
mysql调优,加锁以及了解存储引擎,这些都是作为程序员进阶的重要内容。
花了几天时间,整理了MySQL的基础内容,看完后你就是合格的增删改查程序员了。通过 itcast课程进行整理。
| 分类 | 全称 | 说明 | 链接 |
|---|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象,如:数据库、表、字段等等 | DDL |
| DML | Data Manipulation Language | 数据操作语言,用来对数据表中的数据进行增、删、改 | DML |
| DQL | Data Query Language | 数据查询语言,用来查询 数据库中表的记录 | DQL |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 | DCL |
本章节主要介绍mysql的体系结构、存储引擎、索引以及优化相关
mysql体系结构
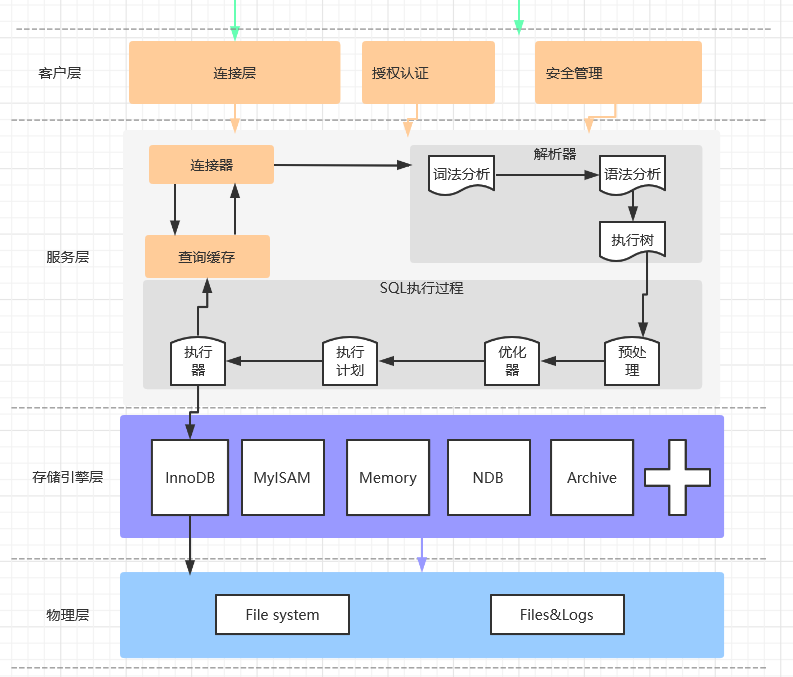
- 客户层:完成类似连接处理、授权管理、以及安全相关。也会为每个客户端验证具有的操作权限。
- 服务层:完成大多数的核心服务,如Sql接口,缓存查询、SQL分析和优化,部分内置函数的执行、解析器相关。
- 引擎层:真正负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通信。不同的存储引擎有不同的功能,可以根据业务选取合适的存储引擎。
- 存储层:将数据存储在文件系统之上,并完成与存储引擎的交互。
存储引擎
引擎,字面意思就是发动机。比如汽车的发动机(单缸、多缸、W型号),飞机的发动机(F119,F135),自行车的发动机(两条腿),游戏的引擎(Unity3D、cocos2D、egret)等等,最核心的地方。
而MySQL的存储引擎:就是存储数据、建立索引、更新、查询等技术的实现方式。是基于表的,所以存储引擎也可被称为表类型。
我们可以在创建表的时候,指定存储引擎,当然,在mysql5.5之后,可以不指定,默认为 INNODB。
-- 查询建表语句
show create table account;
-- 建表时指定存储引擎
CREATE TABLE 表名(
...
) ENGINE=INNODB;
-- 查看当前数据库支持的存储引擎
mysql> show engines;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
INNODB
InnoDB是一种兼顾高可靠和高性能的通用存储引擎,在MySQL5.5之后,则是MySQL默认的存储引擎。
- DML操作遵循ACID模型,支持事务;
- 行级锁,提高并发性能;
- 支持外键 foreign key约束,保证数据的完整性和正确性;
INNODB的逻辑存储结构如下表所示: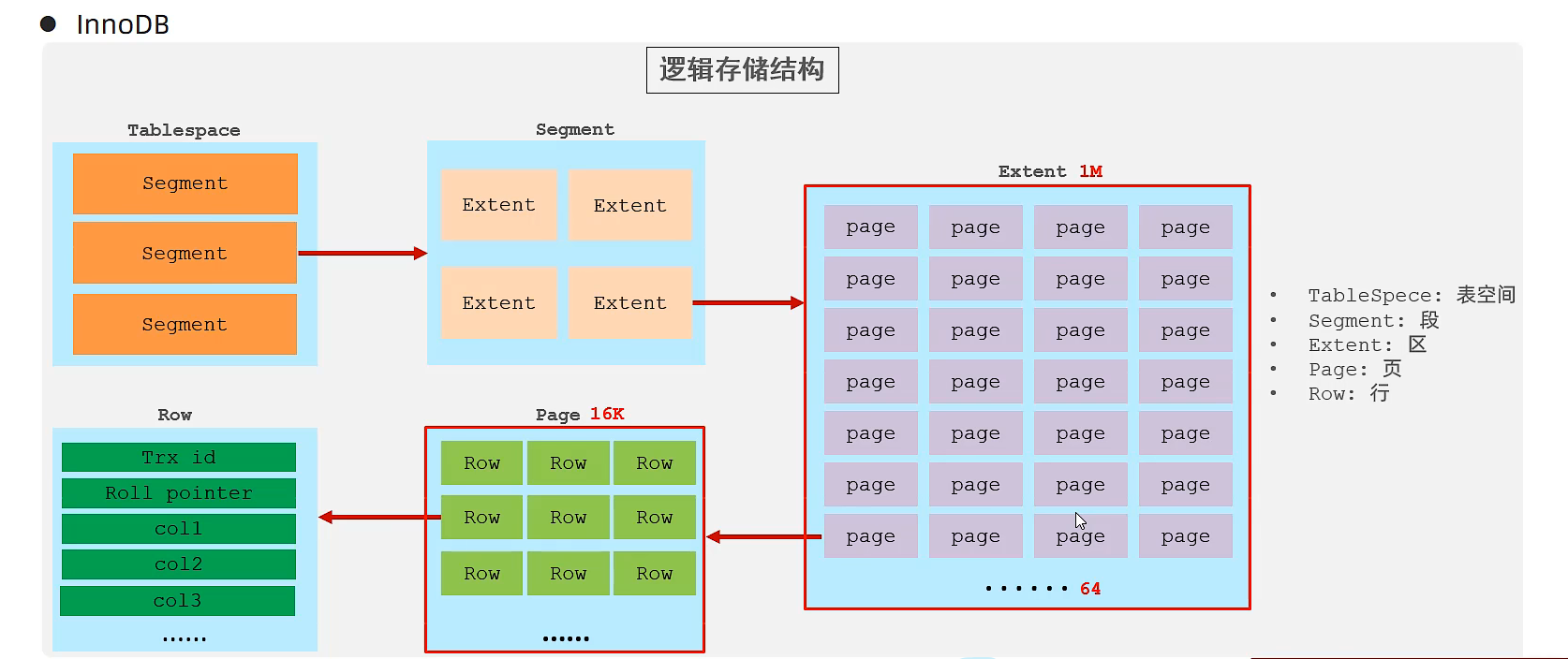
MyISAM
早期的Mysql的默认存储引擎。
- 不支持事务,不支持外键。
- 支持表锁、不支持行锁。
- 访问速度快
Memory
memory引擎的表数据时存储在内存中,这样收到硬件问题或断电的影响,只能将这些表作为临时表或缓存使用。
- 内存存放,读取速度快
- hash索引
存储引擎总结
在选择存储引擎的时候,应当根据应用系统的特点选择合适的存储引擎,对于复杂的应用系统,还可以根据实际情况选择多种存储引擎进行组合,不要一路INNODB到底。
- INNODB:如果应用对事务的完整性有比较高的要求,在并发条件下要求数据一致,数据操作除了插入和查询外,还有很多更新、删除操作,那么选择INNODB。
- MyISAM:如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对于事务的完整性、并发性要求不高,比如评论、操作记录等等,选择MyISAM。虽然,如果要选择MyISAM相关引擎,绝大部分会选择MongoDB了。
- Memory:有一些临时的数据且数据量比较少,并且对数据的安全性不那么重要,可以选择Memory,因为它访问速度很快。虽然,很少见,因为redis不香么?
