,那后面有可能是写锁吗?不可能吧。换句话说,我们能否上读锁,也就是前面所有的锁都不能是写锁。那么就只看第一个是否是读锁了。- 如果不是读锁,则上锁失败,为最小节点设置监听,然后阻塞等待,zk的watch机制会当最小节点发生变化的时候通知当前节点,于是再执行第二步的流程。
- 如果是读锁的话,则上锁成功。是上读锁成功。
代码展示
type ZkReadLock struct {
conn *zk.Conn
path string
}
func NewZkReadLock(conn *zk.Conn, path string) *ZkReadLock {
return &ZkReadLock{conn: conn, path: path}
}
func (rl *ZkReadLock) RLock() error {
acl := zk.WorldACL(zk.PermAll)
// 创建临时顺序节点
nodePath, err := rl.conn.CreateProtectedEphemeralSequential(rl.path+"/lock-", nil, acl)
if err != nil {
return err
}
// 获取所有子节点
children, _, err := rl.conn.Children(rl.path)
if err != nil {
return err
}
// 将子节点按升序排序
sort.Strings(children)
// 找到当前节点的位置
index := sort.Search(len(children), func(i int) bool {
return children[i] >= nodePath[len(rl.path)+1:]
})
// 判断最小节点是否是自己
if index == 0 {
// 成功获取锁
return nil
}
// 获取比自己小的所有节点
smallerNodes := children[:index]
// 判断最小的节点是否是读锁
minNode := findLittleNode(smallerNodes)
if isReadLock(minNode) {
// 成功获取锁
return nil
}
// 未能获取锁,删除创建的临时节点,以避免节点泄漏
rl.conn.Delete(nodePath, -1)
return fmt.Errorf("failed to acquire read lock")
}
func (rl *ZkReadLock) RUnlock() error {
// 释放节点
return nil
}
func isReadLock(node string) bool {
return strings.HasPrefix(node, "lock-")
}
func findLittleNode(nodes []string) string {
if len(nodes) == 0 {
return ""
}
return nodes[0]
}
调用
func main() {
conn, err := zkdemo.Connect()
if err != nil {
panic(err)
}
// 创建Zookeeper读锁
readLock := zkdemo.NewZkReadLock(conn,"/name")
// 捕获中断信号以优雅地释放锁
signalCh := make(chan os.Signal, 1)
signal.Notify(signalCh, os.Interrupt, syscall.SIGTERM)
go func() {
<-signalCh
fmt.Println("Received interrupt signal. Releasing lock.")
readLock.RUnlock()
os.Exit(1)
}()
// 尝试获取读锁
fmt.Println("Acquiring read lock...")
err = readLock.RLock()
if err != nil {
panic(err)
}
fmt.Println("Read lock acquired.")
defer readLock.RUnlock()
// 业务逻辑,这里可以执行需要读锁的操作
// 模拟持有锁一段时间
time.Sleep(time.Second * 10)
fmt.Println("Read lock released.")
}
如何上写锁?
