

春节期间,DeepSeek火遍全球,登上各个榜单的榜首。但是他们的官网,经常崩溃,一方面是被国外的网络攻击,另一方面是使用的用户实在是太多了,经常就导致问一两句话就“服务器繁忙”。
科普
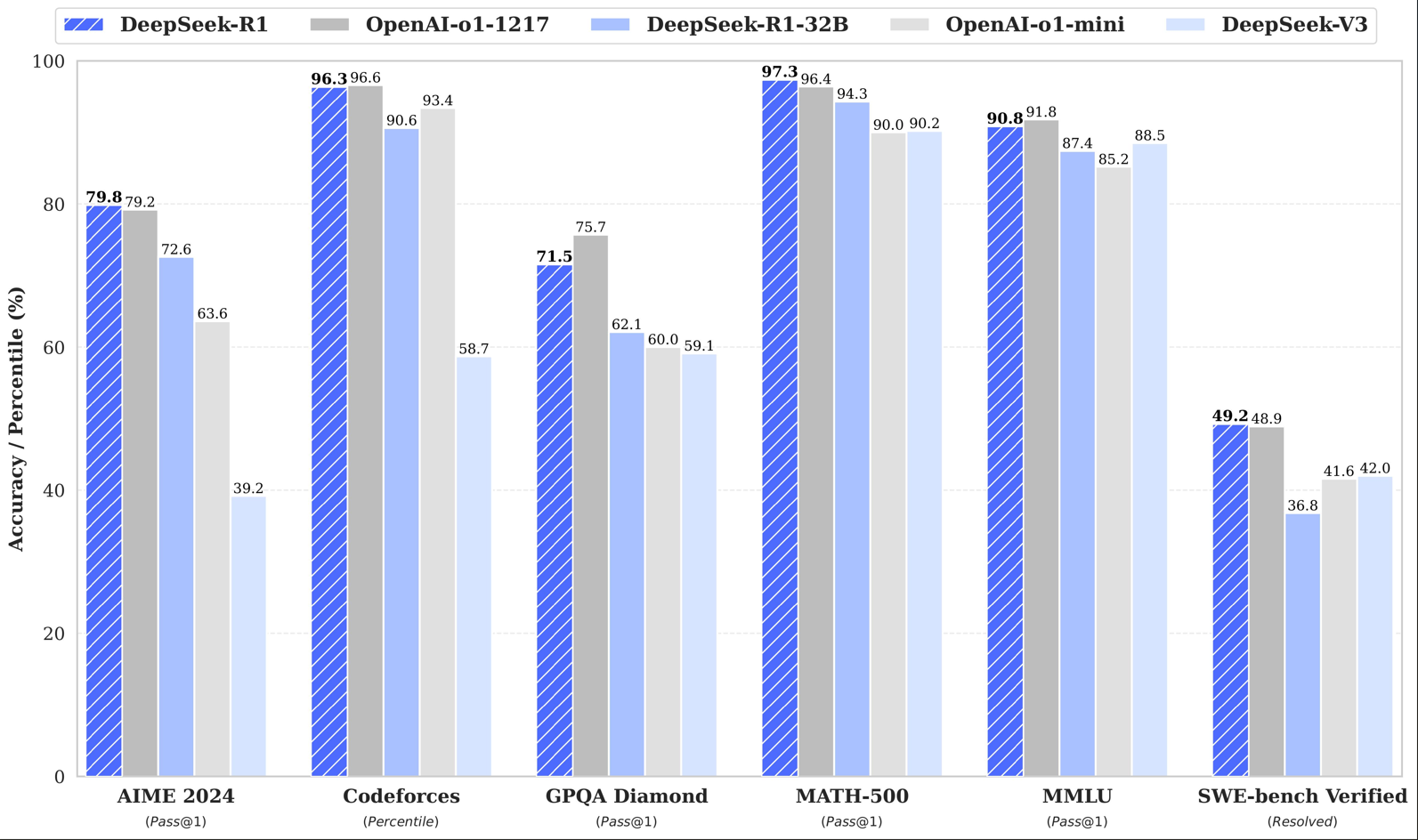
本次火出圈的模型,是deepseek的R1模型(大家注意不要下错了),他之前也是发布了很多的模型,可以在github官网主页里面看到 github-deepseek 在R1的模型里面,还有很多量化版本。R1的原始模型,实际上是671B的,这个参数量非常的大,一般的电脑根本就带不动,如果你本地部署的话,只能选择蒸馏模型,比如你电脑有4090的显卡,24G显存的,你可以带得动这个32B或者70B的,但这个和671B的根本就不是一个量级,毕竟是一个阉割的版本。