知其然,知其所以然,要知道redis数据结构底层是什么,所以要先知道底层有什么。
动态字符串SDS
我们知道redis,key是字符串类型,value一般是字符串或者是字符串的集合,所以字符串是redis中最常用的一种数据结构。
redis虽然是C语言编写,但是并没有直接使用C语言中的字符串,因为C语言字符串存在一些问题,如:
C语言字符串常见问题
// C语言声明一个字符串
char* s = "HELLO"
// 本质都是字符数组,且最后都会带一个\0的标识
// {'H','E','L','L','O','\0'}
获取字符串长度需要通过运算
因为这样在内存里面呢,也不用关系这个数组的长度,它直接从开始位置开始读,读到\0呢,就表示结束了,相当于一直标志位了。这样带来的问题,就是获取字符串长度的时候,需要通过运算。这样的时间复杂度呢,可能达到O(n)。
非二进制安全
如上,我们读取的时候,通过一个个读取,直到\0结束,那有一种常见,就是我们的字符串里面,恰巧有一个'\0',是不是意味着我没有读取完,就结束呢?虽然C语言不能出现'\0'的特殊字符,但redis不能够的。
不可修改
""中定义的字符串,都是保存在内存的常量池的。这意味着你不能通过给字符串赋新的值来修改字符串的内容。你可以使用函数来构造新的字符串,但是你不能直接改变已经存在的字符串。
如上问题,Redis就自己构建了一个新的字符串结构,称为简单动态字符串(simple dynamic string),简称SDS。
Redis-SDS
redis是C写的,SDS是在C语言的字符串之上再包装了一层作为其结构体。
struct __attribute__ ((__packed__)) sdshdr8{
uint8_t len; //buf已保存的字符串字节数,不包含结束标识符\0
uint8_t alloc; //buf申请的总的字节数,不包含结束表示
unsignd char flags; // 不同的SDS的头类型,用来控制SDS的头大小,
char buf[]; // 真正存储的字符数组
}
其中 flags,因为在源码中,其实定义了很多的头,比如:
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
这有什么用呢?比如sdshdr17,他的长度是uint16的,16个bit,所以他的长度最多就是2^16-1,也就是可以存储65535个字节。还有32/64的,所以他支持的更大的字符串,所以redis根据使用场景,定义了5中类型的sds字符串类型,分别是:
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
所以,flags就是用来控制头类型大小的。 比如,一个包含字符串'milo'的sds结构,以及申请的内存空间如下:

- len,milo四个字节,所以len就是4.
- 第一次申请的时候,len和alloc一般是一样的,所以申请的空间也是4.
- 因为milo占4个字节,完全可以使用uint8来表示,所以flags呢,就是1.
- 后面就是连续的数组了,连续的内存空间。因为要跟c语言兼容,所以会有\0标识.
为什么叫做动态?
之所以叫做动态,说明它具备动态扩容的能力,比如在上面的milo中改为hi,milo,那上面我们申请的空间4明显不够用了,怎办?这里会申请新内存的空间,当然有不同的算法:
- 如果新字符串小于1M,则新空间扩展后字符串长度的两倍+1,+1是后面有个标识.
- 如果新字符串大于1M,则新空间为扩展后字符串长度+1M+1,这种为内存预分配。
所以hi,milo,在milo的基础上结构为:
其中alloc为12,因为它不包含结束标识,但是申请的内存变为了13。
所以它的优点是:
- 获取字符串的长度,直接在结构体中可以查看出。无序遍历。
- 支持动态扩容
- 减少内存分配此时
- 二进制安全
IntSet
intset是redis中set集合的一种实现方式,基于整数数组来实现的,并且具备长度可变、有序等特征。
结构体
typedef struct intset {
uint32_t encoding; // 编码方式,支持存放16位,32位,64位整数,决定contents的存储范围大小。固定占4字节
uint32_t length; // 元素个数,固定占4字节
int8_t contents[]; // 整数数组,保存集合数据,这就是一个指针,指向具体指的地址。
} intset;
其中的encoding包含了三种模式,表示存储的整数大小不同:
/* Note that these encodings are ordered, so:
* INTSET_ENC_INT16 < INTSET_ENC_INT32 < INTSET_ENC_INT64. */
#define INTSET_ENC_INT16 (sizeof(int16_t)) // 2字节整数,范围类似java的short,数值范围为正负2^16-1,-32768到32767
#define INTSET_ENC_INT32 (sizeof(int32_t)) // 4字节整数,范围类似java的int
#define INTSET_ENC_INT64 (sizeof(int64_t)) // 8字节整数,范围类似java的long
为了方便查找,redis会将intset中所有的整数按照依次保存在contents数组中,如存入10,20,30的结构如下:

数组中每个数字都在int16_t的范围内,所以这三个编码都是INTSET_ENC_INT16,都是2两个字节。
- encoding:INTSET_ENC_INT16,4个字节
- length:4个字节
- contents:2字节*3=6字节
这里要着重说明一下,在contents中,存储的其实在指针的内存地址,真实的内存存储应该是:

也就是为什么要固定encoding的原因,比如起始指针为001,如果固定了encoding的话,我就可以找任意一个index对应的指针了。通过指针就可以找到内存中具体的值。
公式 targetPtr=startPtr+(sizeof*index) ,
比如我要找第三个元素,那么index=2, 就是 1+2*2=5,也就找到了30。
这也是为什么 所有的index都需要从0开始的原因,因为该公式适应一切。
动态扩容,如何做?