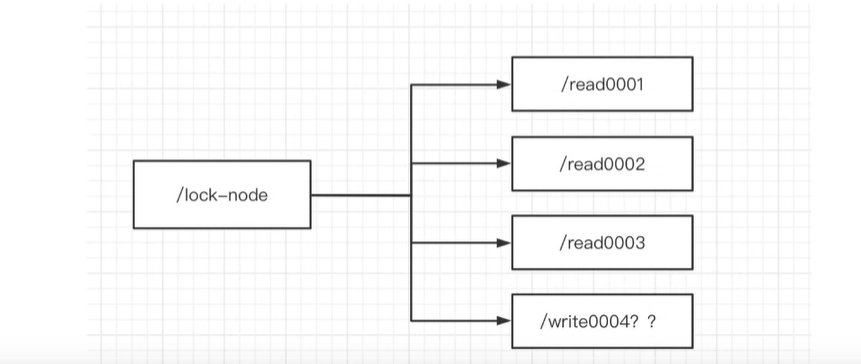
步骤如下:
创建一个临时序号节点,节点的数据是write,表示是 写锁
比如上图的/write0004
获取zk中所有的子节点
判断自己是否是最小的节点。
这里逻辑变了,为什么?因为对于写锁来说,自己前面不能有任意锁,也就是前面不能有任意节点。
- 如果是,则写锁成功。
- 如果不是,说面前面还有所,则上锁失败,监听最小的节点,如果最小节点有变化,则回到第二步。
上代码
type ZkLock struct {
conn *zk.Conn
path string
}
func NewZkLock(conn *zk.Conn, path string) *ZkLock {
return &ZkLock{conn: conn, path: path}
}
func (z *ZkLock) Lock() error {
acl := zk.WorldACL(zk.PermAll)
// 创建临时顺序节点
nodePath, err := z.conn.CreateProtectedEphemeralSequential(z.path+"/lock-", nil, acl)
if err != nil {
return err
}
// 等待锁
for {
children, _, ch, err := z.conn.ChildrenW(z.path)
if err != nil {
return err
}
// 获取最小的节点
minNode := findMinNode(children)
if minNode == nodePath {
// 自己是最小序号
break // 成功获取锁
}
// 等待节点删除或超时
select {
case event := <-ch:
if event.Type == zk.EventNodeDeleted {
continue
}
case <-time.After(5 * time.Second):
return fmt.Errorf("timeout waiting for lock")
}
}
return nil
}
func (z *ZkLock) Unlock() error {
return z.conn.Delete(z.path, -1)
}
func findMinNode(nodes []string) string {
minNode := nodes[0]
for _, node := range nodes {
if strings.Compare(node, minNode) < 0 {
minNode = node
}
}
return minNode
}
调用方
func main() {
conn, err := zkdemo.Connect()
if err != nil {
panic(err)
}
// 创建Zookeeper写锁
writeLock := zkdemo.NewZkLock(conn, "/name")
// 捕获中断信号以优雅地释放锁
signalCh := make(chan os.Signal, 1)
signal.Notify(signalCh, os.Interrupt, syscall.SIGTERM)
go func() {
<-signalCh
fmt.Println("Received interrupt signal. Releasing lock.")
writeLock.Unlock()
os.Exit(1)
}()
// 尝试获取写锁
fmt.Println("Acquiring write lock...")
err = writeLock.Lock()
if err != nil {
fmt.Println("获取写锁失败,这里是继续监听还是返回,由业务决定")
return
}
fmt.Println("获得写锁")
defer writeLock.Unlock()
// 模拟持有锁一段时间
time.Sleep(time.Second * 10)
}
惊群效应
通过上述两种上锁的方式,大家都在监听第一个节点的变化,假设并发有1000个,那第一个节点变化,就会引起剩下的999个同时被惊动,这就是惊群效应,也是羊群效应。这种对zk的压力非常大。
我们可以调节成链式的监听,如下:
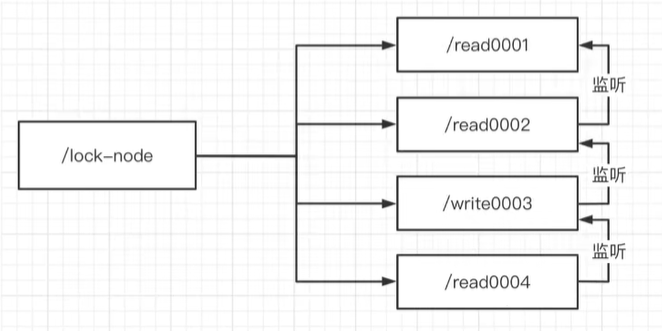
比如read0004,就去监听0003,因为0001的变化也影响不到0004,这样形成链式的监听,就会减少多个node同时监听一个node的变化,造成不必要的资源开销。但是,这样就没有问题了吗?
还是0004这个去监听0003,假设0003线程挂了,那0004如何去监听?
