
当前最流行的部署方式,客官,怎能不了解一下?
介绍
Kubernetes官方介绍为:开源的,用于管理云平台中多个主机上的容器化的应用,其目标是让部署容器化的应用简单并且高效,提供了应用部署、规划、更新、维护的一种机制,是一个全新的基于容器技术的分布式架构方案。
Kubernetes的名字源于希腊语,意思为“舵手”或者是“飞行员”,因为k和s中间有8个字母,所以简单粗暴就叫做k8s。(让我不禁想到,国际化多语言翻译的时候,Internationalization,直接简写i18n)。是google在14年开源的项目,结合社区中最优秀的想法和实践。
理解为:就是帮我们管理容器应用,就是容器化的部署变得简单、高效、快速的部署容器化的应用。
这样,不是和dockercompose一样?都是管理容器的?不不不,k8s可以管理云平台中多个主机的应用,而dockercompose只能管理单个主机的。
那为什么需要k8s呢?
背景
我们在部署应用程序的方式上,经历了三个时代:
传统部署
互联网早期的时候,直接使用单体化部署,将应用程序直接部署在物理机上面。
优点:简单,不需要其他技术的参与,一台不够就做集群。
缺点:不能为应用程序定义资源使用边界,很难合理分配计算资源,而且程序之间容易产生影响,比如A应用使用mysql5.7,B应用使用mysql8.0,一台主机只能按照一个mysql,咋整?
虚拟化部署
可以在一台物理机上面运行多个虚拟机,每个虚拟机都是独立的一个环境,比如Windows中通过VMware虚拟多个系统。
优点:程序环境不会相互产生影响,提供了一定程度的安全性。
缺点:增加了操作系统,浪费了部分资源。
容器化部署
与虚拟化类似,但是共享了操作系统
优点:可以保证每个容器拥有自己的文件系统、CPU、内存、进程空间等;运行应用程序锁需要的资源都被容器包装,并和底层基础架构解耦;容器化的应用程序可以跨云服务商、跨操作系统进行部署。
缺点:管理起来比较麻烦,比如容器宕机后的处理,且容器中存在的文件容易丢失。当然,k8s都会解决。
功能
k8s本质就是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理,目的是实现资源管理的自动化,主要提供如下的功能:
自我修复
一旦某个容器宕机、崩溃或者出现问题,可以在极短的时间内基于原由容器快速启动一个新的容器。
弹性伸缩
根据自身需求,自动对集群中正在运行的容器数量进行调整,在流量请求高峰的时候自动扩容,在流量平稳后减少容器数量。
自动部署和回滚
针对于配置文件编写完成后,可以自动部署,配置参数进行修改后,也会自动销毁旧容器,创建新容器,并且实现用户无感知式的滚动更新,防止服务不可用。也可以回退版本,发现当前版本有问题,可回退到上个稳定版本。
服务发现
在集群下,我们需要使用Nginx的配置来实现服务负载均衡,但是在k8s中,本身就自带服务发现和负载均衡。
存储编配
可以把所有机器存储的资源,抽象管理成一个虚拟磁盘,然后容器访问虚拟磁盘来对应真正的实体磁盘,也就无序关系真正的实体磁盘在哪里。
组件详解
首先我们来看看k8s的架构图,然后由基础架构图来讲解下各个组件
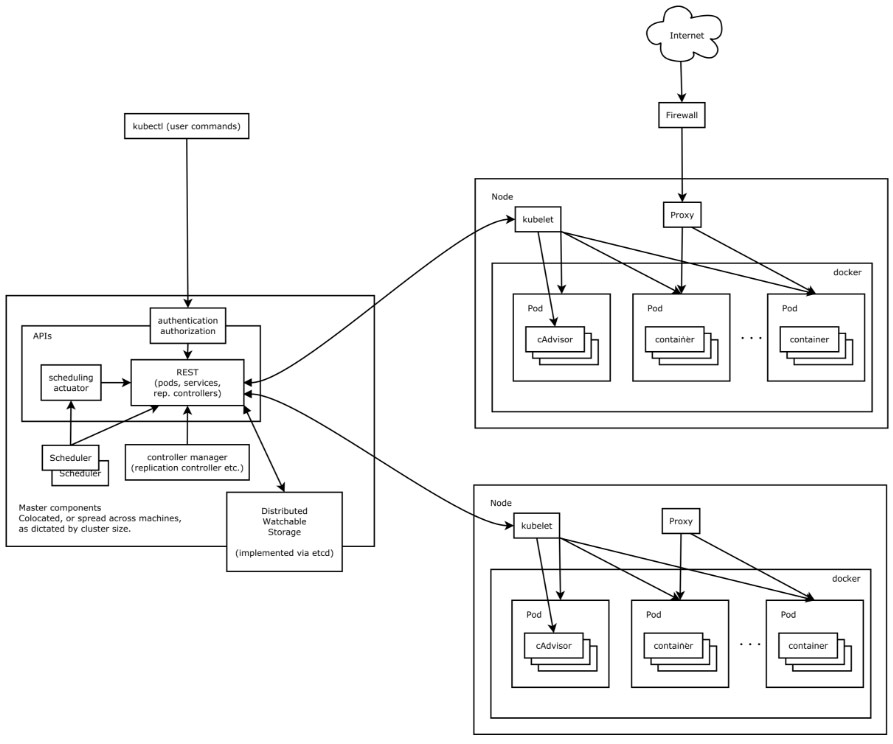
很明显可以看出,k8s集群也是主从结构,左侧为master 节点,右侧上下为普通的从node。
- 主节点有APIS的管理,外面有scheduler调度器和controller manager控制管理等等。所有的东西,方式访问REST来进行接口的调用,包括storage,分布式存储的也是调用对应的API。我们通过调用api去操作node节点。通过kubectl,也就是用户的命令来操作主节点,然后由master进行调度来进行节点的操作,操作kubectl底层其实就是调用对应的http的请求,然后响应结果。