如上,刚刚我们存储了10,20,30,其实都是在int16之中,也就是两个字节数,在上面数组中又加入了,40000,已经超过了intset_enc_int16所表达最多的32767,如何?
那么会做如下操作:
- redis会升级新的编码为INTSET_ENC_INT32,也就是每个整数占4字节,并且按照新的编码方式及元素个数进行扩容数组。
- 然后倒序依次将数组元素拷贝到扩容后的正确位置。因为正序的话会覆盖到其他内存地址。所以是先扩容,然后把最后一个先放到它自己的位置,位置就是通过 sizeof*index来计算的。
- 然后再把待添加的元素放到数组的末尾。
- 扩容后,角标是没有变化的。
底层源码为:
/* Insert an integer in the intset */
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
//获取当前值编码
uint8_t valenc = _intsetValueEncoding(value);
// 要插入的位置
uint32_t pos;
if (success) *success = 1;
/* Upgrade encoding if necessary. If we need to upgrade, we know that
* this value should be either appended (if > 0) or prepended (if < 0),
* because it lies outside the range of existing values. */
if (valenc > intrev32ifbe(is->encoding)) { // 判断编码是不是超过了当前inset的编码,是的话则需要升级,我们只看升级情况
/* This always succeeds, so we don't need to curry *success. */
return intsetUpgradeAndAdd(is,value);
}
}
/* Upgrades the intset to a larger encoding and inserts the given integer. */ // 这里注释不合适,应该是大或者小都有可能的,大扩容,小搜索。
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
// 获取当前intset编码
uint8_t curenc = intrev32ifbe(is->encoding);
// 重新获取新编码
uint8_t newenc = _intsetValueEncoding(value);
int length = intrev32ifbe(is->length);
// 判断新元素是大于0还是小于0,大于0插入队首,小于0插入队尾。
int prepend = value < 0 ? 1 : 0;
/* First set new encoding and resize */
is->encoding = intrev32ifbe(newenc); //重置为新编码
is = intsetResize(is,intrev32ifbe(is->length)+1); // 数组大小重置
/* Upgrade back-to-front so we don't overwrite values.
* Note that the "prepend" variable is used to make sure we have an empty
* space at either the beginning or the end of the intset. */
while(length--) // 倒序遍历,逐个搬运元素到新位置
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc)); // 按照最新的编码插入新元素
/* Set the value at the beginning or the end. */
if (prepend)
_intsetSet(is,0,value);
else
_intsetSet(is,intrev32ifbe(is->length),value); // 这里采用的是二分法来查询需要的值
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
所以,它的优点是:
- redis会确保intset中的元素唯一、有序
- 具备类型升级机制,节省内存空间
- 底层采用二分法查找方式来查询
Dict
dictionar,字典的缩写,我们知道,redis是一个键值型的数据库,所以我们可以根据键实现快速的增删改查。而键和值的映射关系就是通过Dict来实现的。
dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)和字典(Dict)。
结构
typedef struct dictht {
dictEntry **table; // entry是数组,数组中保存了指向entry的指针
unsigned long size; // 哈希表大小,值为2的N次方。
unsigned long sizemask; // 哈希表大小的掩码,总等于size-1
unsigned long used; // entry个数
} dictht;
typedef struct dictEntry {
void *key; // 键
union { // 联合体,可能是下面四个中的其中一个或多个,但是不能同时存在
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; // 值
struct dictEntry *next; // 下一个entry的指针
} dictEntry;
typedef struct dict {
dictType *type; // dict类型,内置不同的hash函数
void *privdata; // 私有数据,在做特殊hash运算时用到
dictht ht[2]; // 一个dict包含两个hash表,一个做当前数据,一个一般为空,只是在rehash时用到
long rehashidx; /* rehashing not in progress if rehashidx == -1 */ // rehash的进度,-1表示为进行
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */ //rehash是否暂停,1暂停,0继续。
} dict;
那,向dict添加键值对的时候,如何做呢?