所以解决的方法是,获取到比自己小的全部节点,然后去监听比自己小的最近的那个,然后去监听它,即可。那么 如何监听呢?看下文。
zk的watch机制
我们的节点,比如上面的学校、工厂、年级等等都是节点,我们的客户端,无论是zkCli还是go语言,都可以去监听某一个节点,当这个节点发生变化的时候,也就是这个节点调用了create、delete、setData方法的时候,就会触发对应的事件,然后请求监听的客户端就会收到异步的通知,比如,下面演示:

- 左侧客户端,创建了一个/wtest的节点。通过-w 进行监听,w就是watch的意思。
- 右侧客户端此时针对/wtest的节点set了一个值。
- 左侧客户端收到了响应回调事件,但是并未得到具体的值。
- 右侧客户端第二次进行set的命令,但左侧客户端并未得到响应,也就是get -w 只能获得一次响应,是一次性的。
如果想继续获得监听,我们可以这么处理,在每次获得回调事件的时候,再次通过get -w 来拿数据且继续加监听,来得到循环监听的结果。
-w只能监听当前节点的变化,并不能监听子节点的变化,比如/wtest/t1 这个是监听不到的。需要想监听,可以通过 ls -w /wtest 这个命令来监听子节点的变化。
原理
在zookeeper内部,维护了一个节点的监听注册表,注册表记录了每个节点上注册的 Watcher 列表。当节点的状态发生变化,Zookeeper 会检查相应节点的注册表,并向注册在该节点上的客户端发送通知。客户端也通过NIO的方式等待结果的回调。Zookeeper 通过长连接实现对客户端的通知。通知是通过连接上的socket进行的。
需要注意的是,Zookeeper 的通知机制是异步的。客户端无需主动轮询,而是通过监听 Socket,实时地接收来自 Zookeeper 的通知。这种基于长连接的异步通知机制有效地降低了通信的延迟,并能够及时将节点状态的变化通知给客户端。
总体来说,Zookeeper 的通知机制是通过长连接和异步通知实现的,确保了实时性和高效性。
代码演示
func WatchDemo(conn *zk.Conn, path string) {
_, _, watch, err := conn.GetW(path)
if err != nil {
return
}
for {
select {
case event := <-watch:
if event.Type == zk.EventNodeDataChanged {
fmt.Println("node data change")
_, _, watch, _ = conn.GetW(path)
