
作为一名开发者,我们都知道,代码是解决问题的艺术。但当问题是“如何让 AI 像专家一样回答我的私域知识”时,传统的 AI 模型就有点力不从心了。它们可能会一本正经的“胡说八道”(幻觉),也可能根本不知道你的公司内部手册。
今天,我们就用大白话,结合关键代码和流程图,彻底扒开 RAG(Retrieval Augmented Generation,检索增强生成)的神秘面纱,看看它是怎么给 AI 插上“外部记忆”的翅膀的。
RAG是什么?AI的开卷考试策略
想象一下,你有一个超级聪明的学生(大语言模型 LLM),他平时学习很广(通用知识),但当被问到一些专业且具体的问题(比如你公司的“注销流程”)时,他可能会蒙圈。
RAG 的核心思想就是: 在学生回答问题之前,先给他发一份“小抄”或“参考资料”。学生拿到小抄后,就能结合自己的知识和这份小抄,给出精准的答案。这就好比给 AI 来了场“开卷考试”,而不是让它凭空瞎猜。
为什么要这么做?
- 解决“幻觉”:AI 不再“胡说八道”,回答有据可依。
- 实时性:你的知识库更新了,AI 也能立刻学习到最新信息。
- 专业性:让 AI 成为你领域的专家,而不是泛泛而谈。
所以这个非常适合公司、团队的内部知识库,比如PDF软件,就可以把相关的介绍放入里面去,后续有客诉问题可以直接进行知识库里面搜索,然后回答。也可以把公司的规章制度、员工手 册放入知识库中,有问题可以直接搜索回答,极大的节省时间。
RAG的核心流程:三步走战略
RAG 看起来很复杂,但核心就三步:
- 数据入库 (Ingestion):把你的知识“喂给”AI 的记忆系统。
- 问题检索 (Retrieval):当用户提问时,AI 知道去哪里“找小抄”。
- 生成答案 (Generation):AI 结合问题和小抄,生成最终回答。
让我们用一个简单的流程图来看一下:
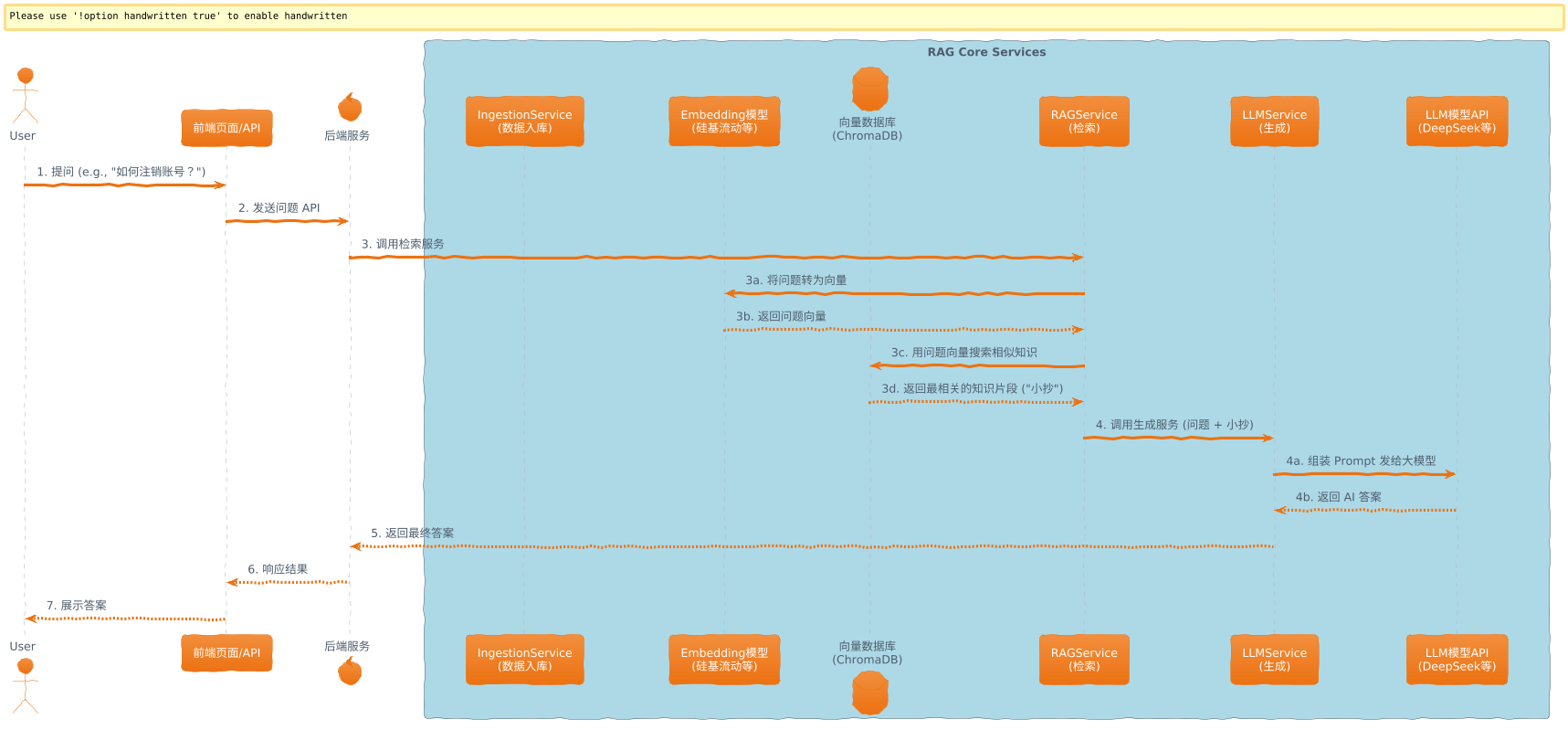
深度拆解:从 TXT 文件到 AI 专家
现在,我们用简单的一个案例,解析txt文件,用基础代码片段来剖析这个过程。
1.数据入库:让 AI 记住你的“知识点”
核心流程:
- 加载文件:读取你的 knowledge.txt。
- 预处理:清理空行、多余空格。
- 向量化:将每一段文本通过 Embedding 模型(如硅基流动)转换成一串数字(向量)。这些数字代表了这段话的语义含义。
- 存储:将文本、向量、以及文件的元数据(文件名、MD5 哈希等)一起存入向量数据库(如 ChromaDB)。
关键代码: 文本数据向量化,然后进行存入数据库的源码:
class IngestionService:
def __init__(self):
# 初始化 Embedding 模型 (将文本转为向量的工具)
self.embedding_fn = MyEmbedding()
# 初始化 ChromaDB 客户端,并指定使用我们的 Embedding 函数
self.chroma_client = ChromaClient()
self.collection = self.chroma_client.get_or_create_collection(
name=settings.COLLECTION_NAME,
embedding_function=self.embedding_fn # 👈 告诉ChromaDB用哪个工具来算向量
)
# 内部辅助方法:计算文件哈希值,用于判断文件是否变更
def _calculate_md5(self, file_path: Path) -> str:
# with open(...) as f: 这是Python的上下文管理器,确保文件自动关闭
with open(file_path, "rb") as f: # "rb" 表示以二进制只读模式打开文件
return hashlib.md5(f.read()).hexdigest()
def ingest_file(self, file_path: Path):
file_name = file_path.name
file_hash = self._calculate_md5(file_path)
# 检查文件是否已存在且未修改,实现幂等性
# 如果文件内容没变,就不重复入库了,节省计算资源
existing = self.collection.get(where={"file_hash": file_hash})
if existing and existing['ids']:
print(f"文件 '{file_name}' 内容未变,跳过入库。")
return