| 特点 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 |
| 事务安全 | 支持 | - | - |
| 锁机制 | 行锁 | 表锁 | 表锁 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | - | - | 支持 |
| 全文索引 | 支持(5.6版本之后) | 支持 | - |
| 空间使用 | 高 | 低 | N/A |
| 内存使用 | 高 | 低 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外键 | 支持 | - | - |
索引
索引(index)是帮助Mysql高效获取数据的数据结构,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构,就是索引。

不要慌,按照惯例,画图。
假设要从user表中,查找出age为25的数据,则:

由此可见,无索引需要全表扫描,有索引只需要两次便可找到。这效率是非常高的。
以下是索引的优缺点:
优点:
- 提高数据检索效率,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗
缺点:
- 索引列也是要占用空间的
- 索引大大提高了查询效率,但降低了更新的速度,比如 INSERT、UPDATE、DELETE
刚刚也简单的提了下索引是数据结构,但索引究竟有哪些数据结构呢?如下:
| 索引结构 | 描述 | 支持的引擎 |
|---|---|---|
| B+Tree | 最常见的索引类型,大部分引擎都支持B+树索引 | INNODB、MyISAM、Memory |
| Hash | 底层数据结构是用哈希表实现,只有精确匹配索引列的查询才有效,不支持范围查询 | Memory |
| R-Tree(空间索引) | 空间索引是 MyISAM 引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 | MyISAM |
| Full-Text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式,类似于 Lucene, Solr, ES | INNODB(5.6版本后)、MyISAM |
我们平常所说的索引,如果没有特别指明,都是B+树结构组织的索引
索引结构
Hash
哈希索引就是采用一定的hash算法,将键值换成新的hash值,映射到对应的槽位上,然后存储在hash表中。
如果两个(或多个)键值,映射到同一个槽位上,就会产生hash冲突,当然可以通过链表来解决。
它的特点为:
- 只能用于等比较(=,in),不支持范围查询(>、<、between)
- 无法利用索引完成排序操作
- 查询效率高,通常(不出现hash碰撞的情况下),只需要检索一次就可以了。
上图可看,支持hash索引的是memory引擎,但是INNODB具有自适应hash功能,就是根据B+tree索引在指定条件下,自动构建。
二叉树

由此可见,顺序插入时,会形成一个链表,查询性能大大降低,大数据情况下层级较深,检索速度也慢
那是不是想说,可以用红黑树呀。我们看看。
红黑树

但是红黑树,本质上还是二叉树,在大数据量情况下,层级较深,检索速度慢。
那如何解决大数据量下层级较深的问题呢?可以构建一棵树,下面不是一个子节点而是多个呢? 可以,B树。
B-Tree(多路平衡查找树)

看上去,没啥问题哈,先不要慌,凡是要最优解,我们再看看B+Tree
B+Tree

可以看到,
- 所有的叶子节点,既有指针又挂有数据,上面的非叶子节点,主要是起到索引的作用。
- 所有的叶子节点,形成了一个单向有序的链表。
而且,mysql索引数据结构,对经典的B+Tree进行了优化,在原有B+树的基础上,增加了一个指向相邻叶子节点的双向循环链表指针,就形成了带有顺序指针的B+Tree,从而提高区间访问的性能。如:

所以,为什么INNODB存储引擎选择使用B+tree索引结构呢?