} else if event.Type == zk.EventNodeDeleted {
fmt.Println("node data delete")
// 值得注意的是,删除之后不能再次监听这个节点,因为所有的东西都变动了,不再是原先的节点了。
}
}
}
}
zookeeper集群搭建
分布式,重点在集群,一旦涉及到集群,就会出现各种问题,比如选举、数据同步等等。
假设有四台服务器,配置如下:
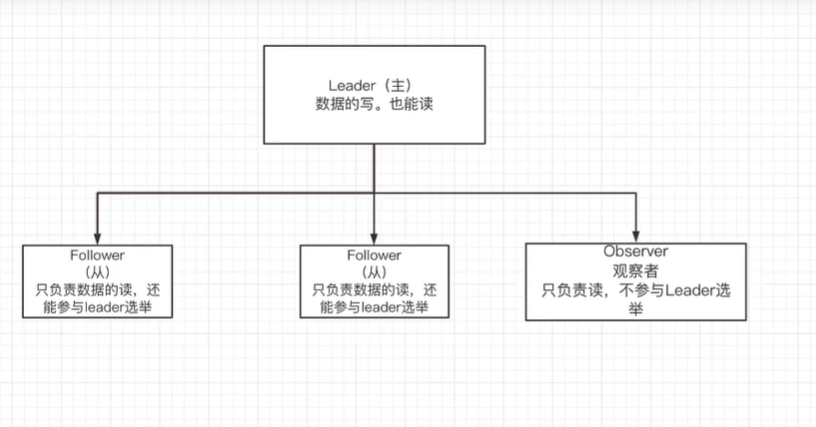
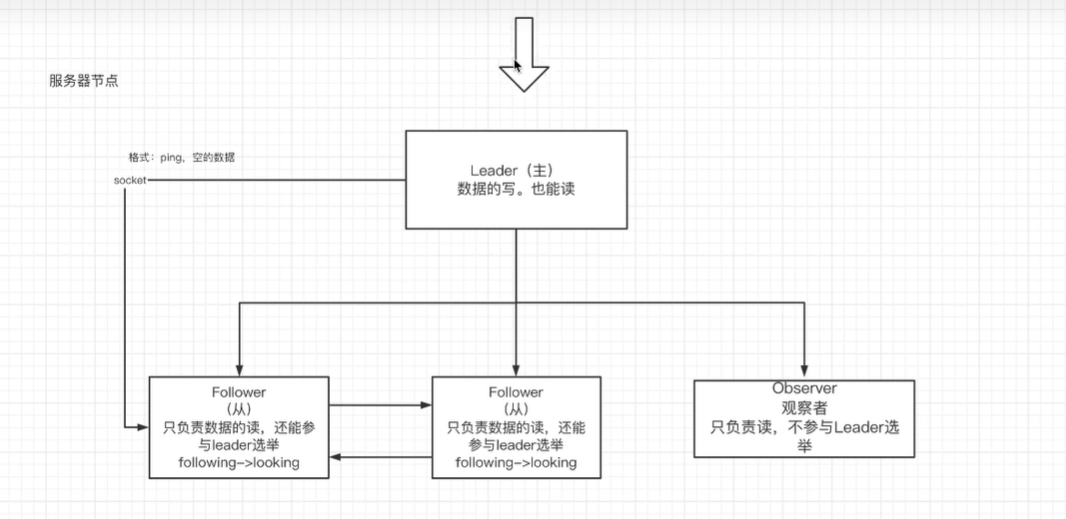
zookeeper集群的节点有三种角色:
- Leader:处理集群的所有事务请求,集群中只有一个Leader。
- Follower:只能处理读请求,参与Leader选举。
- Observer:只能处理读请求,提升集群读的性能,但是不参加Leader选举。
集群配置
分别创建剩下的三个容器
一起四个容器,分别创建四个文件夹
/usr/local/zookeeper/zkdata/zk1# echo 1 > myid /usr/local/zookeeper/zkdata/zk2# echo 2 > myid /usr/local/zookeeper/zkdata/zk3# echo 3 > myid /usr/local/zookeeper/zkdata/zk4# echo 4 > myid编写4个 zoo.cfg
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. 修改对应的zk1 zk2 zk3 zk4 dataDir=/usr/local/zookeeper/zkdata/zk1 # the port at which the clients will connect clientPort=2181 #2001为集群通信端口,3001为集群选举端口,observer(观察者身份) server.1=124.223.47.250:2001:3001 server.2=124.223.47.250:2002:3002 server.3=124.223.47.250:2003:3003 server.4=124.223.47.250:2004:3004:observer即可
那么 为什么会有两个端口呢?比如server.1=124.223.47.250:2001:3001是什么意思?
第一个端口,比如2001,是用来做数据同步的,也就是服务之间通讯的,
第二个端口,比如3001,是用来集群中,投票的leader端口,叫做选举端口,也是投票端口。