- 一个Node节点,里面就有一个docker,一个kubelet和一个Proxy。docker理解为运行时的环境,Proxy为代理,kubelet负责一个接口的调用。外部网络可以通过防火墙来访问对应的节点。
- 目前看到只有从节点才会部署对应的应用,也就是从节点才有pod,当然主节点也可以部署pod。如果要搭建集群的话,一般是三个节点,一主两从,当然官方推荐为一主一从。我们在学习的时候,使用一主一从就可以了。
- 所有的核心,都是围绕着APIs来处理的,APIs有个关键的组件就是APIserver,维护了k8s中所有的对于功能、操作处理的接口,所有的操作都是先进入APIServer的,它就是中心。
通过架构图可以看出,基础的组件可以分为master组件和节点组件,以及一些附加的组件。
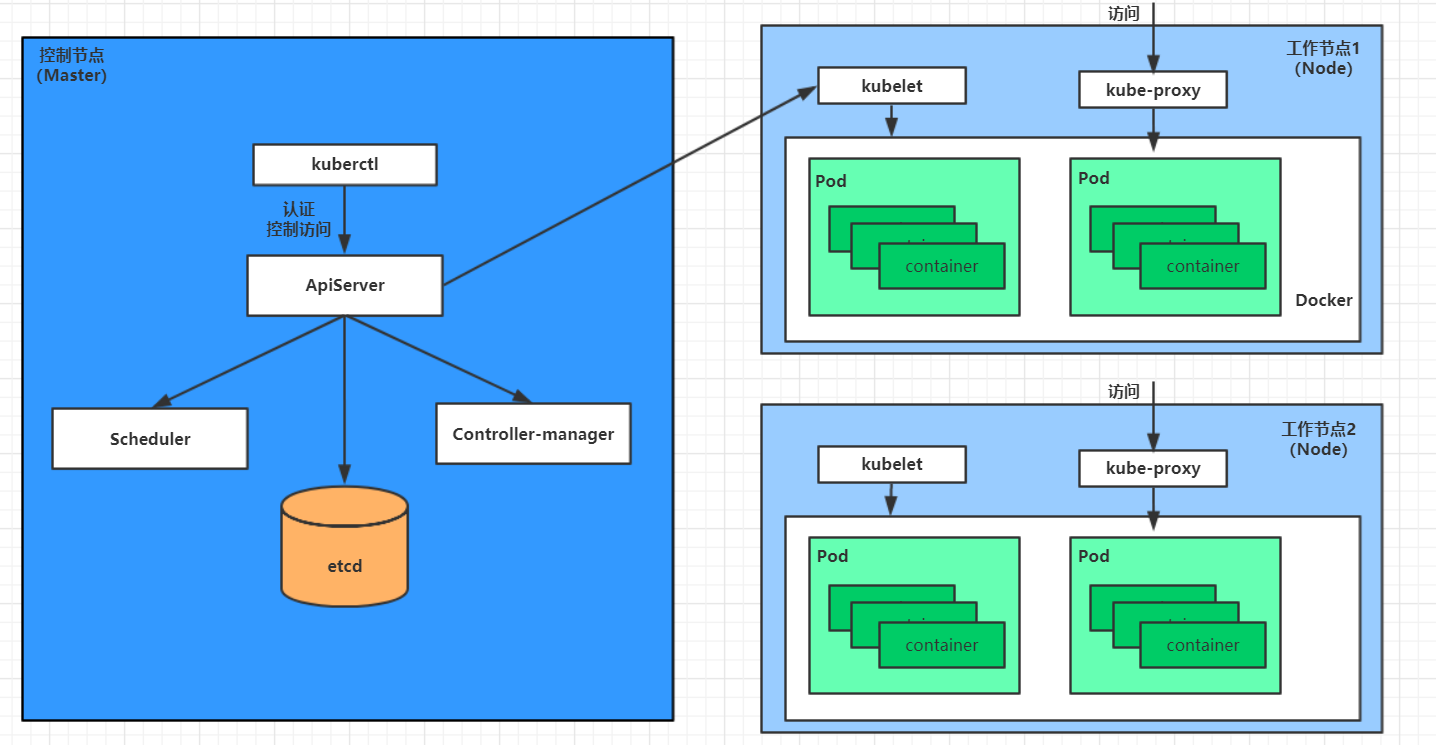
master
为集群的控制平面,负责集群的决策,可以简单理解为管理级别。它有着以下的组件:
ApiServer
接口服务,基于rest开发的k8s接口的服务,资源操作的唯一入口,接收用户输入的命令,提供认证、授权、api注册和发现等机制。
scheduler
调度器,负责集群资源调度,按照预定的调度策略将pod调度到响应的node上去。
ControllerManager
控制器,负责维护集群的状态,比如程序部署安排、故障检测、自动扩展、滚动更新等,分为云控制管理器和控制器管理器。
cloud-controller-manager:云控制管理器:第三方云平台提供的控制器api对接管理功能。
kube-controller-manager:控制器管理器:管理各个类型的控制器针对k8s中的各种资源进行管理ETCD
简单理解为k8s的数据库,键值类型存储的分布式数据库,提供了基于raft算法实现自主的集群高可用,负责存储集群中各类资源对象的信息。
Node
集群的数据平面,负责为容器提供运行环境,属于干活的人员,它也有以下组件:
Kubelet
负责Pod的生命周期以及存储、网络接口,维护容器的生命周期,也就是通过控制docker,来创建、更新、销毁容器等等。
KubeProxy
网络代理,负责提供集群内部的服务发现和负载均衡。
container-runtime
容器运行时候的环境,可以简单理解为docker(多么熟悉的名词)。当然还有containerd、CRI-O等。负责节点上容器的各种操作。
附加组件
kube-dns
负责为整个集群提供的DNS服务,针对本地域名进行管理。
ingress controller
为服务提供外网的入口,也就是外网通过ingress 来访问pod
Prometheus
提供资源监控的平台
Dashboard
提供一个gui的界面
核心概念
涉及到的一些专业术语、核心概念的讲解。
服务状态分类
如果按照状态来划分的话,我们将服务分为两类,一类是有状态,一类是无状态。这种状态,一般直接理解为处理请求的时候是否依赖于存储状态。
有状态
意味着服务在处理一个请求的时候,可能会依赖于之前的请求或者存储在服务内部的数据。比如我们的redis、mysql等等,都是典型的有状态的服务,因为它每次过来请求,都是过来查询数据的,一旦数据丢失则服务直接不可用。
优点:可以独立的存储数据,实现数据管理。
缺点:集群环境下需要实现数据的高可用,比如主从,来保证数据同步、备份、扩容等等,这些比较复杂。
无状态
指的是处理请求不依赖于特定的状态信息,每个请求都是独立的,无关的操作,服务本身不会保存请求之间的状态,比如nginx,就是一个配置,这个nginx服务宕机后,换个配置起来继续可以服务,它没有保存任何东西。
优点:对客户端透明,无依赖关系,可以高效的实现扩容、迁移。