- 相对与二叉树,层级更少,搜索效率高;
- 相对应B树,B树的叶子节点和非叶子节点都会保存数据,这样导致一页中存储的键值减少,指针也跟着减少,要同样保存大量数据,只能增加数的高度,导致性能较低。B+树的层级更少更矮。且B+树结构中形成了双向链表,便于范围搜索和排序。
- 相对于 Hash 索引,B+Tree 支持范围匹配及排序操作
索引分类
详见如下:
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建索引 | 默认自动创建,只能有一个 | primary |
| 唯一索引 | 避免同一个表中某列数据值重复 | 可以有多个 | unique |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文查找文本关键字,而非比较索引中的值 | 可以有多个 | fulltext |
在 InnoDB存储引擎中,根据索引的存储形式,又可以分为:
- 聚集索引(Clustered index):将数据存储于索引放在一块,索引结构的叶子节点保存了行数据。在一张表中必须有,且只有一个,不然你的数据如何存放。
- 如果存在主键,则主键索引就是聚集索引。
- 如果不存在主键,则使用第一个唯一索引作为聚集索引。
- 如果表没有主键,也没有合适的唯一索引,则INNODB会自动生成一个rowid作为隐藏的聚集所以。
- 二级索引(Secondary index):将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键。一张表中,可以有多个。
下图充分的说明了聚集索引和二级索引:
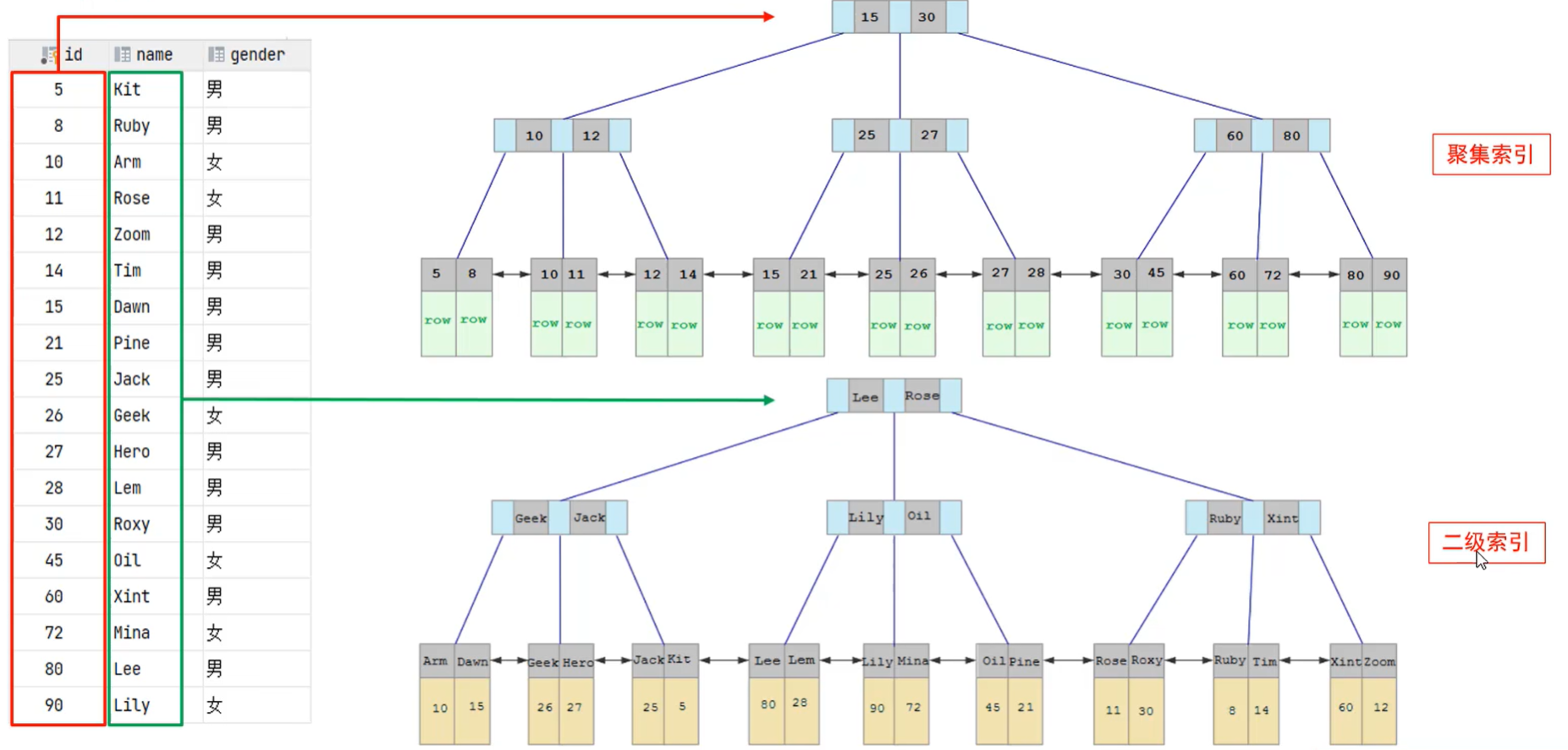
id就表明为聚集索引,因为它是主键。它的叶子节点下都挂着当前行的数据。
name为二级索引,它的下面挂的是对应的id。
比如这一条sql select * from user where name = 'Arm',它的逻辑是怎样的呢?
- 首先查询二级索引,Lee->Geek->Arm,并得到聚集索引,id为10.
- 拿到id后,接着去聚集索引下,查找 15->10->10找到10,然后拿到聚集索引下挂载的row所有数据。
- 这个有个专业术语,就叫做
回表查询,就是先到二级索引拿到主键值,然后根据主键值去聚集索引中拿到row数据。
如上图,来道题:
以下sql语句,哪个执行效率高,为什么?
1:select * from user where id = 10;
2:select * from user where name = 'Arm';
送分题,通过上述可以得知,1的效率高。因为:
- 直接去聚集索引中查找到了主键,然后把下面挂载的row带出来了。
- 2还要先去二级索引查找主键,然后再去聚集索引中查找主键,再查找值。相当于回表查询了。
InnoDB 主键索引的 B+Tree 高度为多少?
答:假设一行数据大小为1k,一页中可以存储16行这样的数据。InnoDB 的指针占用6个字节的空间,主键假设为bigint,占用字节数为8.