ZAB协议
非常重要的一个概念,也是zookeeper在集群中要遵循的一个协议,就是ZAB协议,也是zookeeper atomic broadcast,原子广播协议,它可以解决zookeeper的奔溃恢复和主从数据同步的问题。 也就是设计到了原来的主节点挂掉之后,新的主节点如何从从节点中选举出来?数据如何进行同步的问题。
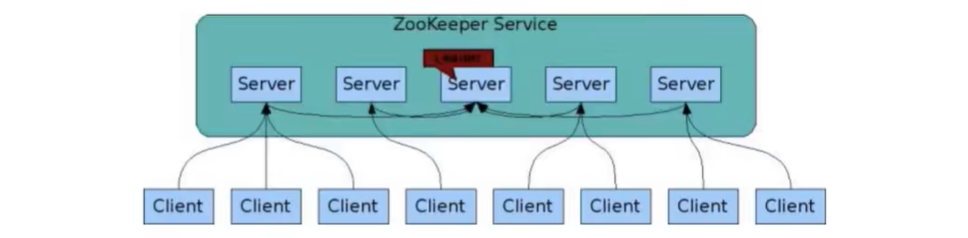
如上图,为zookeeper的集群,在集群里面部署了五个节点,其中有一台作为主节点。其中客户端可以连接到剩下的四个节点,然后这四个节点互相都去连接主节点,把数据进行同步。
ZAB协议中,定义了四种节点状态,如下:
节点状态
Looking
选举状态,当服务节点刚上线的时候,就会进入这个状态。
Following
Follower节点所处的状态,除了leader节点之外的状态
Leading
Leader节点(主节点)所处的状态,也就是经过选举之后,Leader成功当选了,那么leader节点就是这个状态。
Observing
观察者节点所处的状态
ZAB源码里面,就是根据不同的状态来执行不同的动作。
当只有一台节点上线后,此时这个节点的状态就是Looking,它没办法选举,因为只有一台节点,当第二台节点上线后,第二台节点也变为Looking,但是里面就进行选举的动作,那么这个动作是怎样的呢?下面分析。
leader选举过程
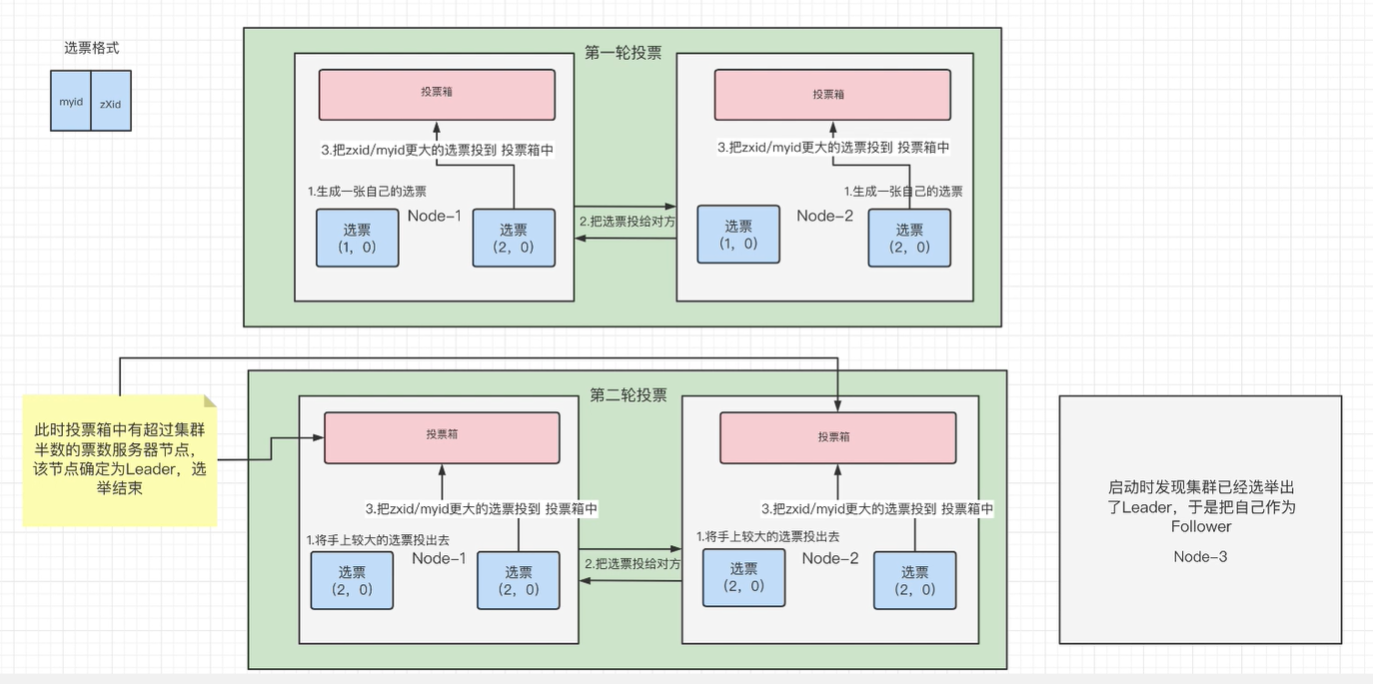
选票格式:一个是myid为当前节点的id,一个是zXid是当前节点的事务id,也就是经过数据的增删改,这个事务id就会加1,事务id描述这个节点经过多少次的变化。这两个数据组成选票。
第一轮投票
Node-1为第一台zk服务器,Node-2为第二台zk服务器。
第一步:生成自己的选票:其中Node-1最开始生成自己的选票,myid就是1,zXid就是0,因为此时还没有经过任何的操作。其中Node-2的myid就是2,zXid也是0.第二步:把选票,再投给对方,也就是Node—1生成一个选票投给Node-2,Node-2也是如此。这样Node1和Node2各有两个选票,一个是自己生成的,一个是对方投过来的。
第三步:投票到投票箱。在Node-1上面,看zXid谁大,谁大就把它的选票投到投票箱里面去,反之Node-2也是一样的。但是此时Node-1和2的zXid都是一样大,那就看谁myid大,谁大就投谁。
所以在第一轮投票结束后,Node-1和Node-2的投票箱里面,都是投的Node-2.