当我们向dict添加键值对的时候,首先要算出key的hash值(h),然后利用h&sizemask来计算元素应该存储到数组中的哪个索引位置。
添加
假设,里面是空的,第一次添加元素,键值对为:k1=v1,假设k1的hash值h,=1,则1&3=1,因此k1=v1要存储在角标为1的位置。如下图:

此时,又来了另外一个,k2=v2的键值对,假设k2的hash值h也是1,所以,会在当前node的前驱新增一个node,然后把当前node作为新增node的next。这样就形成了一个链表结构。

所以,新来的都是加载队首,这样他的下一个节点就是之前的队首。比较方便。
扩容
以上我们知道,dict中的hashtable就是数组结合单向链表的实现,当集合中元素较多时,比如导致hash冲突增多,比如上述例子都是存在了1之中,这样产生链表。链表一旦过长则查询效率大大降低。最后都退化到跟链表一样,那这性能就太差了。因为链表的查询性能很差。
所以需要扩容,dict在每次新增键值对的时候,都会检查负载因子(loadfactor=used/size),满足一下两种情况的时候会触发hash表扩容:
- hash表的loadfactor>=1,并且服务器没有执行bgsave或者bgrewriteaof等后台进程。
- hash表的loadfactor>=1。
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio) &&
dictTypeExpandAllowed(d))
{
return dictExpand(d, d->ht[0].used + 1);
}
return DICT_OK;
}
当然,除了扩容之外,每次删除元素的时候,也会对负载因子做检查,当loadfactor<0.1的时候,会对hash表做收缩。
ZipList
ziplist是一种特殊的‘双端链表’,由一系列特殊编码的连续内存块组成。可以由任意一端进行压入/弹出操作,并且该操作的时间复杂度为O(1). 架构如下图:
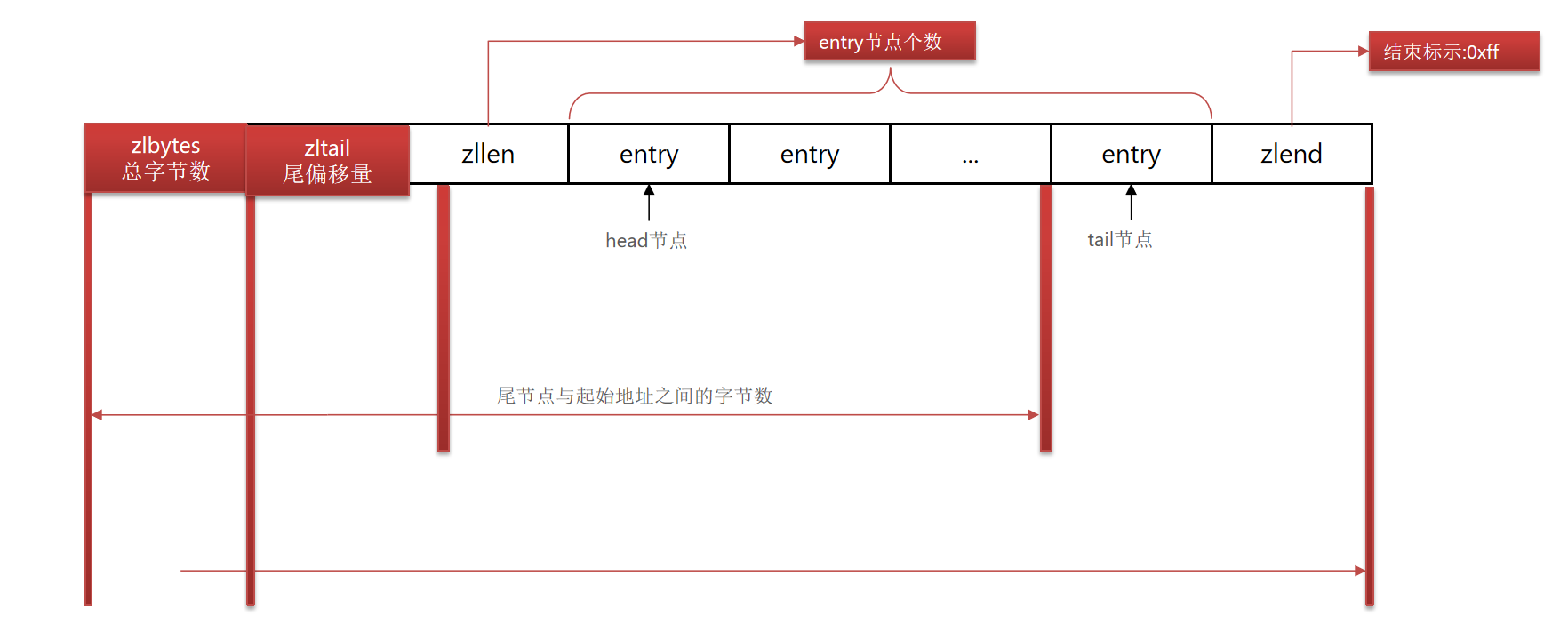
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zbytes | uint32_t | 4字节 | 记录整个压缩列表的内存字节数 |
| zltail | uint32_t | 4字节 | 记录压缩列表表尾节点距压缩列表的起始地址有多少字节,通过这个偏移量确定表尾节点的地址 |
| zllen | uint16_t | 2字节 | 记录压缩列表包含的节点数量。最大值为65534,如果该数此处记录为65535,真实数需遍历整个压缩列表得出 |
| entry | 列表节点 | 不定 | 压缩列表包含的各个节点,节点长度由节点保存的内容决定 |
| zlend | uint8_t | 1字节 | 特殊值 oxff,用于标记压缩列表的末端 |
那,entry长度不固定,如何进行寻址和遍历呢?有没有指针。又不是数组又不是链表的。
