
是谁,连续几天占据各大社交媒体的头条。
是谁,能让马斯克在X上评论“人类玩球了”(gg humans)。
是谁,能让大A股单独开辟一个版块。
我们肯定还记得,OpenAI在2022年11月30号发布一款聊天机器人程序,就是ChatGPT3.5,能完成撰写邮件、视频脚本、文案、翻译、代码,写论文等任务,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流。当时在整个地球引起了轰动,多少人担心AI即将统治地球。
接着各大平台进入语言模型行列,力争能分一杯羹,包括但不限于百度的文心一言、腾讯的混元,当然还有google的Gemini,以及各大巨头还在研发中的语言模型。
跨越一年多的历程,ChatGPT也发布了4.0,基于GPT-4的最新和最强大的自然语言生成模型,已经可以满足日常需求,但就在24年的2月15号,google发布了Gemini1.5Pro,号称可以碾压GPT-4,它可以一次性处理超过70万个单词文本、3万行代码、11个小时的音频、不超过1个小时的视频,然后指挥它干活。想想都刺激,顿时媒体眼光立马被吸引过去。
但是,4个小时后,Gemini1.5Pro热度顿时浇灭,大众目光立马移走。因为OpenAI在同一天,向世界扔下一枚炸弹,发布了Sora这个大利器。从发布后到当前博客撰写当天,热度从未减少。
Sora :简单来说,就是它可以根据你传入的文本来生成一镜到底的一分钟的高保真视频。Sora并非第一个视频生成模型,在之前,文生视频平台也有,比如runway公司的Gen-2模型、Pika公司的Pika模型,stability公司的stable video,都是在23年就已经发布,但是他们的时长没有一个超过18秒,大多数都停留在3、4秒,且生成的视频大多模式、帧与帧之间不太连贯,略微卡顿。而Sora上来就是王炸,60秒,一镜到底(张艺谋都说一镜到底在拍电影中都很不容易)
比如下面:

你能想象,这是AI生成的?还需要导演、剪辑、摄像、演员么?怪不得马斯克说,gg humans。