第二轮投票
为什么要进行第二轮?因为Node1和Node2里面的投票箱,投票并未过半。总共有四个节点,其中一个是观察节点,那就是三个,三个过半应该是两票,但目前每个节点里面都只有一票,虽然都是Node2.但是是分别的,只能算一票。
第二轮的时候,不再投对方了,而是把第一轮投票结果中的,认为较大的选票投给对方,也就是Node2是较大的。
接下来就是Node1节点会把Node2节点作为选票丢给Node2,Node2节点也会把Node2节点作为选票丢给Node1。实际上都是node2.那这样是不是有问题?所有的都投给了Node2?嗯,如果是两个节点,都是新的,那么确实是第二个节点就是主节点,但如果此时新加入节点来了,它的zXidId大,那么还是会选择新的。
于是乎,第二轮下来后,Node2在Node1和2的投票箱中,有两票了,已经过半了,此时 Node2获胜。
第三个节点启动的时候,发现集群已经选举出Leader了,于是直接把自己作为Follower。
总共有多少个节点,在配置文件中。
所以,集群最好是奇数节点,因为过半好判断。
崩溃时的Leader选举
主节点的职责是负责写数据,当然也能读。如果主节点挂掉了,应该是需要从从节点之中,选举一个出来作为主节点,那么有两个问题。第一个是从节点如何知道主节点挂了?第二是选举谁来当主节点?
集群之前,是有通信端口的,节点成为Leader之后,会周期性的向所有从节点去发送ping命令,也就是格式是ping,数据是空的,对于从节点来说,因为要做主从同步,会建立socket链接,时时刻刻的从主节点获取数据,如果收到的是ping命令,那么说明主节点是正常的状态。
Leader一旦挂掉,socket就会挂掉,Follower周期性的去读取主节点的数据,就会异常抛出错误,则所有的从节点就会从following状态,从新进入looking状态。从新选举。
具体选举逻辑,看上面的投票机制。
总结就是:Leader建立完后,Leader周期性地不断向Follower发送心跳(ping命令,没有内容的socket)。当Leader崩溃后,Follower发现socket通道已关闭,于是Follower开始进入到Looking状态,重新回到上一节中的Leader选举状态,此时集群不能对外提供服务
主从数据同步
看下图:
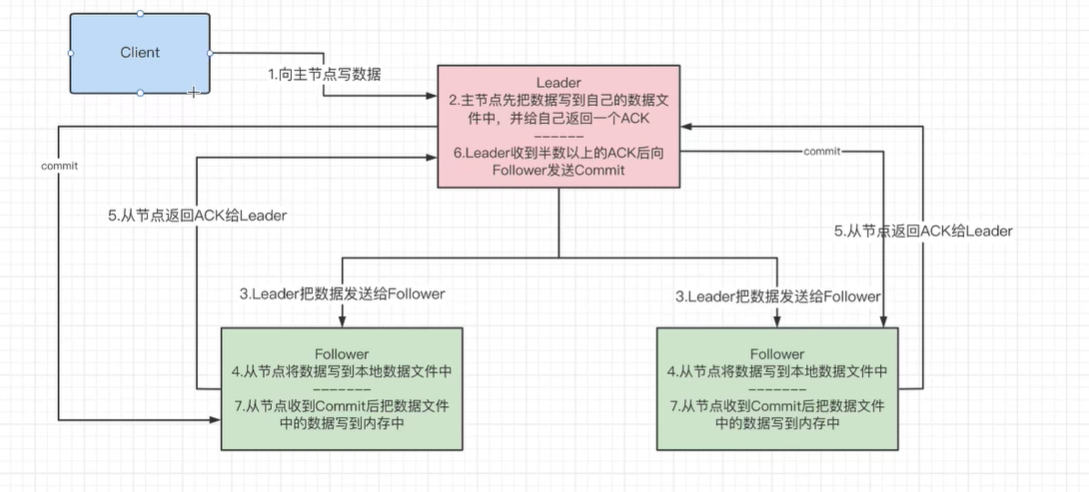
- 1:客户端的数据,向主节点写数据。
- 2:主节点先把数据写到自己的数据文件中(数据在运行的时候是在内存当中,并非是数据文件中),写完之后,给自己返回一个ACK。