如果你的使用需求,并非保密单位或者是什么严格的科研论文还没发表,不能对外泄漏的,否则就直接使用这个671B的这个满血模型,处理文字的能力,是非常非常大的,如果要使用671B的这个DeepSeek—R1的话,强烈推荐API的方式去部署。
在R1的模型里面,还有很多量化版本。R1的原始模型,实际上是671B的,这个参数量非常的大,一般的电脑根本就带不动,如果你本地部署的话,只能选择蒸馏模型,比如你电脑有4090的显卡,24G显存的,你可以带得动这个32B或者70B的,但这个和671B的根本就不是一个量级,毕竟是一个阉割的版本。如果你的使用需求,并非保密单位或者是什么严格的科研论文还没发表,不能对外泄漏的,否则就直接使用这个671B的这个满血模型,处理文字的能力,是非常非常大的,如果要使用671B的这个DeepSeek—R1的话,强烈推荐API的方式去部署。
本文就手把手教大家一下,如何在我们的本地去使用deepseek,而且非常流畅的去使用它。一般来说有两种:
- API部署,满血版本,不卡顿,功能最强大。
- 本地算力部署,数据比较安全,完全免费,如果你有比较好的显卡,可以在本地算力里面跑。
API方式部署
使用华为云+硅基流动一起部署API。
- 先进入模型广场: https://cloud.siliconflow.cn/models ,如果没有注册可以先注册。注册好之后就直接赠送2000W的token。好,继续科普下:
那么两千万的token是什么概念?Token是什么? Token是文本的基本单位:可以是单词、子词(如"unhappy"拆分为"un"和"happy")或标点符号。