缺点:不能存储数据,需要额外的数据服务支撑。
在现代分布式系统和微服务架构中,通常倾向于使用无状态服务,因为它们更易于扩展和管理。无状态服务的设计使得可以更容易地实现水平扩展,从而满足不断增长的请求负载。
但在某些场景下,有状态服务仍然是必需的,特别是涉及到需要保留用户状态或数据的情况。或者是无状态的服务来调用有状态的,比如go应用程序,它本身是无状态的,但是如果需要满足业务,就比较依赖于第三方有状态的服务做存储,比如调用mysql。甚至有的本身就是有状态的,它还需要依赖于第三方有状态的去托管某些状态,比如老版本的kafka需要依赖zookeeper做topic等等状态的存储。
对象
在k8s中,所有的东西都是基于资源进行描述的。如何描述资源?理解为配置文件,比如可以通过yaml格式来描述。那资源和对象有什么区别和关系?对象是基于资源创建出来的对象。优点懵逼是吧,比如资源通过yaml来描述,然后基于yaml来创建的东西,就是对象。简单可以理解为资源就是一个类,对象就是new出来的产物。
对象是用来完成一些任务的,是持久的,是有目的性的,因此 kubernetes 创建一个对象后,将持续地工作以确保对象存在。
对象规约和状态
kubernetes 并不只是维持对象的存在这么简单,kubernetes 还管理着对象的方方面面。每个 Kubernetes 对象包含两个嵌套的对象字段,它们负责管理对象的配置,他们分别是 “spec” 和 “status” 。
规约 spec
“spec” 是 “规约”、“规格” 的意思,spec 是必需的,它描述了对象的期望状态(Desired State)—— 希望对象所具有的特征。当创建 Kubernetes 对象时,必须提供对象的规约,用来描述该对象的期望状态,以及关于对象的一些基本信息(例如名称)。
理解为通过yaml来配置的配置文件。
状态 status
表示对象的实际状态,该属性由 k8s 自己维护,k8s 会通过一系列的控制器对对应对象进行管理,让对象尽可能的让实际状态与期望状态重合。
比如说在yaml就是一个规约,我配置了需要3个pod,后面对象起来后,如果是真正的3个pod,那就是完美的状态。
资源和对象
Kubernetes 中的所有内容都被抽象为“资源”,如 Pod、Service、Node 等都是资源。“对象”就是“资源”的实例,是持久化的实体。
如某个具体的 Pod、某个具体的 Node。Kubernetes 使用这些实体去表示整个集群的状态。
资源的分类
资源的分类,包含了元数据、集群、和命名空间三大类。 关系如下:
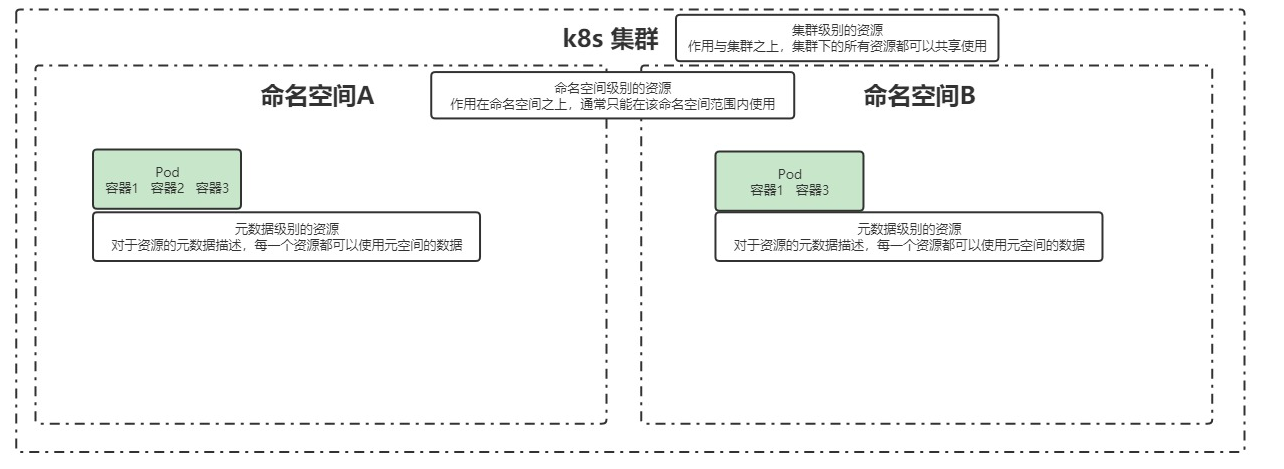
- 集群:也就是下面所有的资源都可以共享使用。
- 命名空间:一个集群可以划分多个命名空间,比如A和B,是一个逻辑意义上的集群,是一个更细致的划分。我们实际上部署的应用,都是运行在命名空间里面的,不同的命名空间有不同的资源,他们也是相互隔离的,命名空间A不能访问命名空间B。
- 元数据:基于资源元数据的描述,每一个资源都可以使用元空间的数据。公开的资源,谁都可以访问的。我们的节点是资源,我们的命名空间也是资源。
把资源进行分类,主要是为了描述当前资源能不能跨集群使用、跨命名空间使用,做一个区分。比如后续跨空间共享,如何做?
其中元数据、集群级别的,了解即可,重点关注的是命名空间类型的。
命名空间级
pod
之前一直强调pod是docker,现在纠正。
我们先使用docker容器设想一下几个问题:
- 容器1是应用程序,容器2为mysql,容器1如何访问容器2呢?通过links?使用容器名称是么?桥链接等等七七八八的骚操作?
- 容器3是应用程序A,容器4是应用程序B,它们是强耦合的,应用A写本地的数据需要应用B来读,如何配置?挂载同一个容器卷?