entry结构
ziplist中的entry并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用16个字节,浪费内存。它采用了三个字段进行声明:

- previous_entry_length:前一节点的长度,占1个或者5个字节。
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值。
- 如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为固定为0xfe,后四个字节才是真实的长度数据。
- encoding:编码属性,记录contents的数据类型,是字符串还是整数以及长度,占用1个、2个或5个字节。
- contents:负责保存节点的数据,可以是字符串或者是整数。
所以。entry为什么要这么设计?
如果说我知道当前这个entry的起止位置,由于是连续的空间,所以我知道当前的entry的地址,再加上当前的三个字段的总和,是不是就可以得出下一个节点的地址了。这样就实现了正序遍历。当然,倒着来,就是前一个节点的起始地址了。
所以没有采用双向指针,因为一个指针占8个字节,两个就是16.是通过计算长度来算出上一个节点和下一个节点的位置。
但是 encoding的编码,是比较复杂的。
encoding结构
ziplistentry中的encoding编码分为字符串和整数两种。
字符串
如果encoding是以 "00"、"01"、"10"开头,则表示contents是字符串。它的编码长度由1bytes、2bytes、5bytes三种。如下:
| 编码 | 编码长度 | 字符串大小 |
|---|---|---|
| \00xxxxxx\ | 1 bytes | 字符串长度<=63 bytes |
| \01xxxxxx\xxxxxx\ | 2bytes | 字符串长度<=16383 bytes |
| \10000000\xxxxxxxx\xxxxxxxx\xxxxxxxx\xxxxxxxx | 5 bytes | 字符串长度<=42亿 bytes |
可见,一般来说我们遇到的都是00或者是01开头的,因为字符串长度都是在1或者2个字节的。
比如存两个字符串,"ab"和"bc"。
a对应的ASCII码为97,二进制为 01100001 ,十六进制为0x61
b对应的ASCII码为98,二进制为 01100010 ,十六进制为0x62
c对应的ASCII码为99,二进制为 01100011 ,十六进制为0x63
所以ab就是:
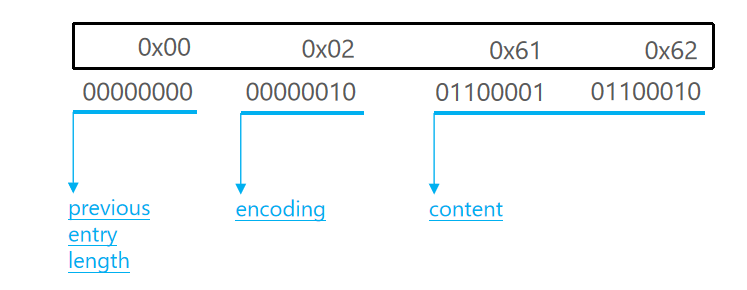
- ab的编码长度肯定是1bytes表示,所以开头就是00,ab为两个字节数,也就是2,2的二进制就是10,前面补四个零。也就是encoding为00000010,16进制就是0x02
- 前一个字节的长度,都是空的,也就是0.
