
在日常工作中,有一些细小问题恰巧是我忽略的,或者是遇到一些问题不知如何实践,今天我们就探讨下,键值设计。
键值设计
键值设计,最基础的,但是你真的会吗?比如如何优雅的设计key结构以及如何避免bigkey?使用到合适的数据类型了吗?
优雅的key结构
key虽然是自定义,但最好是遵守一下最佳实践约定:
遵循基本格式 [业务名]:[数据名]:id
比如我们的用户登录,根据id去获取数据,那么key的设计就是 login:user:1 ,表示登录业务中,用户id为1的数据。
这样设计有如下优点:
- 可读性强,一眼就可以知道具体的业务模块。
- 避免key冲突,加上了userid,肯定不会冲突了。
- 方便管理,在客户端工具中,使用
:隔开后,会自动分层,层次清晰。
长度不宜过长
- 首先,长度越小,越能减少内存。所以在遵循上述基本格式上,长度越小越好。redis是基于内存的存储系统,当内存占用较大时,就影响redis的读写速度。
- 其次,在使用redis时,我们通常需要对数据进行持久化,以便数据恢复,当key过长时,会影响redis的持久性能,进而影响数据的恢复。
- 最后,长key会导致redis命令执行时间延迟。因为redis服务器需要将key解析成hash值来执行操作,如果key过长,解析时间就会延长。
具体多长?官方也没有建议,反正就是在遵循基本格式上,越短越好,相信也不会太长。
优雅的value设计-拒绝bigkey
bigkey:通常以key的大小和key中成员的数量来综合判定,如:
- key本身的数据量过大:一个string类型的key,它的值为5MB。
- key中的成员数过多:一个zset类型的key,它的成员数量为1w个。
- key中成员的数据量过大,一个hash类型的key,它的成员数量虽然只有1000个,但是这些成员的value总值大小为100MB。
可以使用 memory usage key来查看,如:
124.223.47.250_6379:0>set user:age:1 28
124.223.47.250_6379:0>memory usage user:age:1
"56"
124.223.47.250_6379:0>set user:name:1 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
124.223.47.250_6379:0>memory usage user:name:1
"104"
但是这个命令对于CPU的耗能较大,我们可以通过预估,可以通过strlen key来预估也行,集合类型,可以通过判断元素的类型来判断。
bigkey的危害
- 网络阻塞 对bigkey执行读请求时,少量的qps就可能导致带宽使用率占满,导致redis实例变慢。比如bigkey为1MB,客户端每s访问量是1000,那么每秒产生差不多1G的流量,普通的千兆网卡承受不了的。
- 数据倾斜 多点部署下,通过key来分配插槽,如果有bigkey的插槽,它的内存使用率超过其他机器,就不能达到数据内存资源均衡。
- redis阻塞 元素较多的hash、list、zset等集合做运算会耗时较久,导致主线程阻塞,因为redis是单线程的,同一时间只能处理一个请求。
- cpu压力
redis读写都会进行序列化和反序列化,bigkey会导致cpu的使用率飙升。如果cpu占满了,那大家都不用完了。
如何发现bigkey
使用 --bigkeys
使用redis-cli -a 123456 --bigkeys命令,切记在slave节点执行,因为 --bigkeys也是扫描数据,会造成其他线程阻塞。如:
[root@VM-4-9-centos etc]# redis-cli -a 123456 --bigkeys
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far '"name"' with 48 bytes
[00.00%] Biggest hash found so far '"blog:order:user:1"' with 3 fields
[00.00%] Biggest set found so far '"user1:ids"' with 5 members
[00.00%] Biggest zset found so far '"student"' with 4 members
-------- summary -------
Sampled 17 keys in the keyspace!