虽然docker也可以做,但是总感觉通过不正规的手段,如果各个容器都是在同一个地方,或者一个大的容器里面,里面共享同一个网络、文件系统,是不是可以解决上面的问题?
对,现在把pod理解为容器组吧。
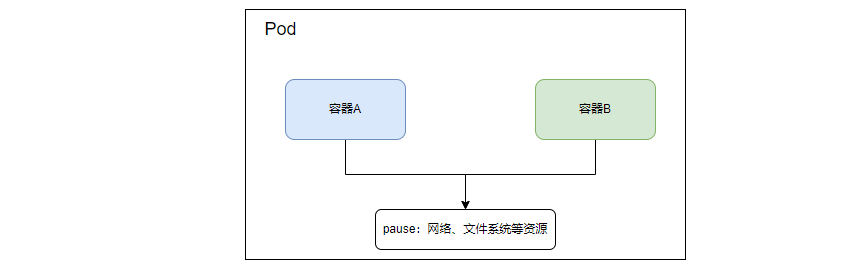
Pod(容器组)是 Kubernetes 中最小的可部署单元。k8s中所有的操作都是封装一个个pod,哪怕是让k8s执行一条最最简单的命令,也是封装一个pod,然后运行在pod上面的。
一个 Pod(容器组)包含了一个应用程序容器(某些情况下是多个容器)、存储资源、一个唯一的网络 IP 地址、以及一些确定容器该如何运行的选项。Pod 容器组代表了 Kubernetes 中一个独立的应用程序运行实例,该实例可能由单个容器或者几个紧耦合在一起的容器组成。所谓紧耦合,比如我们的应用程序和mysql,看上去是通过网络去调用,实际上耦合程度并没那么高。但是kafka和zookeeper就属于紧耦合,kafka缺不了zookeeper。(老版本)
Kubernetes 集群中的 Pod 存在如下两种使用途径:
一个 Pod 中只运行一个容器。
"one-container-per-pod" 是 Kubernetes 中最常见的使用方式。此时,可以认为 Pod 容器组是该容器的 wrapper,Kubernetes 通过 Pod 管理容器,而不是直接管理容器。
一个 Pod 中运行多个需要互相协作的容器。
您可以将多个紧密耦合、共享资源且始终在一起运行的容器编排在同一个 Pod 中,可能的情况有:kafka和zookeeper。
副本
一个 Pod 可以被复制成多份,每一份可被称之为一个“副本”,这些“副本”除了一些描述性的信息(Pod 的名字、uid 等)不一样以外,其它信息都是一样的,譬如 Pod 内部的容器、容器数量、容器里面运行的应用等的这些信息都是一样的,这些副本提供同样的功能。
Pod 的“控制器”通常包含一个名为 “replicas” 的属性。“replicas”属性则指定了特定 Pod 的副本的数量,当当前集群中该 Pod 的数量与该属性指定的值不一致时,k8s 会采取一些策略去使得当前状态满足配置的要求。
控制器
当 Pod 被创建出来,Pod 会被调度到集群中的节点上运行,Pod 会在该节点上一直保持运行状态,直到进程终止、Pod 对象被删除、Pod 因节点资源不足而被驱逐或者节点失效为止。Pod 并不会自愈,当节点失效,或者调度 Pod 的这一操作失败了,Pod 就该被删除。如此,单单用 Pod 来部署应用,是不稳定不安全的。
Kubernetes 使用更高级的资源对象 “控制器” 来实现对Pod的管理。控制器可以为您创建和管理多个 Pod,管理副本和上线,并在集群范围内提供自修复能力。 例如,如果一个节点失败,控制器可以在不同的节点上调度一样的替身来自动替换 Pod。
控制器有分为多种类型:
适用于无状态服务
replicationController(RC)
Replication Controller 简称 RC,RC 是 Kubernetes 系统中的核心概念之一,简单来说,RC 可以保证在任意时间运行 Pod 的副本数量,能够保证 Pod 总是可用的。如果实际 Pod 数量比指定的多那就结束掉多余的,如果实际数量比指定的少就新启动一些Pod,当 Pod 失败、被删除或者挂掉后,RC 都会去自动创建新的 Pod 来保证副本数量,所以即使只有一个 Pod,我们也应该使用 RC 来管理我们的 Pod。可以说,通过 ReplicationController,Kubernetes 实现了 Pod 的高可用性。在 v1.11 版本废弃.