可得公式:`n * 8 + (n + 1) * 6 = 16 * 1024`,其中 8 表示 bigint 占用的字节数,n 表示当前节点存储的key的数量,(n + 1) 表示指针数量(比key多一个)。算出n约为1170。
如果树的高度为2,那么他能存储的数据量大概为:`1171 * 16 = 18736`;
如果树的高度为3,那么他能存储的数据量大概为:`1171 * 1171 * 16 = 21939856`。
另外,如果有成千上万的数据,那么就要考虑分表,涉及运维篇知识。
索引语法
语法主要是从创建、查看、删除等三个方面进行学习。
创建索引
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name (index_col_name,...);
- INDEX 之前可以加上 UNIQUE(表示唯一索引)、FULLTEXT(全文索引),如果不加,则表示为常规索引。
- index_name ON table_name表示要为哪一张表的哪一个字段,创建索引。
- (index_col_name,...)表示,一个索引,可以关联多个字段的,如果一个索引只是关联一个索引,称之为单列索引。如果关联多个字段,称之为联合索引或组合索引。
- 如果创建联合索引,那么顺序是有讲究的,不然可能匹配不上。后续详细介绍。
- 业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单例索引。
-- 为name创建创建索引
create index idx_user_name on tb_user(name);
-- 为phone创建唯一索引
create unique index idx_user_unique_phone on tb_user(phone);
-- 为age、gender创建联合索引
create index idx_age_status on tb_user(age,gender);
查看索引
SHOW INDEX FROM table_name;
删除索引
DROP INDEX index_name ON table_name;
- index_name,就是创建索引的index_name。
- 表示要删除哪一张表的哪一个索引。
- 这个指令用的较少。
SQL性能分析
我们优化,主要是优化查询语句,查询语句,那首当其冲,就是索引。我们可以从如下入手:
SQL执行频率
假如说业务系统,虽然数据量大,但是只做插入不做查询,或者主要是增删改为主,那就没必要做优化了,或者优化的比重可以放放。所以得看执行频率。
show global status like 'Com_______';
mysql> use study;
Database changed
mysql> show global status like 'Com_______';
+---------------+--------+
| Variable_name | Value |
+---------------+--------+
| Com_binlog | 0 |
| Com_commit | 15 |
| Com_delete | 4 | // 删除 这个是我们关心的
| Com_insert | 110012 | // 插入,我们关心的
| Com_repair | 0 |
| Com_revoke | 1 |
| Com_select | 6115 | // 查询,我们要注意的
| Com_signal | 0 |
| Com_update | 27 | // 更新,我们要关心的
| Com_xa_end | 0 |
+---------------+--------+
10 rows in set (0.00 sec)
由此可见,study数据库,插入虽然很多(一次性插入的),但查询也是很多的。需要优化。
慢查询日志
慢查询:MySQL提供的一种日志记录,用来记录在MySQL中响应时间超过阀值的语句。记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。
通过 show variables like 'slow_query_log';查看是否开启慢查询日志。
Mysql的慢查询日志默认没有开启,需要在Mysql的配置文件中配置:
[root@VM-4-9-centos ~]# whereis my.cnf
my: /etc/my.cnf
# vi my.cnf
# 把slow_query_log=1 #开启慢查询开关
# long_query_time=10 #也就是说sql语句执行时间超过10s,就会记录
# slow-query-log-file=/www/server/data/mysql-slow.log # 记录的日志文件
systemctl restart mysqld # 修改后重启
于是乎,我查询十万条数据 select * from tb_user LIMIT 100000; 在mysql-slow.log下面就会有慢查询的记录了.
Time Id Command Argument
# Time: 2023-09-22T14:27:12.520739Z
# User@Host: milo[milo] @ [119.123.32.87] Id: 2
# Query_time: 25.903382 Lock_time: 0.005001 Rows_sent: 99606 Rows_examined: 99606
use study;
SET timestamp=1695392832;
select * from tb_user LIMIT 100000;
明显看出,这条sql执行了25,优化去吧少年。
profile详情
我们是设置了慢查询日志的时间为10s,但是有很多sql,比如7s、8s等等,对于很多业务来说也是接受不了的,但是慢查询日志里有没看到,怎么办?
在mysql中,提供了一个指令,叫做show profiles,它能够在做sql优化时帮助我们了解时间都耗费到哪里去了,通过have_profiling参数,可以看到当前mysql是否支持。
mysql> select @@have_profiling;
+------------------+
| @@have_profiling |
+------------------+
| YES | # 表示支持
+------------------+
1 row in set, 1 warning (0.00 sec)
支持了,但是还需要开启它,默认来说,profiling是关闭的,可以通过set语句开启。
mysql> set profiling=1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> select @@profiling;
+-------------+
| @@profiling |
+-------------+
| 1 |
+-------------+
1 row in set, 1 warning (0.00 sec)
开启后,就可以开始玩了,如先查询几张表,再看看这几张表的耗时情况。
select * from tb_user LIMIT 1000;
select name from tb_user limit 10000;
select id from tb_user limit 100000;
mysql> show profiles;
+----------+------------+--------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+--------------------------------------+
| 1 | 0.00012800 | select @@profiling |
| 2 | 0.00178975 | select * from tb_user LIMIT 1000 |
| 3 | 0.00278650 | select name from tb_user limit 10000 |
| 4 | 0.02773900 | select id from tb_user limit 100000 |
+----------+------------+--------------------------------------+
4 rows in set, 1 warning (0.00 sec)
接着找到查询过慢的数据,如query_id为4的,通过show profile for query query_id可以查看它在各个阶段的耗时情况:
mysql> show profile for query 4;
+----------------------+----------+
| Status | Duration |
+----------------------+----------+
| starting | 0.000059 | # 开始执行
| checking permissions | 0.000006 | # 检查权限
| Opening tables | 0.000018 | # 打开表
| init | 0.000014 | # 初始化数据
| System lock | 0.000013 | # 操作系统锁相关
| optimizing | 0.000004 | # 优化的操作
| statistics | 0.000013 | # 统计的操作
| preparing | 0.000009 | # 准备操作
| executing | 0.000003 | # 执行操作
| Sending data | 0.027533 | # 数据发送
| end | 0.000014 | # 完毕
| query end | 0.000012 |
| closing tables | 0.000009 |
| freeing items | 0.000017 |
| cleaning up | 0.000017 |
+----------------------+----------+
15 rows in set, 1 warning (0.00 sec)
explain执行计划
以上,其实都是通过查询时间来评判一个sql,但是并不能真正的给出具体的优化建议。我们可以通过 explain 来查看执行计划,来判断sql的性能,查看如何执行select语句的信息,包括在执行过程中表的连接、和连接的顺序、索引情况等等。
语法: explain select 字段 from 表明 where 条件 ,可以在任意的sql语句之前加上关键字 explain(或者desc) 。
mysql> desc select * FROM tb_person JOIN tb_dept on tb_person.dept_id=tb_dept.id;
+----+-------------+-----------+------------+--------+--------------------+---------+---------+-------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+--------+--------------------+---------+---------+-------------------------+------+----------+-------------+
| 1 | SIMPLE | tb_person | NULL | ALL | tb_person_dept__fk | NULL | NULL | NULL | 4 | 100.00 | Using where |
| 1 | SIMPLE | tb_dept | NULL | eq_ref | PRIMARY | PRIMARY | 4 | study.tb_person.dept_id | 1 | 100.00 | NULL |
+----+-------------+-----------+------------+--------+--------------------+---------+---------+-------------------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
id:查询的序号,表示执行select顺序,id相同,执行顺序从上到下,不同,值越大,越先执行。一般查几张表,就会有几个id。
select_type:常见的有simple(简单表,不用表连接或子查询)、primary(主查询,外层的查询)、union(union中的第二个或后面的查询语句)、subquery等等,这个字段查看的意义不是很大。
partitions:表示查询涉及的分区,一般不关注。
type:访问的类型,相对来说比较重要的指标,从好到差为:NULL>system>const>eq_ref>ref>range>index>all。
- NULL:业务系统一般不会为NULL,NULL表示不查询表,比如
select 'A'; - system:表示内部系统表来处理查询,而不是实际的用户表,正常也遇不到.