Sora厉害之处
视频生成模型,需要对现实世界物理规律的要求很高,需要正确表现事物之间的相互作用,比如Demo中的水中倒影,主角耳环随着步伐有规律的摆动,而且镜头转场中的连贯性,sora都表现的极为出色。
当然,Sora还能生成不同的宽高比和分辨率的视频,比如宽屏为1920X1080P,竖屏1080X1920P,以及中间的所有分辨率,都可以生成,这就表明了可以生成不同的视频来视频不同的设备。实现了采样灵活性。

传统的视频和图像生成通常需要将视频素材裁剪或修剪为标准大小,而Sora则以原生大小对数据进行训练。这种方式带来了更高的灵活性和优化的取景和构图,使得生成的视频更加自然和逼真。比如下图,就是截取视频的图片,明显可以感觉右图的取景效果更佳。

Sora的强大功能得益于其先进的程序架构和训练逻辑。通过不断地训练和优化,Sora能够逐渐掌握从文本到视频的映射关系,生成高质量的视频内容。
Sora的原理
Sora的原理基于Transformer和Diffusion结构,这是一种全新的视频生成方法。首先,Sora会对输入的文本进行解析,将其转化为高维向量组成的序列。这个序列中的每一个元素被称为patch,与语言模型中的token类似。但是,由于视频具有时序、长度和宽度等多个维度,因此patch化后的视频数据形成了一个三维空间。为了处理这个三维空间,Sora采用了一个压缩模型,将其转化为单维向量序列,以便Transformer进行预测。
在训练过程中,Sora通过不断地学习和优化,逐渐掌握了从文本到视频的映射关系。它可以根据用户提供的文本提示,生成具有逼真画质的视频。这些视频不仅包含了用户指定的角色和动作,还能模拟真实物理世界中的运动规律,呈现出令人惊叹的视觉效果。
Diffusion就是扩散模型,扩散模型的灵感来源于非平衡热力学,生成图像的过程中,就像是把一滴墨水在水中扩散的过程进行倒放。具体参见 图解Diffusion扩散模型
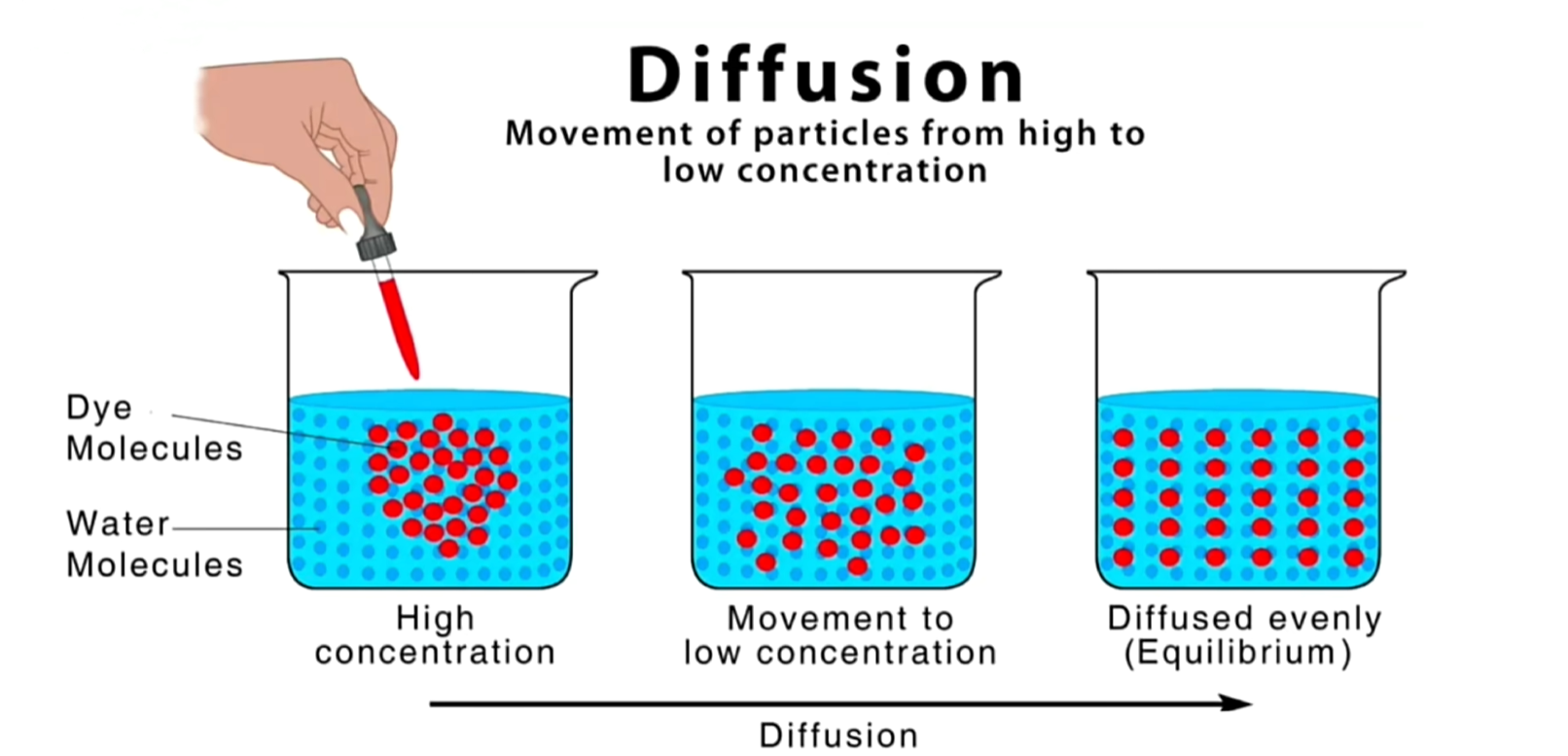 具体来说,扩散模型就是从噪声图像中逐步去除噪声来生成满足要求的图像。