ReplicaSet(RS)
RS 跟 RC 没有本质的不同,只是名字不一样,并且 RS 支持集合式的 selector。也就是可以指定某一个pod进行扩容伸缩。
Deployment
工作中定义无状态控制器,直接选择Deployment即可 你只需要在 Deployment 中描述你想要的目标状态是什么,Deployment controller 就会帮你将 Pod 和 Replica Set 的实际状态改变到你的目标状态。你可以定义一个全新的 Deployment,也可以创建一个新的替换旧的 Deployment。支持滚动升级、平滑扩容和回滚、暂停和恢复等等。
适用于有状态服务
为什么专门要针对有状态和无状态服务分别进行控制呢?比如扩容或者回退,删除一个pod,由于pod是独立的网络,那么原来的网络和文件都没有了,导致某个应用就找不到了,数据也找不到了。或者是比如redis集群,必须有master和slave节点,是有顺序问题的,先创建master再创建slave,那么这些都是有状态的。
StatefulSet:专门针对有状态服务进行部署的一个控制器。
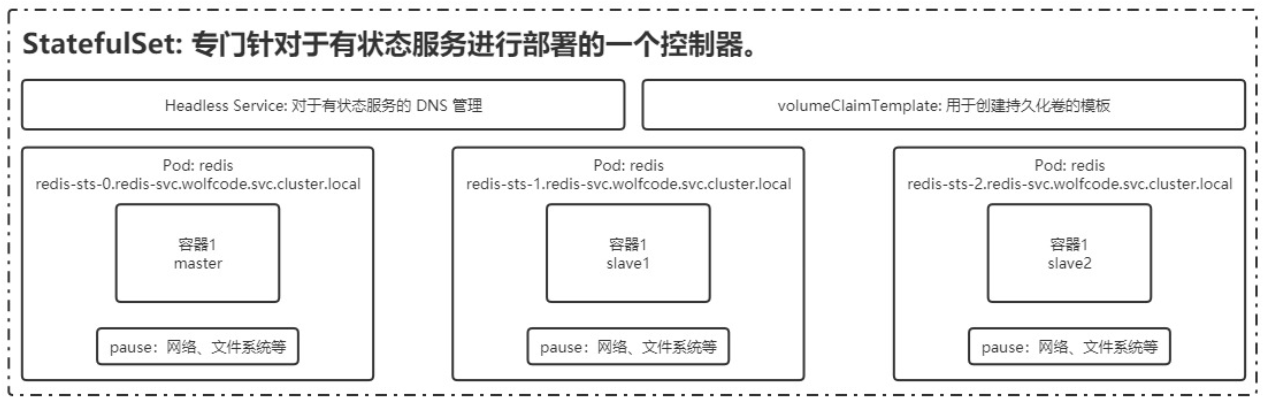
如上,通过headless services来做DSN管理和通过volumeClaimTemplate来做持久化卷的模版,来保证了网络和文件系统的存储问题。
DaemonSet
保证在每个 Node 上都运行一个容器副本,常用来部署一些集群的日志、监控或者其他系统管理应用。典型的应用包括: 日志收集,比如 fluentd,logstash 等
系统监控,比如 Prometheus Node Exporter,collectd,New Relic agent,Ganglia gmond 等