- const:使用常数值进行查询,通常为查询前计算出结果,而不需要实际访问表。如id为主键
desc select * from tb_dept where id=1;即为常数查询,不需要访问回表,直接在聚集索引中查找到了主键。或者没有主键但是有唯一索引列进行精确查找,都能得出常数查询。 - eq_ref:使用唯一索引进行查找通常为eq_ref.
- ref:使用非唯一索引进行查找通常为eq_ref.比如name为常规索引,
desc select * from tb_user where name='用户1';。 - range:通过索引进行范围扫描,比如age有常规索引,但是>age,就是在范围内进行搜索,通常出现在>、<、between、in 中。
desc select * from tb_user where age > 45; - index:表示查询正在使用一个或多个索引进行访问表,通常出现在可以使用索引的范围条件中,也可以理解在索引中去搜索值。这种虽然比all好,但是我们尽量也不要停留在这个阶段。
- all:裸奔,无任何索引,全表扫描,表示检索所有行。不能有这个查询方式,如上再dept_id并未建立索引,就会出现全表扫描。
- NULL:业务系统一般不会为NULL,NULL表示不查询表,比如
possible_keys:表示可能用于查询的索引列表。这是一个逗号分隔的索引名称列表。
key:表示实际用于查询的索引。如果该列为NULL,则表示没有使用索引。这就需要优化了。
key_len:表示索引的长度,以字节为单位。该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好。
rwos:表示估计需要扫描的行数,即查询将检查的行数。但在INNODB下,只是一个估值,可能不是那么的准确,这里只是做一个参考。
filtered:表示返回结果的行数占需要读取行数的百分比,值越大越好。比如我们查询age>40的值实际为10个,返回的也是10个,那么他的值就是100。这也是一个优化项。
extra:包含其他信息,也是经常用的多的如下:
- using index:表示查询使用了覆盖索引,以为着查询的结果可以直接从索引中获取,不需要回表。这种情况是比较好的,通常建议优化到这种。
- using where:表示使用了where子句来过滤结果集,通常查询中包含了条件,其中一部分在索引中执行,一部分在表中执行。
- using temporary:表示查询在执行中使用了临时表,可能发生在排序或者分组的时候。
- Full scan on NULL key (index map: <index_name>):表示查询执行了全表扫描,以查找空键值(NULL)。
- NULL:这种情况一般来说表示执行计划相对标准,但是,为NULL是回表查询了。
索引使用法则
最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则,指的是查询从索引的最左列开始,并且不跳过索引中的列。 如果跳跃了某一列,索引将部分失效(后面的字段索引失效)。
-- 联合索引为: name_email_phone
desc select * from tb_user where name = 'zhangsan'; --走索引,name 索引长度为153,filtered为100 ,如果不加引号,索引失效
desc select * from tb_user where name = 'zhangsan' and email='ddd@qq.com'; -- 走索引,索引长度为306,filtered为100,说明email的索引长度为 153
desc select * from tb_user where email='ddd@qq.com' and name = 'zhangsan'; -- 走索引,索引长度为306,filtered为100,说明email的索引长度为 153,说明where的顺序不影响。
desc select * from tb_user where name = 'zhangsan' and email='ddd@qq.com' and phone='+8614543676543'; -- 走索引,索引长度为369,filtered为100,说明phone的索引长度为 63
desc select * from tb_user where email='ddd@qq.com' and phone='+8614543676543'; -- 不走索引,全表扫描
desc select * from tb_user where name = 'zhangsan' and phone='+8614543676543'; -- 走索引,但key_len为153,且filtered为10,说明只是name走了索引,phone没走,因为中间跳过了email。
desc select * from tb_user where email='ddd@qq.com'; -- 不走索引,全表查询。
总结:a_b_c为联合索引:
- 查询a,ab,abc,全部走索引。查询顺序无索引,mysql会自行优化。
- 查询ac,a走索引,c不走索引,因为跳过了b。
- 单独查询b、c,不走索引,全表扫描。
- 如果where非and而是or,where a='' or b='',则不走索引,全表扫描。
- 如果a还有一个常规索引,查询为where a = '',则会走联合索引,如果想要a走单独的索引,可以使用sql提示。
范围查询
联合索引中,出现范围查询(>、<)范围查询右侧的列索引失效。
如:a_b_c为联合索引,where 查询
- a=''and b>0 and c='',a和b走索引,从不走,因为右侧的列失效.
- a=''and b>= and c='',abc都走索引,所以业务允许的情况下,最好用大于等于或者小于等于。
索引列运算
不要在索引列上面进行运算操作,否则索引将失效。
如phone有索引,截取phone从10位开始两位为12的数据 desc select * from tb_user where SUBSTRING(phone,10,2) = 12;,则索引失效。
字符串不加引号
字符串类型字段使用时,不加引号,索引将失效。
如 desc select * from tb_user where name = 'zhangsan';走索引,但是desc select * from tb_user where name = zhangsan;则索引失效,全表扫描。
又如联合索引 a='' and b= ,则a走b不走。
模糊查询
如果仅仅是尾部模糊匹配,索引不会失效,如果是头部进行模糊匹配,则索引失效。在大数据的情况下,要规避头部模糊查询
-- 走索引
desc select * from tb_user where phone like '52086558%';
desc select * from tb_user where phone like '+86136761%6995'; --走索引,但是查询的行变多
desc select * from tb_user where phone like '+8613%6995'; --但是如果中间省略的多,可能会不走索引走全表扫描
-- 不走索引 全表扫描
desc select * from tb_user where phone like '%52086558';
desc select * from tb_user where phone like '%52086558%';
or链接的条件
用or分开的条件,如果or前的条件列有索引,而后面的列没有索引,则涉及到的索引都不会用到。
- a有索引,b也有索引,则a or b,a和b都会走索引。
- a有索引,b没有索引,则a or b或者 b or a,则两个都不会走索引,全表扫描。
- a,b都有索引,b没有索引,则 a or b or c,都不会走索引,全表扫描。
数据分步影响
如果mysql评估去使用索引比全表更慢,则不使用索引,如上述的
desc select * from tb_user where phone like '+8613%6995' 哪怕phone有索引,但还是走的全表扫描。因为mysql评估,绝不部分的数都满足这个模糊查找,还不如走全表呢。
sql提示
sql提示,就是在sql语句中加入一些认为的提示来达到优化操作的目的。
比如上述的联合索引name_phone_email,name又有单独的索引,如果单独查询name的话,则会走联合索引,此时如果想走单独的name索引呢?