# 如果文件已存在但内容有变,先删除旧数据
if existing and not existing['ids']:
print(f"文件 '{file_name}' 内容已更新,删除旧数据重新入库。")
self.collection.delete(where={"file_name": file_name})
# 读取文件内容,清理空行和空格
# 列表推导式:高效地循环、过滤、转换
with open(file_path, "r", encoding="utf-8") as f:
lines = [line.strip() for line in f.readlines() if line.strip()]
if not lines:
print(f"文件 '{file_name}' 为空或无有效内容,跳过入库。")
return
# 为每一行生成唯一的ID (文件名_行号)
ids = [f"{file_name}_{i}" for i in range(len(lines))] # 👈 又是一个列表推导式
# 为每一行生成元数据,虽然内容相同,但ChromaDB需要一一对应
metadatas = [{"file_name": file_name, "file_hash": file_hash} for _ in lines]
# 将数据批量添加到ChromaDB。ChromaDB内部会自动调用 embedding_fn 进行向量化
self.collection.add(
documents=lines,
ids=ids,
metadatas=metadatas
)
print(f"文件 '{file_name}' 成功入库。总计 {len(lines)} 条记录。")
ChromaDB add 方法:接收 documents, ids, metadatas 三个等长的列表,它会内部自动将 documents 向量化,然后将四者(document, id, metadata, embedding)一一对应存储。
2.问题检索:AI的“雷达搜索”
当用户提问时,AI 并不是直接去文字匹配,而是:
- 向量化问题:把用户的问题也转换成一串数字(向量),作为“雷达信号”。
- 向量搜索:在向量数据库(我们存储知识的地方)里,找出离这个“雷达信号”最近的几串数字(即语义最相似的知识片段)。
- 返回原文:数据库会把这些最相似知识片段的原始文本和元数据“拽”出来。
class RAGService:
def __init__(self):
self.embedding_fn = MyEmbedding()
self.chroma_client = ChromaClient()
self.collection = self.chroma_client.get_or_create_collection()
async def retrieve_context(self, query_text: str) -> str:
# 1. 安全检查:如果查询文本为空或纯空格,直接返回
# 这种防御性编程,避免了对 None 或空字符串调用 .strip() 导致程序崩溃
if not query_text or not query_text.strip():
return "未提供有效查询。"
# 2. 向量化用户问题:将用户提问转换为向量(雷达信号)
# 这里调用的 my_ef(...) 实际触发的是 MyEmbedding 类的 __call__ 方法
# 即使只有一个问题,也以列表形式传入,保持与API接口一致
query_vector = self.embedding_fn([query_text])
# 3. 在向量数据库中搜索最相似的知识片段
# n_results=1 表示我们只需要最相关的那一条
results = self.collection.query(
query_embeddings=query_vector,
n_results=1,
include=['documents', 'metadatas'] # 告诉ChromaDB,除了向量,还要把原始文本和元数据也拿回来
)
# 4. 提取检索到的上下文
# 结果是嵌套列表,需要多层取值
# results['documents'][0][0] 意为:
# ['documents'] -> 获取所有结果的文本列表
# [0] -> 获取第一组查询(因为我们只查询了一个问题)的结果
# [0] -> 获取最相似的第一个文档片段
context = results['documents'][0][0] if results and results['documents'] and results['documents'][0] else None