系统程序,比如 kube-proxy, kube-dns, glusterd, ceph 等
服务发现
涉及到两个概念,一个是service,一个是ingress。
service
“Service” 简写 “svc”。Pod 不能直接提供给外网访问,而是应该使用 service。Service 就是把 Pod 暴露出来提供服务,Service 才是真正的“服务”,它的中文名就叫“服务”。
可以说 Service 是一个应用服务的抽象,定义了 Pod 逻辑集合和访问这个 Pod 集合的策略。Service 代理 Pod 集合,对外表现为一个访问入口,访问该入口的请求将经过负载均衡,转发到后端 Pod 中的容器。
ingress
Ingress 可以提供外网访问 Service 的能力。可以把某个请求地址映射、路由到特定的 service。
ingress 需要配合 ingress controller 一起使用才能发挥作用,ingress 只是相当于路由规则的集合而已,真正实现路由功能的,是 Ingress Controller,ingress controller 和其它 k8s 组件一样,也是在 Pod 中运行。
它们的关系如下图:
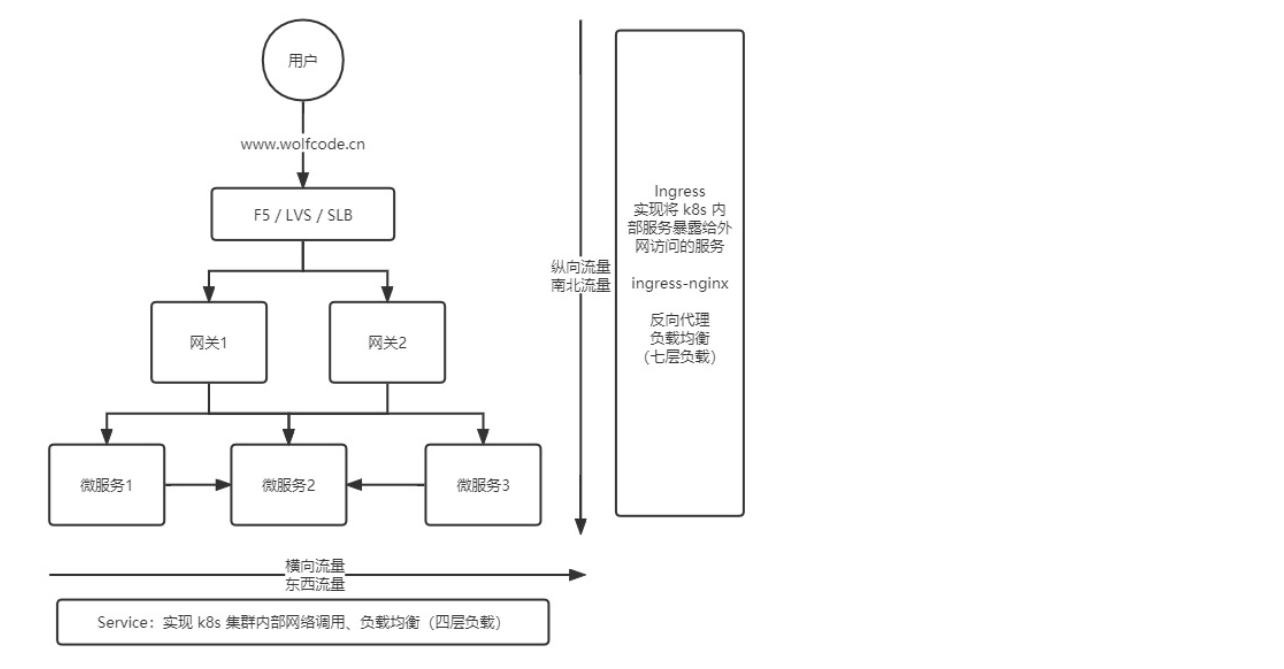
这里涉及到横向流量和纵向流量。
那他们之间是如何调用的呢?比如微服务1如何和微服务2进行通信调用呢?
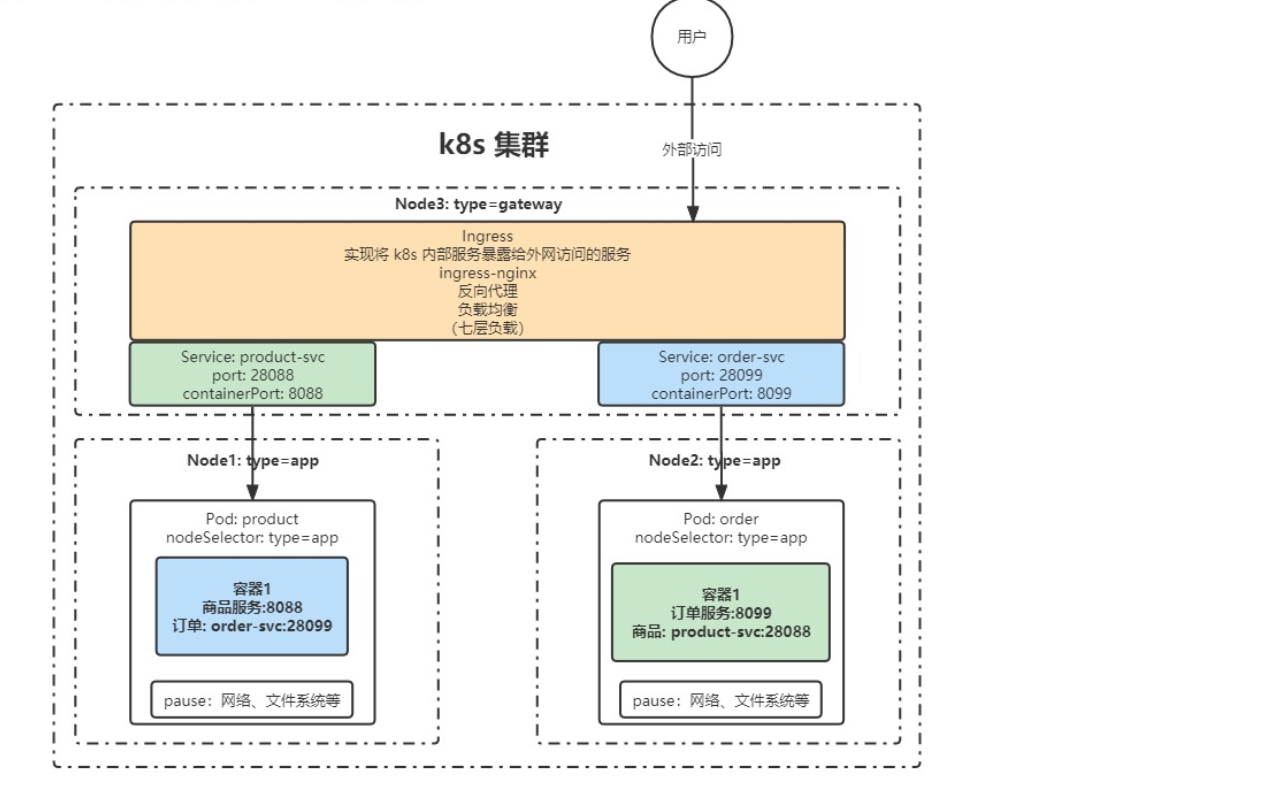
- Node1搭载了一个pod,pod中又搭载了商品服务,向外暴露端口为8088,Node2中搭载了订单服务,向外暴露端口为8099.