例如,中文通常以字或词为单位,英文可能拆分更细。 量化文本长度:一段文本的token数量代表其复杂度和信息量。例如: 英文:1个token ≈ 4个字母(平均); 中文:1个token ≈ 1-2个汉字(取决于分词方式)。
所以,赠送的token数量绝对是够你日常的使用了。若模型支持单次处理2000万token(即约2000万词/字),这属于超长上下文能力。具体场景举例: 长文档分析:直接处理整本书(例如《哈利·波特》约100万词)、长篇法律合同、学术论文。 复杂任务:跨多篇文档的信息整合(如企业年报分析)、超长代码库理解。 生成能力:生成数万字的连贯故事、报告或代码。
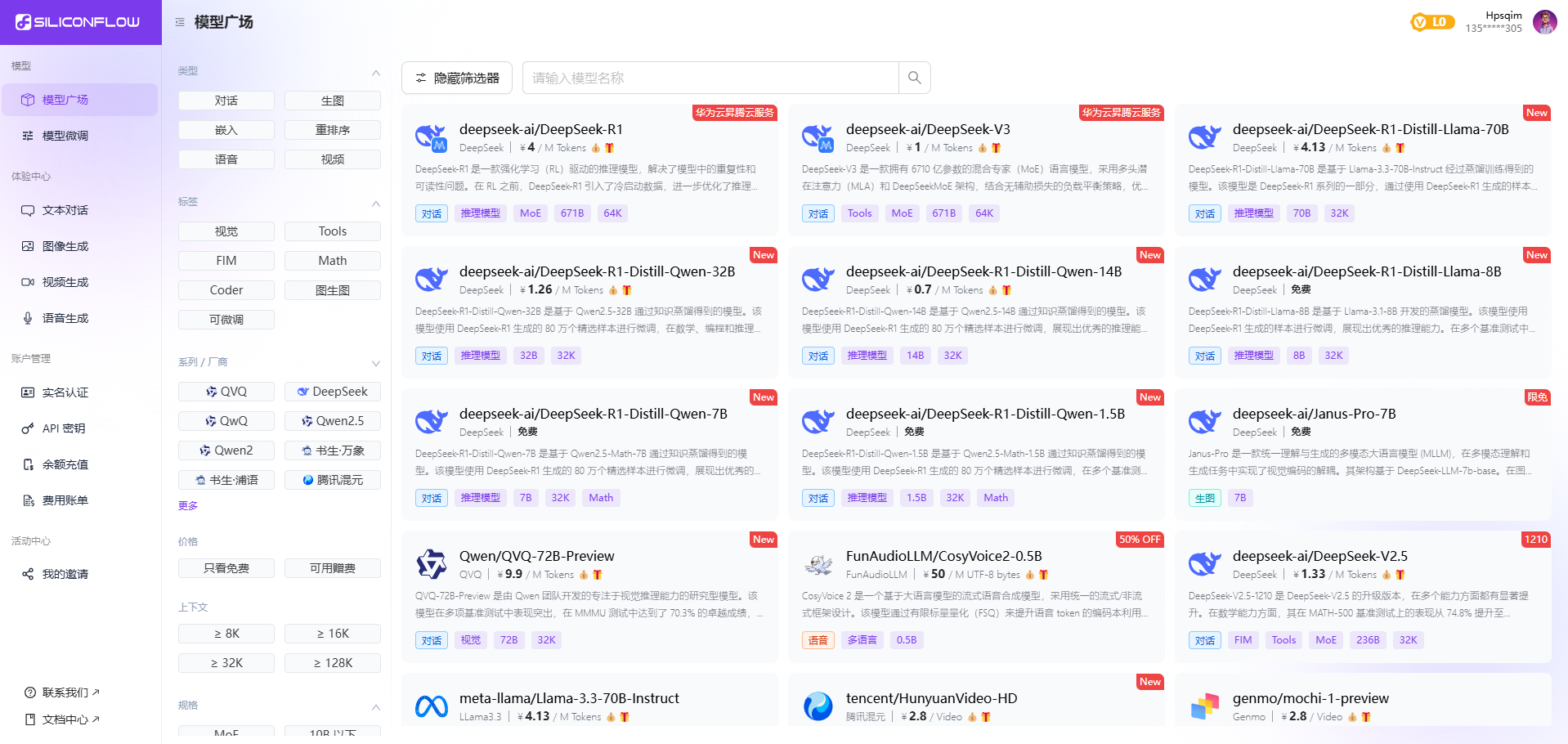
- 新建密钥