- content,如上,a和b对应的二进制的16进制就是,0x61,0x62.
所以,ab整个entry就是占4个字节。第一个字节就是前一个字节的长度,第二个字节就是encoding,第三、四个字节表示content内容。
ab和bc
ab和ac整个ziplist的结构如下:
ab后面插入bc的话,bc就是紧邻ab后面的一片空间,即:
- 第五部分entry结构中的previous长度,就是ac,ac占四个字节,所以是0x04,再后面的encoding编码长度也是0x02,后面两位表示content。
- 第一部分为头,tlbytes,头表示总字节数,就是如上的4+4+2+4+4+1为19,19的16字节为13,但是小端表示,就是13在第一位。
- 第二部分为尾偏移量,tltail,就是从起始地址到最后一个节点之间的字节数,也就是4+2+4+4为14。
- 第三部分就是tlen,我们存了两个部分,ab和ac,也就是len为2.
- 最后为结束标识。oxff。
数字标识
两位表示,其中 "00"、"01"、"10"开头为字符串,所以数组就只能是11了。所以如果encoding是以“11”开始,则证明content是整数,且encoding固定只占用1个字节。
| 编码 | 编码长度 | 字符串大小 |
|---|---|---|
| 11000000 | 1 | int16_t(2 bytes) |
| 11010000 | 1 | int16_t(4 bytes) |
| 11100000 | 1 | int16_t(8 bytes) |
| 11110000 | 1 | 24为有符号数(3 bytes) |
| 11111110 | 1 | 8位有符号数(1 bytes) |
| 1111xxxx | 1 | 直接在xxxx位置保存,从0001-1101,减1后结果为实际值 |
例如:一个ZipList中包含两个整数值:“2”和“5”

ziplist的连锁更新问题
ziplist的每个entry都包含了前一个字节来记录上一个字节的大小,长度为1或者5个字节。
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于等于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据
有一种情况,可能会在扩容的时候,把之前的节点为小于254长度变为大于254了,那么前一个节点动态需要扩为5个字节来保存,这样所有的节点的前一个节点都需要修改。这种特殊情况下产生的连续多次空间扩展操作,就是连锁更新,新增和删除都可能导致连锁更新问题的发生。
虽然这个概率比较低,因为需要有N个连续的,长度在250-253字节之间的entry,这种临界点。
目前这个问题,redis作者并未解决,因为这个概率比较低,而且影响范围要根据N的个数来,如果是几个的话,那没有影响。
后续博主查看到,在redis7.2之后,已经更新新结构为listpack,并且应用在set当中。
listpack
总结
ziplist是一个连续内存的压缩列表,所以他节省内存,连续内存访问效率较高。但是连续内存如果需要的访问空间可控是有利的,如果是过大的内存空间,再申请内存的时候就比较麻烦了,因为找到连续的内存是比较困难的,所以ziplist不能添加过多的数据。
QuickList
上述的ziplist的问题,如果数据很大,占用的内存很多,而申请的内存效率很低,如何破?
为了缓解这个问题,要必须限制ziplist的长度和entry大小。但是你限制住了,就是要存储大量数据怎么办?这个数据已经超出了ziplist最佳的上限了。
所以,可以创建多个ziplist来分片来存储数据。
但是,拆分后,不方便管理和查找,分片和分片如何建立联系呢?