# 5. 返回上下文,如果没有找到则给一个默认提示
return context if context else "未找到相关参考资料。"
- collection.query():向量数据库的核心查询接口。它拿着我们转换好的 query_vector,在海量知识库中进行“语义匹配”,返回最相似的知识片段。
- results['documents'][0][0]:ChromaDB 的返回结果是分层的。第一个 [0] 代表“第一组查询的结果”(因为我们只查了一个问题),第二个 [0] 代表“在这一组结果中排名第一的文档片段”。
3.生成答案:AI的”临场发挥“
拿到最相关的“小抄”后,最后一步就是让大模型(LLM)结合用户的原始问题和这份“小抄”来生成最终的回答。
class LLMService:
def __init__(self):
# 初始化 OpenAI 兼容的 API 客户端
# 注意:这里的 base_url 配置决定了实际调用哪个大模型服务 (如硅基流动 DeepSeek)
self.client = OpenAI(api_key=settings.API_KEY, base_url=settings.BASE_URL)
async def chat_with_rag(self, query: str, context: str) -> str:
# 1. 安全处理检索到的上下文
# 确保即使没有找到资料,AI 也知道如何回复
safe_context = context if context else "未找到相关参考资料。"
# 2. 组装 Prompt (提示词)
# 告知AI它的角色(system),并给出参考资料和用户问题(user)
messages = [
{"role": "system", "content": "你是一个 PDNob 产品的专业客服助理。请根据提供的参考资料回答用户问题,如果资料中没有提到,请告知用户资料中未找到。"},
{"role": "user", "content": f"参考资料:\n{safe_context}\n\n问题:\n{query}"} # 👈 关键的缝合步骤
]
# 3. 调用大模型 API 进行推理
response = self.client.chat.completions.create(
model=str(settings.LLM_MODEL), # 使用配置文件中指定的大模型名称 (如 deepseek-v3)
messages=messages,
temperature=float(settings.RAG_TEMPERATURE), # 温度参数控制AI回答的“创造性”,RAG场景通常设低
stream=False # 如果设为 True,AI会一个字一个字地返回,需要前端配合处理
)
# 4. 提取并返回大模型的回答
return response.choices[0].message.content
- OpenAI() 客户端:尽管名称是 OpenAI,但因为 base_url 被配置到了其他服务商(如硅基流动),实际调用的是兼容 OpenAI API 标准的大模型服务。
- messages 列表:这就是 LLM API 接口中的 Prompt。"role": "system" 用于设定 AI 的角色和行为准则;"role": "user" 用于传入用户的具体请求和我们检索到的 safe_context。
- F-string 缝合:f"参考资料:\n{safe_context}\n\n问题:\n{query}" 是将检索到的“小抄”和用户问题整合在一起的关键。
- temperature 参数:控制 AI 回答的“随机性”或“创造性”。在 RAG 场景下,我们通常会设置一个较低的 temperature 值(如 0.1-0.3),让 AI 严格根据资料回答,减少“胡编乱造”。
RAG的进阶之路
现在掌握的 RAG 架构只是冰山一角。未来继续探索:
- 多文件/PDF 导入:自动解析 PDF 文档,提取文字和表格,然后入库。
- 文本切分 (Chunking):将长文档切分成合适大小的片段,并处理片段间的重叠,以提高检索质量。
- 流式输出 (Streaming):让 AI 的回答像 ChatGPT 一样,一个字一个字地蹦出来,提升用户体验。
- 多模态 RAG:不仅限于文本,图片、音频甚至视频也能作为知识源。
结余
RAG 架构就像是给 AI 增加了一个无限扩展的“外部记忆”和“精准搜索”的能力。作为后端开发者,理解并掌握这套架构,你就能为你的 AI 应用插上“专业”和“可靠”的翅膀,让它在你的业务场景中真正发挥价值。