- 可以使用use,
desc select * from tb_user use index(idx_name) where name = 'zhangsan';,指定他走具体的单列索引。(这个只是给mysql给的建议,但是接不接受需要mysql自己去平衡的) - 可以用ignore忽略某个索引。
desc select * from tb_user ignore index(idx_name_email_phone) where name = 'zhangsan';,忽略它走联合索引,索引只能走单列索引。 - 可以使用force,强制来,和use不同的话,这个是强制指定的。
desc select * from tb_user force index(idx_name) where name = 'zhangsan';
索引小技巧
覆盖索引
尽量使用覆盖索引,也就是查询使用了索引,并且需要再返回的列中,在该索引中已经全部能够找到,也是避免使用select * 的佐证。
如,a、b、c三个字段都有索引,d没有索引,但是我select的时候: select a,b,c,d from table where a='' and b='' and c='',此时会回表查询d,因为a、b、c都在二级索引中可以查到,但是d没有,需要根据id再去聚集索引中查询。
也就是如果使用了 select * 你不可能把每个字段都列进索引吧,所以必然会回表。
所以针对上面如果每次都是abcd需要返回,建议建立一个idx_a_b_c_d的联合索引,这样查询完后在二级索引中即可查到所有数据,不需要再去回表查询。
前缀索引
当字段类型为字符串(varchar,text等),有时候需要用到索引很长的字符,比如一篇文章等等,这会让索引变得很大,查询的时候浪费大量的磁盘IO,影响查询效率,此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。比如可以将一篇文章开头的前十个字符作为前缀索引。和之前创建索引的基本一致:
- 语法:
create index idx_xxx_xxx on table_name(column(n)); - 前缀长度:
可以根据索引的选择性来决定,选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高,唯一索引的选择性是1,这是最好的索引选择性也,性能是最好的。
比如我想针对email来创建前缀索引,可以如下:
-- 先找出user表中,没有重复的邮箱和总数的比,比如为0.9
select count(distinct email)/count(*) from tb_user;
-- 再截取邮箱的前面几个字符,具体多少个得试,如截取前面8个字符,和总数的比例,和全部的比例差不多都是0.9了,那就是8个字符了
select count(distinct substring(email,1,8))/count(*) from tb_user;
-- 创建前缀索引
create index idx_email_8 on tb_user(email(8));
show index from tb_user;
前缀索引流程如下:
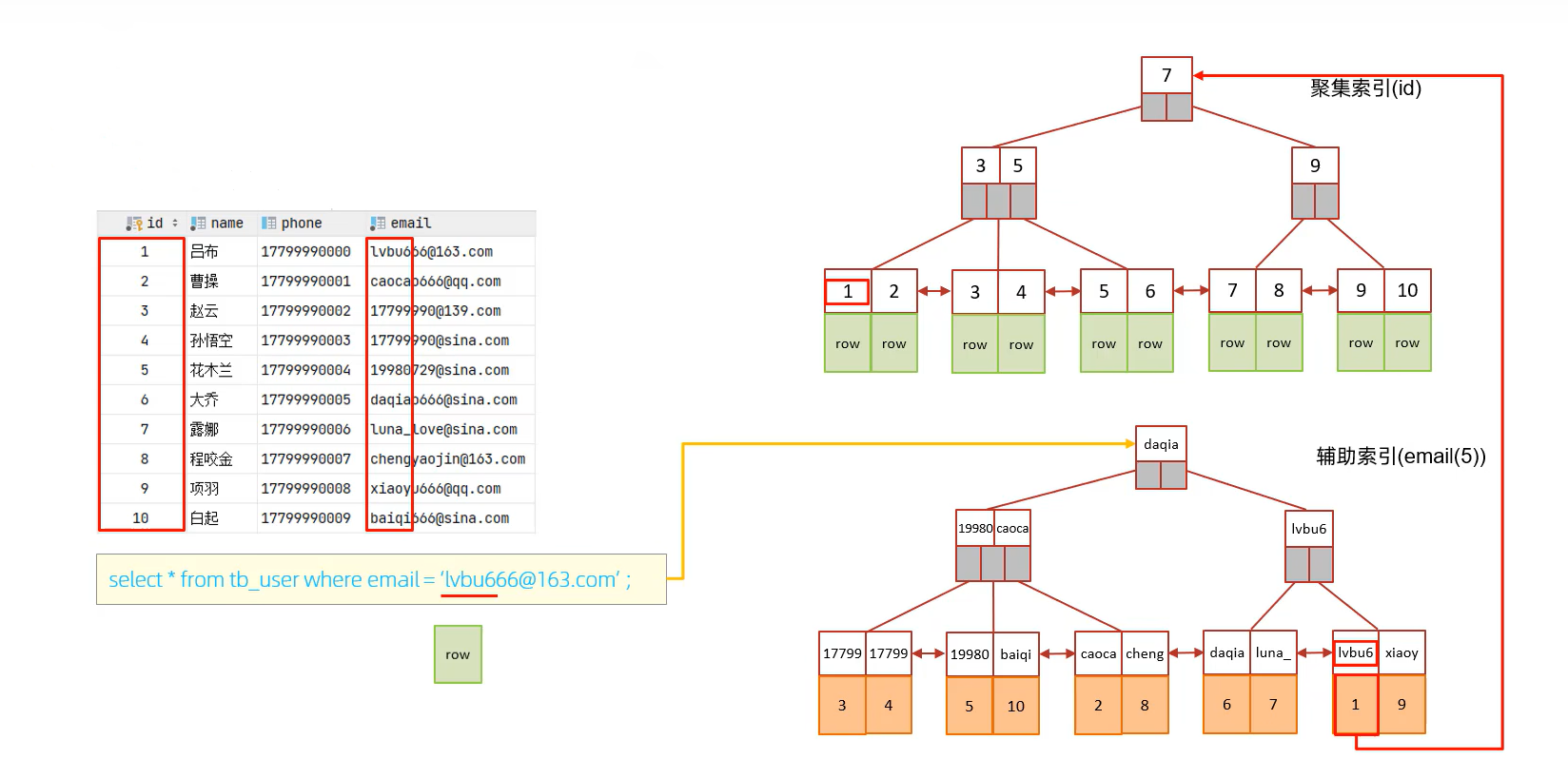
- 如email前缀索引为5为,通过lvbu6来去二级索引中搜索到id为1.