Total key length in bytes is 220 (avg len 12.94)
Biggest hash found '"blog:order:user:1"' has 3 fields
Biggest string found '"name"' has 48 bytes
Biggest set found '"user1:ids"' has 5 members
Biggest zset found '"student"' has 4 members
0 lists with 0 items (00.00% of keys, avg size 0.00)
1 hashs with 3 fields (05.88% of keys, avg size 3.00)
13 strings with 127 bytes (76.47% of keys, avg size 9.77)
0 streams with 0 entries (00.00% of keys, avg size 0.00)
2 sets with 9 members (11.76% of keys, avg size 4.50)
1 zsets with 4 members (05.88% of keys, avg size 4.00)
我们直接看summary中,排名第一的就是数据量最大的,下面就是平均值。只返回每个数据的top1的bigkey。
这种有缺陷,因为只是返回排名第一的,难道排名第二的就一定不是bigkey吗?
scan扫描
可以自己编程,通过scan命令来扫描,切记一定不能通过 keys *,这个命令一般生成环境禁用。 如:
127.0.0.1:6379> scan 0
1) "30"
2) 1) "name"
2) "blog:order:user:1"
3) "go:user:name"
4) "user1:ids"
5) "ad"
6) "key1"
7) "student"
8) "mmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmm"
9) "num"
10) "mmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmm"
127.0.0.1:6379> scan 30
1) "0"
2) 1) "user:ids"
2) "ac"
3) "user:age:1"
4) "user:name:1"
5) "key"
6) "ab"
7) "master"
默认一次返回10条。第一次scan 0,会返回一个30,表示第二次从30开始,返回0,表示结束。
我们拿到key之后,获取类型,然后利用strlen/hlen等命令判断key的长度,千万不要使用 memory usage命令。
第三方工具
比如redis-rdb-tools等等分析。
如何处理bigkey
在我们找到bigkey之后,并不能直接删除,因为现在删除了,后续还会再加进来,总归治标不治本。
我们的原则是,拆分bigkey,比如字符串类型的就减少字符串长度,将一个字符串拆分几个小的字符串。非字符串就较少元素数量等等。
如果 big keys 无法避免,那获取数据尽量不要把所有的数据都取出来,就使用分段的方式取出数据。
恰当的数据类型
比如存储一个User对象,一般来说有三种方式:
- 使用json字符串
124.223.47.250_6379:0>set user:1 {124.223.47.250_6379:0>name:milo,age:30}
"OK"
124.223.47.250_6379:0>get user:1
"{124.223.47.250_6379:0>name:milo,age:30}"
这种方式的优点:实现简单粗暴。但缺点是:数据耦合不够灵活,比如我想修改name,必须要全部拿出来修改完成后再塞进去。 但一般也是常用的处理方式。
- 字段打散存储,如key:user:
124.223.47.250_6379:0>set user:1:name milo
124.223.47.250_6379:0>set user:1:age 30
124.223.47.250_6379:0>get user:1:name
"milo"
124.223.47.250_6379:0>get user:1:age
30
这种方式的优点是可以灵活访问对象的任意字段,但是缺点确实占用空间大,没办法做统一控制,优点脱裤子放屁的感觉,下下策。
- 使用hash-最佳实践
124.223.47.250_6379:0>hset user:1 name milo
"1"
124.223.47.250_6379:0>hset user:1 age 30
"1"
124.223.47.250_6379:0>hget user:1 name
"milo"
124.223.47.250_6379:0>hgetall user:1
1) "name"
2) "milo"
3) "age"
4) "30"
这种优点是空间占用小,底层为ziplist,也可以灵活访问对象的任意字段,也可以获取全部字段。 虽然缺点是代码相对复杂,操作起来优点繁琐。但只要写好了工具类,这种方式是上上策。最佳实践。
比如有个hash类型的key,其中有100w对field和value,field是自增id,这个key存在什么问题,该如何优化?
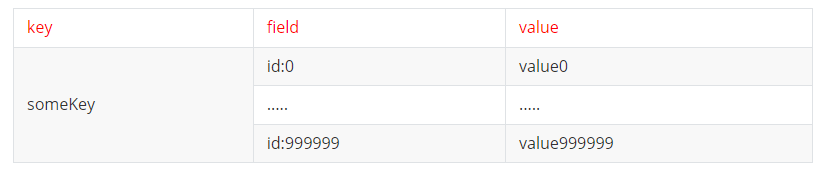
存在的问题是:hash的entry数量超过500时,会使用hash表而不是ziplist了,内存占用比较多。虽然可以通过配置调整上线,但是会超出bigkey。
优化的方式:
拆分成string类型 虽然解决了bigkey问题,但是内存占用更多了,而且想要批量获取这些数据比较麻烦。
可以把拆分成小的hash,比如可以将id/100作为key,将id%100zuowei field,这样每100个元素为一个hash。