- 3:收到ACK之后,主节点把数据同步的发给所有的从节点。这是一个广播的过程。
- 4:从节点收到数据之后,把数据先写到本地数据文件中(还未到内存)
- 5:当从节点写完本地数据文件后,返回一个ACK给主节点,也就是Leader节点。
- 6:Leader收到集群半数以上的ACK之后,向所有的Follower节点发送Commit,当然主节点自己也会做commit。
- 7:从节点收到commit之后,就把数据文件中的数据,写到内存里面。
也就是,整个7步流程完成后,数据才到内存里面,这个数据才算真正的写成功。这个像不像分布式事务里面的2CP,两阶段提交?
那为什么要半数以上的ACK收到后,才会发送Commit呢?
这是提高了整个集群的写数据性能,因为半数都收到了,说明集群网络是没有问题的。
那这个半数,是从节点的半数还是整个集群的?是整个集群的。
明显,zookeeper明显是不属于强一致性。可能只是最终一致性。
NIO和BIO
BIO(Blocking I/O):
同步阻塞模型: 在 BIO 模型中,I/O 操作是同步阻塞的。当一个线程执行一个 I/O 操作时,它会阻塞直到该操作完成。这意味着线程会一直等待,无法执行其他任务,直到 I/O 操作完成。
一对一关系: 在 BIO 模型中,通常是一对一的关系,即一个线程对应一个客户端连接。这导致了线程数量的增加,当需要处理大量并发连接时,会导致线程资源的浪费。
NIO(New I/O):
同步非阻塞模型: NIO 模型采用了同步非阻塞的方式。在 NIO 中,一个线程可以同时处理多个客户端连接。当一个线程执行一个 I/O 操作时,如果该操作不会立即完成,线程不会被阻塞,而是继续执行其他任务。
多路复用器(Selector): NIO 的关键组件是多路复用器(Selector),它可以管理多个通道,实现了一个线程可以同时监听多个通道的能力,从而提高了处理并发连接的效率。
缓冲区(Buffer): NIO 使用缓冲区作为数据传输的载体,数据首先被读入缓冲区,然后从缓冲区写入通道,或者从通道读取到缓冲区。
总体来说,BIO 是一种传统的模型,每个连接都需要一个独立的线程,导致资源消耗较大。而 NIO 采用了异步非阻塞的模型,通过少量的线程处理大量的连接,提高了系统的并发处理能力,适用于高并发的场景。
在zookeeper中:
- NIO
- 用于被客户端连接的2181端口,使用的是NIO模式与客户端建立连接
- 客户端开启Watch时,也使用NIO,等待Zookeeper服务器的回调
- BIO
- 集群在选举时,多个节点之间的投票通信端口,使用BIO进行通信