- node3中有多个pod,其中两个pod分别只是映像了商品和订单服务,同一个node中,所以他们可以互相访问。
- node3中又通过ingress来承接外部用户的访问。
也就是 service为了解决东西流量,负责服务和服务之间的访问,而ingress解决南北流量,负责用户访问到具体的服务。
配置和存储
主要涉及到一下概念:
volume
数据卷,共享 Pod 中容器使用的数据。用来放持久化的数据,比如数据库数据。
CSI
CSI 规范定义了存储提供商实现 CSI 兼容的 Volume Plugin 的最小操作集和部署建议。CSI 规范的主要焦点是声明 Volume Plugin 必须实现的接口。
ConfigMap
用来放配置,与 Secret 是类似的,只是 ConfigMap 放的是明文的数据,Secret 是密文存放。
Secret
Secret 解决了密码、token、密钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者 Pod Spec 中。Secret 可以以 Volume 或者环境变量的方式使用。
DownwardAPI
downwardAPI 这个模式和其他模式不一样的地方在于它不是为了存放容器的数据也不是用来进行容器和宿主机的数据交换的,而是让 pod 里的容器能够直接获取到这个 pod 对象本身的一些信息。
搭建K8s集群
老铁,不要用虚拟器了,云服务器花不了几块钱,你使用按流量计费的,三个node搭载集群也就一杯奈雪。
常用命令
做个备忘录
资源操作
创建对象
$ kubectl create -f ./my-manifest.yaml # 创建资源 $ kubectl create -f ./my1.yaml -f ./my2.yaml # 使用多个文件创建资源 $ kubectl create -f ./dir # 使用目录下的所有清单文件来创建资源 $ kubectl create -f https://git.io/vPieo # 使用 url 来创建资源 $ kubectl run nginx --image=nginx # 启动一个 nginx 实例 $ kubectl explain pods,svc # 获取 pod 和 svc 的文档 # 从 stdin 输入中创建多个 YAML 对象 $ cat <<EOF | kubectl create -f - apiVersion: v1 kind: Pod metadata: name: busybox-sleep spec: containers: - name: busybox image: busybox args: - sleep - "1000000" --- apiVersion: v1 kind: Pod metadata: name: busybox-sleep-less spec: containers: - name: busybox image: busybox args: - sleep - "1000" EOF # 创建包含几个 key 的 Secret $ cat <<EOF | kubectl create -f - apiVersion: v1 kind: Secret metadata: name: mysecret type: Opaque data: password: $(echo "s33msi4" | base64) username: $(echo "jane" | base64) EOF显示和查找资源
# Get commands with basic output $ kubectl get services # 列出所有 namespace 中的所有 service $ kubectl get pods --all-namespaces # 列出所有 namespace 中的所有 pod $ kubectl get pods -o wide # 列出所有 pod 并显示详细信息 $ kubectl get deployment my-dep # 列出指定 deployment $ kubectl get pods --include-uninitialized # 列出该 namespace 中的所有 pod 包括未初始化的 # 使用详细输出来描述命令 $ kubectl describe nodes my-node $ kubectl describe pods my-pod $ kubectl get services --sort-by=.metadata.name # List Services Sorted by Name # 根据重启次数排序列出 pod $ kubectl get pods --sort-by='.status.containerStatuses[0].restartCount' # 获取所有具有 app=cassandra 的 pod 中的 version 标签 $ kubectl get pods --selector=app=cassandra rc -o \ jsonpath='{.items[*].metadata.labels.version}' # 获取所有节点的 ExternalIP $ kubectl get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="ExternalIP")].address}' # 列出属于某个 PC 的 Pod 的名字 # “jq”命令用于转换复杂的 jsonpath,参考 https://stedolan.github.io/jq/ $ sel=${$(kubectl get rc my-rc --output=json | jq -j '.spec.selector | to_entries | .[] | "\(.key)=\(.value),"')%?} $ echo $(kubectl get pods --selector=$sel --output=jsonpath={.items..metadata.name}) # 查看哪些节点已就绪 $ JSONPATH='{range .items[*]}{@.metadata.name}:{range @.status.conditions[*]}{@.type}={@.status};{end}{end}' \ && kubectl get nodes -o jsonpath="$JSONPATH" | grep "Ready=True" # 列出当前 Pod 中使用的 Secret $ kubectl get pods -o json | jq '.items[].spec.containers[].env[]?.valueFrom.secretKeyRef.name' | grep -v null | sort | uniq更新资源
$ kubectl rolling-update frontend-v1 -f frontend-v2.json # 滚动更新 pod frontend-v1 $ kubectl rolling-update frontend-v1 frontend-v2 --image=image:v2 # 更新资源名称并更新镜像 $ kubectl rolling-update frontend --image=image:v2 # 更新 frontend pod 中的镜像 $ kubectl rolling-update frontend-v1 frontend-v2 --rollback # 退出已存在的进行中的滚动更新 $ cat pod.json | kubectl replace -f - # 基于 stdin 输入的 JSON 替换 pod # 强制替换,删除后重新创建资源。会导致服务中断。 $ kubectl replace --force -f ./pod.json # 为 nginx RC 创建服务,启用本地 80 端口连接到容器上的 8000 端口 $ kubectl expose rc nginx --port=80 --target-port=8000 # 更新单容器 pod 的镜像版本(tag)到 v4 $ kubectl get pod mypod -o yaml | sed 's/\(image: myimage\):.*$/\1:v4/' | kubectl replace -f - $ kubectl label pods my-pod new-label=awesome # 添加标签 $ kubectl annotate pods my-pod icon-url=http://goo.gl/XXBTWq # 添加注解 $ kubectl autoscale deployment foo --min=2 --max=10 # 自动扩展 deployment “foo”修补资源