- 通过id为1去聚集索引中找到整row的数据。
- 然后拿出全量的email数据进行匹配,如果匹配成功则记录下来。
- 接着二级索引中继续匹配是否还有lvbu6的索引。当然一般都是在相邻节点。
联合索引情况
直接上图吧,
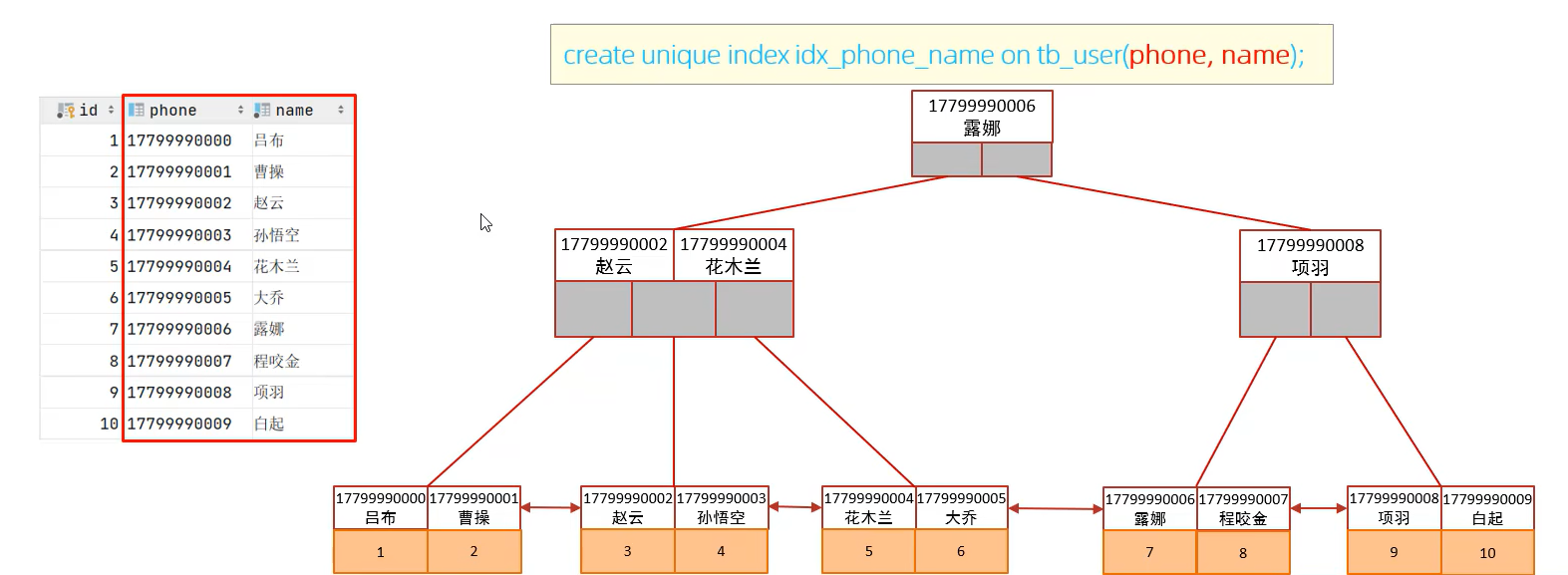
- 创建了联合索引,phone和name,二级索引如上图所示。
- 如果查询
select id,phone,name where phone='17799990002' and name='赵云';,则会找到id为3的,此时id/name/phone都在叶子节点上,覆盖索引,是不需要回表查询的。 - 建议使用联合索引,如果联合索引使用得当,是避免回表查询的。如果使用单列索引,很容易回表查询的。
索引设计原则
看到这里,大家应该对什么样的表,什么样的字段,该如何建立索引了吧。下面做个总结:
- 1:针对数据量大的,且查询比较频繁的表建立索引。一般数据量超过10w就要考虑了,几千几万条建不建立索引影响不大。
- 2:针对常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
- 3:尽量选择分区高的列作为索引,建立唯一索引,区分度越高,使用索引的效率越高。比如用户的手机号、邮箱,姓名,对于每个用户来说他们的信息都不一样,这就是区分度高。什么性别、状态等等区分度不高,没有太大必要建立索引。
- 4:如果字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
- 5:尽量使用过联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间避免回表,提高查询效率。
- 6:要控制索引的数量,索引不是多多益善,索引越多维护索引结果的代价也就越大,会影响增删改的效率。
- 7:如果索引列不能存储null值,在创建表的时候使用not null约束。当优化器知道每列是否包含null值时,可以更好确定哪个索引有效于查询。
SQL优化
insert优化
- 批量插入,因为单词插入的话,每次插入都需要建立链接,这是一个耗时的操作。批量插入的数据,不建议超过一千条。超过了可以分割多个sql插入或者使用
load指令,用的较少,可自行查询。测试过,一百万数据使用insert需要几分钟,使用load只需要二十秒。 - 手动提交事务,关掉mysql自动提交事务。不然会频繁事务开启关闭。
- 主键顺序插入,性能高于乱序插入。
主键优化
先介绍两个概念:
页分裂现象
我们知道,在INNODB中,表数据都是根据主键顺序组织存放的,这种存储访问的表称为索引组织表(index organized table)简称IOT。
如图显示,所有的数据都在叶子节点,且按照顺序有序的,而非叶子节点仅仅起到了索引数据的作用。绿色的块就代表一个页:
也是可以为空,也可以填充一半,也可以填充全部。每个页包含了2-N 行数据,如果一行数据过大,会行溢出。
如果主键乱序插入的话,会破坏掉之前的页,重新打乱设置双向指针,导致页分裂。
页合并现象
当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记为删除并且他的空间变得允许被其他记录声明使用。且当页中删除的记录达到merge_threshold(默认为页的50%),INNODB就会开始寻找最靠近的页,看看是否可以将两个也合并,以优化空间使用。
删除后,该空间可以允许其他记录声明和使用,但当删除到某一个临界点(默认为50%)的时候,INNODB就会查找上一页,或者下一页有没有合并的可能性,如果有的话,则合并。

如已经删除50%,则查看上一页和下一页,明显下一页3#数据页有大多数空间,则合并。

则把3#的数据移动到2号上,则3#就空出来了

一旦有新的数据来临,如20主键id来了,就往3#上面插入

所以,主键优化一般从:
- 满足业务需求的情况下,尽量降低主键的长度。因为对于一张表来说,聚集索引只有一个,但是二级索引会有很多,在二级索引叶子节点上挂着的就是主键id,如果主键id长二级索引多,则会占用大量的磁盘空间,且在搜索的时候会占用大量的io。
- 插入数据时,尽量选择顺序插入,选择使用auto_increment自增主键。会减少页分列选项。
- 尽量不要使用UUID做主键或者其他自然主键(如身份证号),但是现在分布式架构下,可能大部分都会采用uuid,如雪花算法。
- 业务操作中,避免对主键做修改,一旦修改了还需要动索引结构,这个代价也大,我们也业务开发者一般不会这么干,因为你根本不知道还有多少张表进行了关联,需要一块修改的。
order by 优化
对于order by,mysql有两种方式。
- using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成操作,所有不是通过索引直接返回排序结果的排序都叫做filesort排序。
- using index:通过有序索引顺序扫描直接返回有序数据,这种情况为using index,不需要额外排序,操作效率高。
例如,age和phone开始没有索引,但是这个在排序里面,如 select id,age,phone from tb_user order by age,phone;,通过explain查看,extra为using filesort。
但如果加上了idx_age_phone的联合索引,则extra为using index (注意,排序也有最左原则)。 usingindex的效率要高于using filesort的。
但如果我们为:select id,age,phone from tb_user order by age asc ,phone desc;
mysql> desc select age,phone from tb_user ORDER BY age,phone desc;
+----+-------------+---------+------------+-------+---------------+---------------+---------+------+---------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------------+---------+------+---------+----------+-----------------------------+