具体来说,扩散模型就是从噪声图像中逐步去除噪声来生成满足要求的图像。
Transformer模型是当前主流文本生成模型的根基,包括GPT、文心一言、Claude、PLUG等等,原始的Transformer架构包括编码器和解码器,输出文本开始会被token化,也就是被拆分成一个个基本单位。
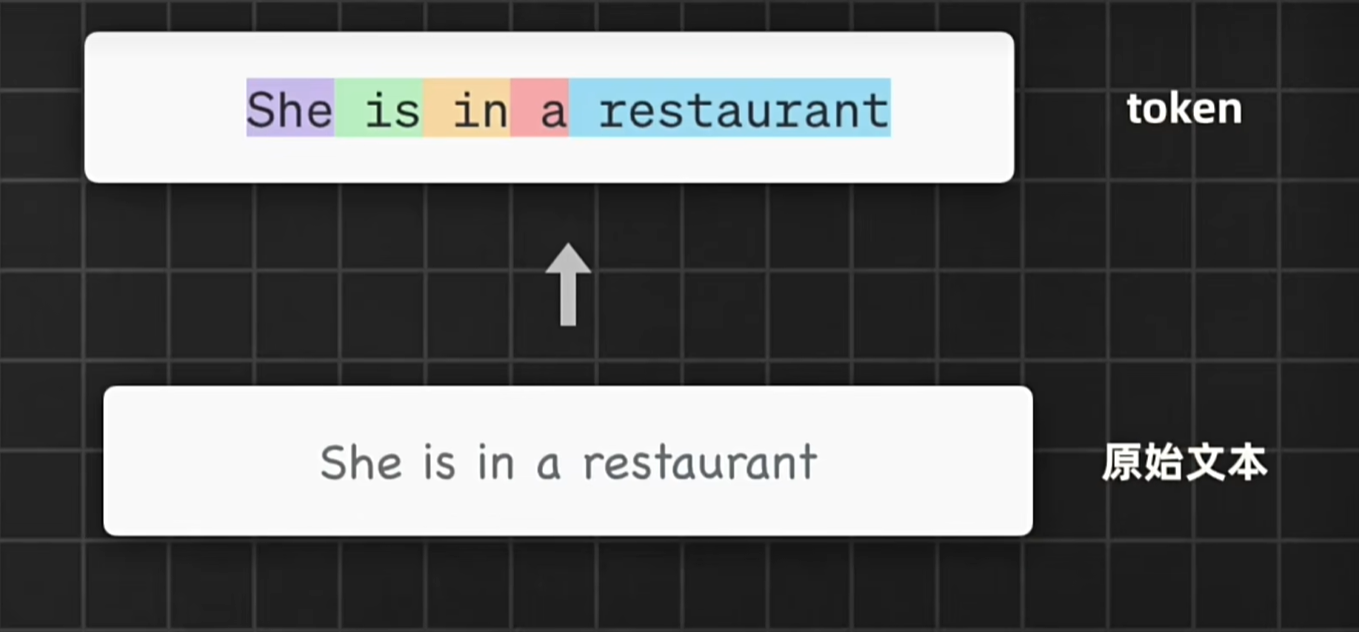 其中的编码器会负责把输入转化成一个种更抽象的向量表示,里面保留了输入文本的词汇信息和顺序关系,也捕捉了语法语义上的关键特征。
其中的编码器会负责把输入转化成一个种更抽象的向量表示,里面保留了输入文本的词汇信息和顺序关系,也捕捉了语法语义上的关键特征。
具体感兴趣的可移步一文读懂 Transformer 神经网络模型
趋势
随着Sora的发布,人工智能文生视频领域迎来了新的发展机遇。未来,Sora有望在电影、游戏、广告等多个领域发挥重要作用。艺术家和电影制片人可以借助Sora快速生成高质量的视觉效果,提高工作效率和创作质量。同时,Sora还有可能推动视频创作行业的变革,使得更多人能够参与到视频创作中来。
此外,随着技术的不断进步,Sora的性能和功能还将得到进一步提升。例如,它可能会支持更复杂的场景和动作,提高视频生成的逼真度和自然度。同时,Sora还有可能在多模态交互方面取得突破,实现文本、语音、图像等多种信息形式的融合和交互。
个人看法
我个人的看法,Sora的发布标志着人工智能在文生视频领域的重要突破。它以其独特的原理和功能,为我们提供了一个全新的视频创作工具。随着技术的不断进步和应用领域的拓展,Sora有望在未来发挥更大的作用,推动视频创作行业的创新和发展。
在各种行业,比如博主之前的外贸行业,五点描述你可以通过ChatGPT生成,产品的视频介绍你可以通过Sora生成,极大的节省了人力。