$ kubectl patch node k8s-node-1 -p '{"spec":{"unschedulable":true}}' # 部分更新节点 # 更新容器镜像; spec.containers[*].name 是必须的,因为这是合并的关键字 $ kubectl patch pod valid-pod -p '{"spec":{"containers":[{"name":"kubernetes-serve-hostname","image":"new image"}]}}' # 使用具有位置数组的 json 补丁更新容器镜像 $ kubectl patch pod valid-pod --type='json' -p='[{"op": "replace", "path": "/spec/containers/0/image", "value":"new image"}]' # 使用具有位置数组的 json 补丁禁用 deployment 的 livenessProbe $ kubectl patch deployment valid-deployment --type json -p='[{"op": "remove", "path": "/spec/template/spec/containers/0/livenessProbe"}]'编辑资源
$ kubectl edit svc/docker-registry # 编辑名为 docker-registry 的 service $ KUBE_EDITOR="nano" kubectl edit svc/docker-registry # 使用其它编辑器scale资源
$ kubectl scale --replicas=3 rs/foo # Scale a replicaset named 'foo' to 3 $ kubectl scale --replicas=3 -f foo.yaml # Scale a resource specified in "foo.yaml" to 3 $ kubectl scale --current-replicas=2 --replicas=3 deployment/mysql # If the deployment named mysql's current size is 2, scale mysql to 3 $ kubectl scale --replicas=5 rc/foo rc/bar rc/baz # Scale multiple replication controllers删除资源
$ kubectl delete -f ./pod.json # 删除 pod.json 文件中定义的类型和名称的 pod $ kubectl delete pod,service baz foo # 删除名为“baz”的 pod 和名为“foo”的 service $ kubectl delete pods,services -l name=myLabel # 删除具有 name=myLabel 标签的 pod 和 serivce $ kubectl delete pods,services -l name=myLabel --include-uninitialized # 删除具有 name=myLabel 标签的 pod 和 service,包括尚未初始化的 $ kubectl -n my-ns delete po,svc --all # 删除 my-ns namespace 下的所有 pod 和 serivce,包括尚未初始化的
Pod与集群
- 与运行的pod交互
$ kubectl logs my-pod # dump 输出 pod 的日志(stdout) $ kubectl logs my-pod -c my-container # dump 输出 pod 中容器的日志(stdout,pod 中有多个容器的情况下使用) $ kubectl logs -f my-pod # 流式输出 pod 的日志(stdout) $ kubectl logs -f my-pod -c my-container # 流式输出 pod 中容器的日志(stdout,pod 中有多个容器的情况下使用) $ kubectl run -i --tty busybox --image=busybox -- sh # 交互式 shell 的方式运行 pod $ kubectl attach my-pod -i # 连接到运行中的容器 $ kubectl port-forward my-pod 5000:6000 # 转发 pod 中的 6000 端口到本地的 5000 端口 $ kubectl exec my-pod -- ls / # 在已存在的容器中执行命令(只有一个容器的情况下) $ kubectl exec my-pod -c my-container -- ls / # 在已存在的容器中执行命令(pod 中有多个容器的情况下) $ kubectl top pod POD_NAME --containers # 显示指定 pod 和容器的指标度量 - 与节点和集群交互
$ kubectl cordon my-node # 标记 my-node 不可调度 $ kubectl drain my-node # 清空 my-node 以待维护 $ kubectl uncordon my-node # 标记 my-node 可调度 $ kubectl top node my-node # 显示 my-node 的指标度量 $ kubectl cluster-info # 显示 master 和服务的地址 $ kubectl cluster-info dump # 将当前集群状态输出到 stdout $ kubectl cluster-info dump --output-directory=/path/to/cluster-state # 将当前集群状态输出到 /path/to/cluster-state # 如果该键和影响的污点(taint)已存在,则使用指定的值替换 $ kubectl taint nodes foo dedicated=special-user:NoSchedule
资源类型和别名
用的常见的,比较多的
| 类型 | 别名 | 备注 |
|---|---|---|
| pods | po | |
| deployments | deploy | |
| services | svc | |
| namespace | ns | |
| nodes | no |