| 1 | SIMPLE | tb_user | NULL | index | NULL | idx_age_phone | 65 | NULL | 1091431 | 100.00 | Using index; Using filesort |
+----+-------------+---------+------------+-------+---------------+---------------+---------+------+---------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)
也就是说,一部分走了index,一部分走了filesort,因为我们在建立索引的时候,默认为asc,所以一部分desc的话,是需要全表或者表的索引去排序的。如果我们的业务逻辑都是这样的话,可以这么解决:create index idx_user_age_pho_ad on tb_user(age asc,phone desc);,也就是建立对应的索引规则。则为using index。
这些前提是 都是使用了覆盖索引,不需要回表查询的。
所以基于order by,我们有如下优化:
- 根据排序字段建立合适的索引,多字段排序的时候也遵循最左前缀法则。
- 尽量使用覆盖索引。
- 多字段排序,一个升序一个降序,此时需要注意联合索引在创建时的规则。
- 如果不可避免的出现filesort,大数据排序的时候,可以适当增加排序缓冲区sort_buffer_size(默认为256k)。如果满了则会去磁盘文件中排序则性能较低。
mysql> show variable like 'sort_buffer_size';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| sort_buffer_size | 262144 |
+------------------+--------+
1 row in set, 1 warning (0.00 sec)
group by 优化
介绍一个extra的属性 using temporary,使用了临时表。如现在age没有索引下,根据age进行分组 desc select age,count(*) from tb_user GROUP BY age;。 则使用了临时表,这是性能比较低的。
- 此时我们建立idx_name_age进行分组,还是执行
desc select age,count(*) from tb_user GROUP BY age;,发现为 'using index;using temporay',一部分走了索引,一部分走了临时表。说明需要满足最左原则。 - 在原索引基础上,我们执行
select name,count(*) from tb_user where name='用户6' GROUP BY age;查询name,发现为'using index',因为在where里面出现了name,也是满足最左原则。
索引,我们group by优化的建议是:
- 分组操作时,可以通过索引来提高效率。
- 分组操作时,索引的使用也是需要满足最左前缀法则
limit 优化
在大数据下,limit分页越多,则耗时会越长,如 select * from tb_user LIMIT 0,10;查询第一页的数据,时间可以忽略不计,0.001s,但是在一千万的时候呢? select * from tb_user LIMIT 1000000,10;时间则会达到几十秒。因为此时需要排序前一千万的数据,但是仅仅返回后十条数据,其他记录丢西,查询排序的代价很大。
不过,我们可以通过覆盖索引+子查询的方式进行优化,这也是官方提供的方式。
select s.* FROM tb_user as u JOIN (select id FROM tb_user limit 10000000,10) as s on u.id=s.id;
因为查询id是非常快的,id为主键索引,然后在通过查询id作为一张表进行联合查询,则效率大大的提高。
count 优化
对于count,他是一个聚合函数。在MyISAM引擎中把一个表的总行数存放在磁盘上,因此执行的时候会直接返回这个数,效率很高,当然,前提是后面没有where条件。在INNODB上,它执行count(*)的时候,需要把数据一行行的从引擎中读取出来,然后累积技数。官方并没有提供好的优化方式,不过我们的优化思路是,自己计数。
自己计数:也就是通过其他方式,在插入的时候把count++,删除的时候把count--,但是也是不能做where条件的。
不过,写都写了,就介绍几种常见的count方式吧。
count(*)就是求这个表的总记录数。select count(*) FROM tb_user;,INNODB引擎并不会把全部字段取出来,这是专门做的优化,服务层直接按行进行累加。count(id)id为主键。INNODB引擎会遍历整张表,把每一行的主键id取出来返回给服务层,服务层拿到主键后,再按行进行累积,主键不可能为null。count(字段名)如:select count(name) FROM tb_user;。 这个和上面还是有区别的,因为它要判断当前row的name是否为null,如果为null则不计数。- 如果没有not null约束,INNODB引擎会遍历整张表把每一行的字段值取出来,返回给服务层,服务层判断是否为null,不为null则计数累加。
- 有not null约束,INNODB引擎会遍历整张表把每一行的字段取出来返回给服务层,直接按行进行累积。
count(1),表示我们所有查询的每一条记录,都会放一个1进去,然后在累积,这就完全查出来具体有多少行,哪怕这row为null,和count(*)类似。但是INNODB会遍历整张表,但是不取值,只是返回的每一行都放一个数字1,直接按行累加。
所以,明显可以看出,我们的count(*)的效率是最高的,因为它根本不取值,直接累积。接下来是count(1)>count(主键)>count(字段)。我们要看数据库的行数的时候,使用count(*)吧,这是mysql专门做的优化。