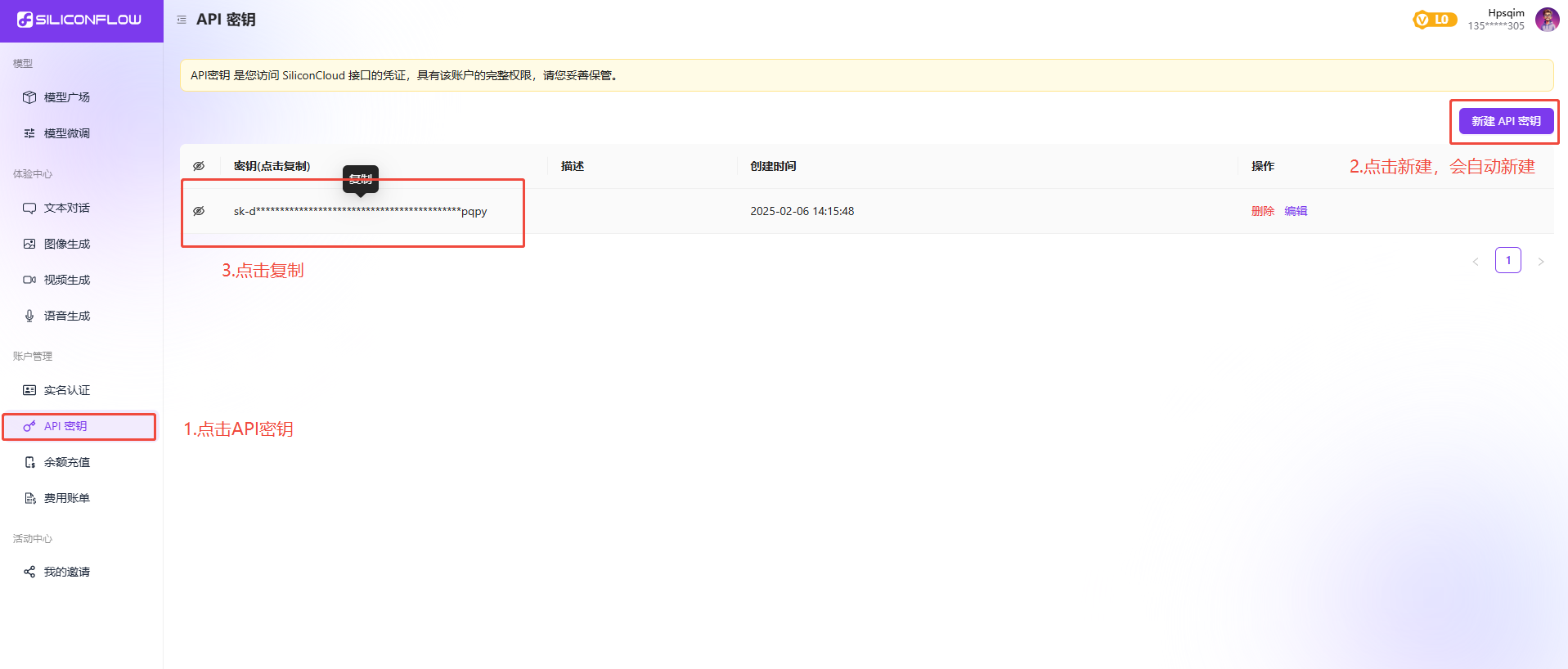
这样就相当于API就申请下来了,而且免费白嫖了2000w的token。
- 安装本地的客户端
类似的客户端有很多,比如Chatbox,Cherry-Studio,Ollama等等,我们就只需要安装其中一个即可,比如我们使用 Cherry-Studio 一步步下载安装完成后,打开的界面就是这样的。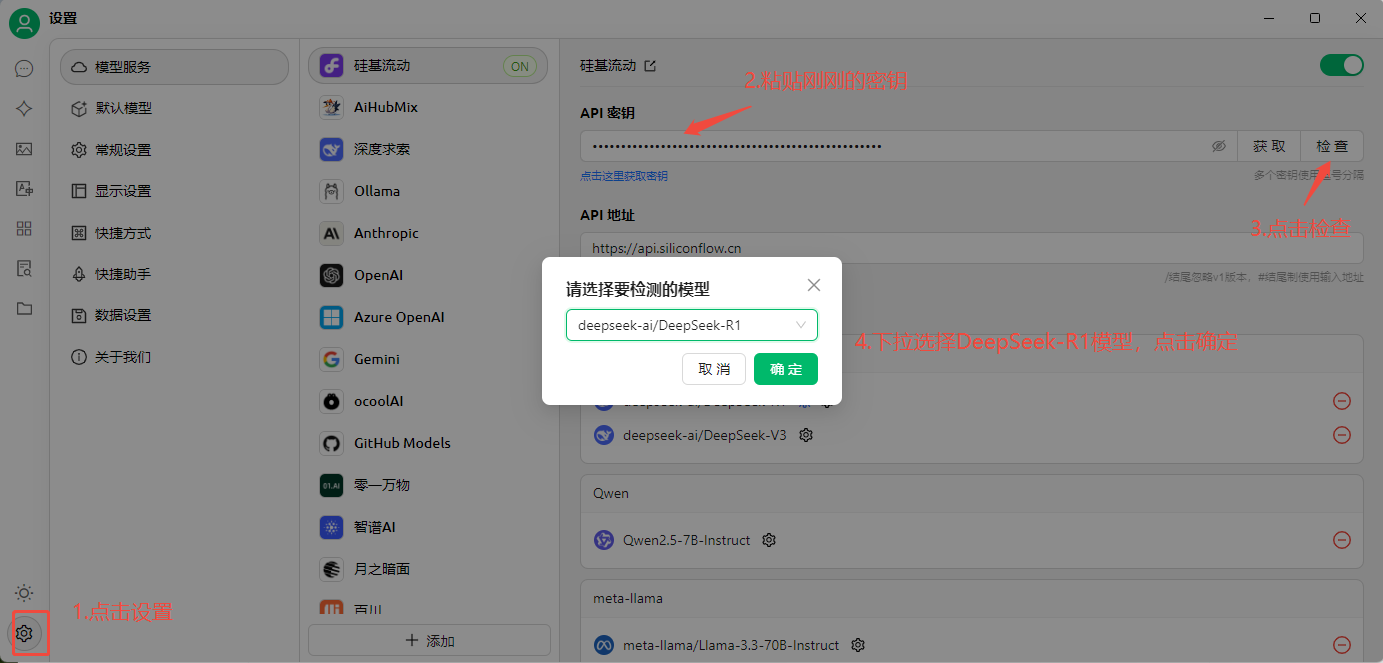
然后设置完成后,就可以选择对应的模型了:
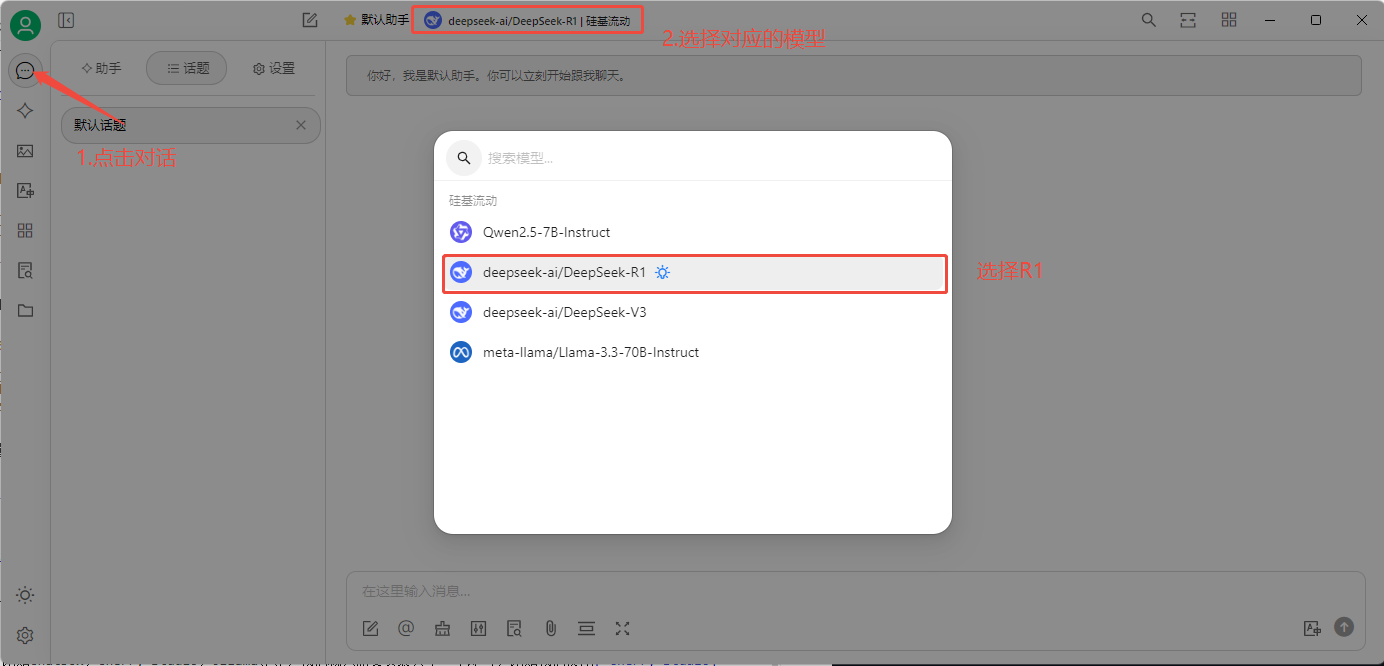
你就可以为所欲为了:
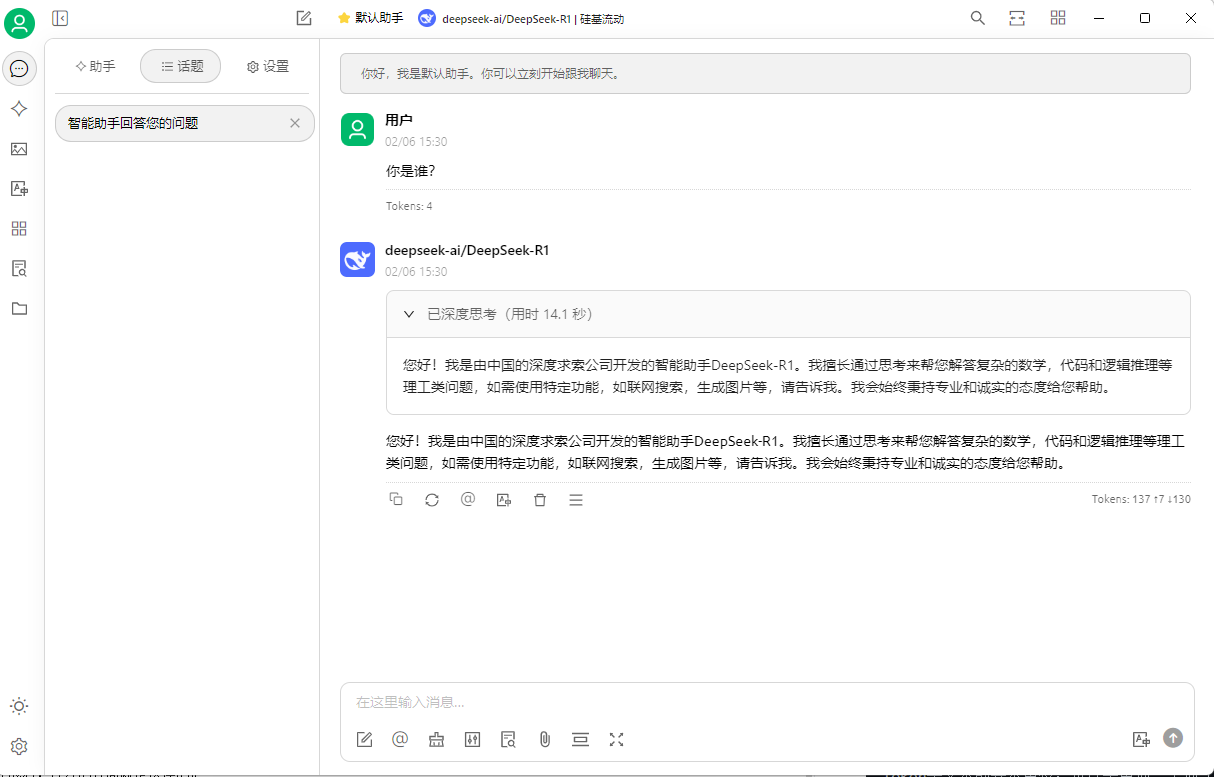
这样就可以使用api的方式进行满血模式,问问题的时候会有一个深度思考的过程,也会给你展示出来,我觉得这个思考的过程可能比答案本身给你的启示更大,我们可以看下AI平时是如何深度思考并回答我们的问题的。
本地算力无需联网的方式
现在部署根本不是问题,重点是本地硬件!!如果用了API,那就失去了本地的意义。多厉害的电脑就跑多厉害的模型,而且普通电脑是永远都跑不了满血版的,顶级的运算力永远都在顶级的配置上。所以,不太建立本地部署。 如果实在有需求,你按照以下初步流程吧,我电脑比较垃圾,都没有本地部署的欲望。
1.本地模型下载地址:https://ollama.com/library/deepseek-r1,点击download下载。
2.安装完成之后直接进行cmd,然后运行到ollama。
3.去官网下载相关的模型,根据你电脑的显存,当然这些都是阉割版本。