在电影行业,未来制片公司,可能不需要演员就能拍电影,因为Sora采用了Dall.E3中的重述技术(2023年9月21日,OpenAI发布了文生图模型),所以能够更好的遵循用户的文本描述,也有这极强的扩展性,后续电影,可能就需要把剧本录入,就可以生成视频、电影、电视剧。不光场景设计细腻、角色的表情也是栩栩如生。你可以自己创造电影,人人都是导演不再是一句空话。
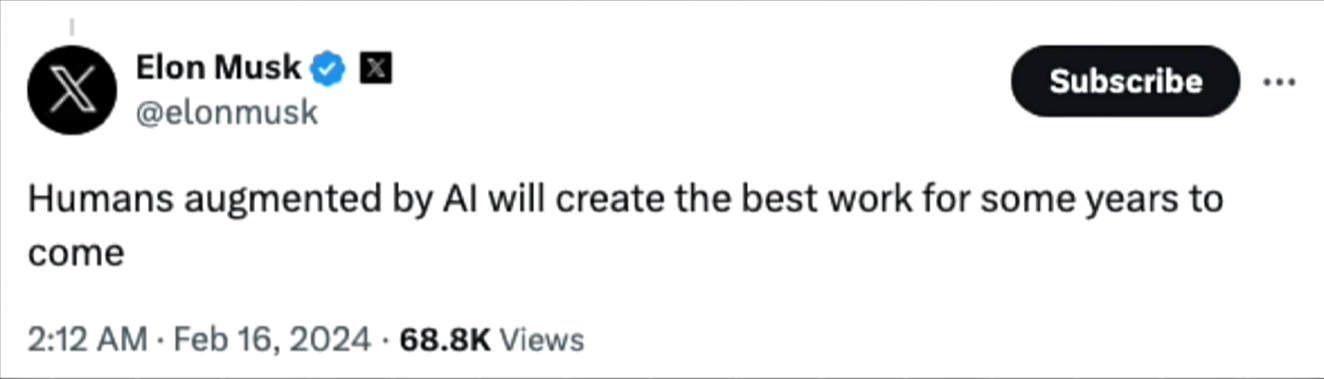
马斯克还说,有了AI加持的人类将在未来几年里创造出最好的作品。
现阶段缺点
当然现阶段Sora并非完美的,目前也是有一定缺陷。
- 比如该模型会混淆提示的空间细节,且难以准确的模拟复杂场景中的物理现象,比如有个生成吹生日蜡烛的视频,当庆生者吹完蜡烛后,蜡烛并未熄灭,不符合常理。(视频就不放了)
- 目前也是无法理解事例中包含的因果关系,比如有个视频,就是酒杯摔碎,但是液体的流动和玻璃的破裂关系并没有把握好。
当然,如同文心一言刚推出时很多搞笑图片一样,Sora中的视频,也是有这不少的翻车现场。如: 7个Sora生成的翻车视频
最后
关心股票的朋友,大概心有体会,最近几天关于Sora板块的股票,都是强势涨停,说明大家对Sora还是很看好的。
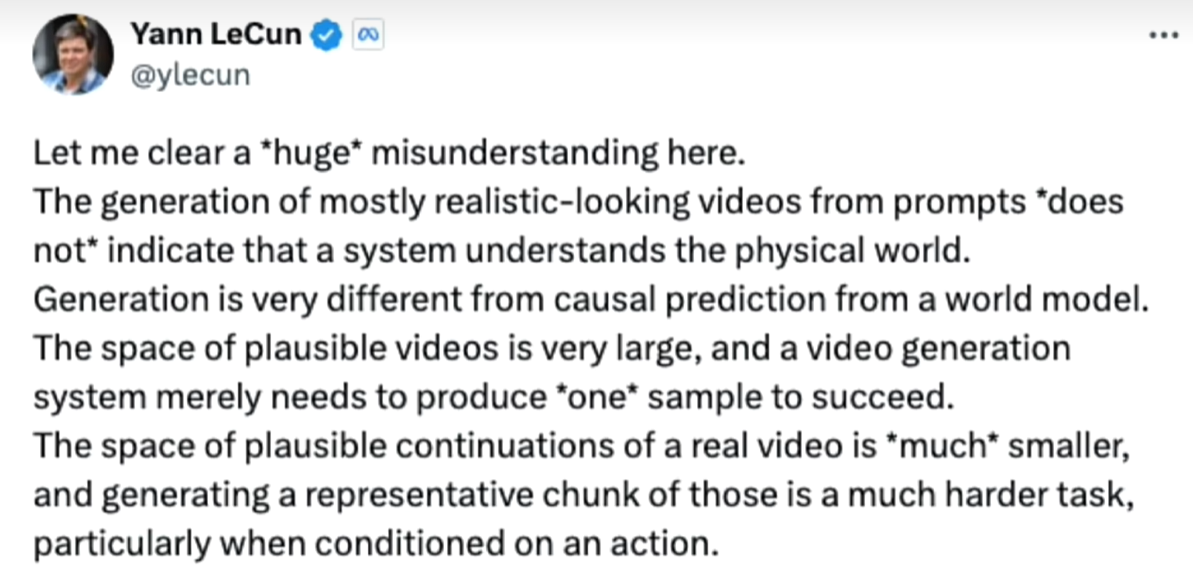
虽然看上去生成如同电影一样毫无违和感的视频,还有一段距离,比如图灵奖获得者杨立昆就表示Sora生成看起来像现实的视频,距离模型真正理解物理世界还远得很。
经过后续更大规模的训练后,Sora肯定会出现精确模拟现实世界的智能涌现,2020年GPT-3推出的时候,生成的文本也是存在各种硬伤,但是经过近些年的不断训练,展现出了惊人的情境学习能力。就像是阿米尔汗的《我滴个神》电影一样,一个从来没有来过地球的外星人,在持续不断的学习、生活下,对地球上的各种现象的推断、模仿达到惊人的准确,甚至知道如何赚取小费,比地球人还像地球人。
有生之年,我们一定可以看到,拭目以待。
我们作为普通人,只能不断的学习,强化自己,才会不被淘汰,不然,会遭到这个世界的毁灭,而并不自知。