ok,QuickList来了,它是一个双向链表,只不过链表中的每个节点都是ziplist,它把ziplist给关联起来了。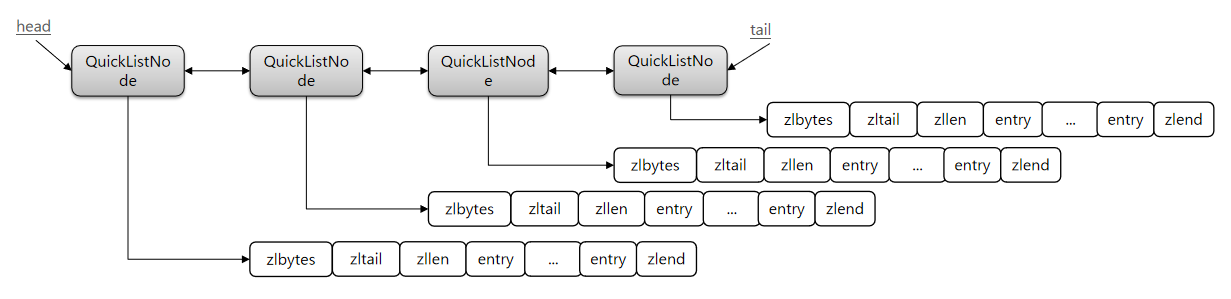
所以这种好处就是,一方面它限制了ziplist的大小,从而避免了内存申请的问题,又整理了多个ziplist分片来存储。又使用了链表将他们管理,串联起来。
相关优化
限制ziplist配置
通过配置: list-max-ziplist-size来限制,如下:
# Hashes are encoded using a memory efficient data structure when they have a
# small number of entries, and the biggest entry does not exceed a given
# threshold. These thresholds can be configured using the following directives.
hash-max-listpack-entries 512
hash-max-listpack-value 64
# Lists are also encoded in a special way to save a lot of space.
# The number of entries allowed per internal list node can be specified
# as a fixed maximum size or a maximum number of elements.
# For a fixed maximum size, use -5 through -1, meaning:
# -5: max size: 64 Kb <-- not recommended for normal workloads
# -4: max size: 32 Kb <-- not recommended
# -3: max size: 16 Kb <-- probably not recommended
# -2: max size: 8 Kb <-- good
# -1: max size: 4 Kb <-- good
# Positive numbers mean store up to _exactly_ that number of elements
# per list node.
# The highest performing option is usually -2 (8 Kb size) or -1 (4 Kb size),
# but if your use case is unique, adjust the settings as necessary.
list-max-listpack-size -2
继续压缩ziplist
控制ziplist外,quicklist还对节点的ziplist继续做压缩。通过配置 list-compress-depth来控制。因为链表一般是从首尾访问较多,所以首尾不压缩,而中间访问的频率是比较低的。所以这个参数是控制首尾不压缩的节点个数:
# Lists may also be compressed.
# Compress depth is the number of quicklist ziplist nodes from *each* side of
# the list to *exclude* from compression. The head and tail of the list
# are always uncompressed for fast push/pop operations. Settings are:
# 0: disable all list compression
# 1: depth 1 means "don't start compressing until after 1 node into the list,
# going from either the head or tail"
# So: [head]->node->node->...->node->[tail]
# [head], [tail] will always be uncompressed; inner nodes will compress.
# 2: [head]->[next]->node->node->...->node->[prev]->[tail]
# 2 here means: don't compress head or head->next or tail->prev or tail,
# but compress all nodes between them.
# 3: [head]->[next]->[next]->node->node->...->node->[prev]->[prev]->[tail]
# etc.
list-compress-depth 0
源码
typedef struct quicklist {
quicklistNode *head; // 头结点指针
quicklistNode *tail; // 尾结点指针
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistNode {
struct quicklistNode *prev; // 前一个节点指针
struct quicklistNode *next; // 下一个节点指针
unsigned char *zl;// 当前节点ziplist指针
unsigned int sz; // 当前节点ziplist字节大小
unsigned int count : 16; // 当前节点ziplist的entry个数
unsigned int encoding : 2; // 编码方式,1:ziplist,2:lzf压缩模式
unsigned int container : 2; // 容器类型,预留字段,1:其他,2:ziplist
unsigned int recompress : 1; // 是否被解压了,1:解压了,后面要重新压缩
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
总结
quicklist的特点:
- 是一个节点为ziplist的双端链表
- 节点才用过ziplist,解决了传统链表的内存占用问题
- 控制了ziplist大小,解决了连续内存空间申请效率问题
- 中间节点可以压缩,进一步节省了内存
但是总归是链表,链表我们知道,插入、删除简单,但是查找比较麻烦。
SkipList
quicklist是链表形式,查找首尾的性能可以,但是查找中间元素性能较差。
那么skiplist,来了。
skiplist首先还是链表,但是他和传统链表相比又有几点差异:
正常的链表查找,都是一个个的找,比如a->b->c->d,要找到c必须要找到b,一个个节点往后找,但是skiplist不是,顾名思义,它是跳着找,所以叫做跳表。
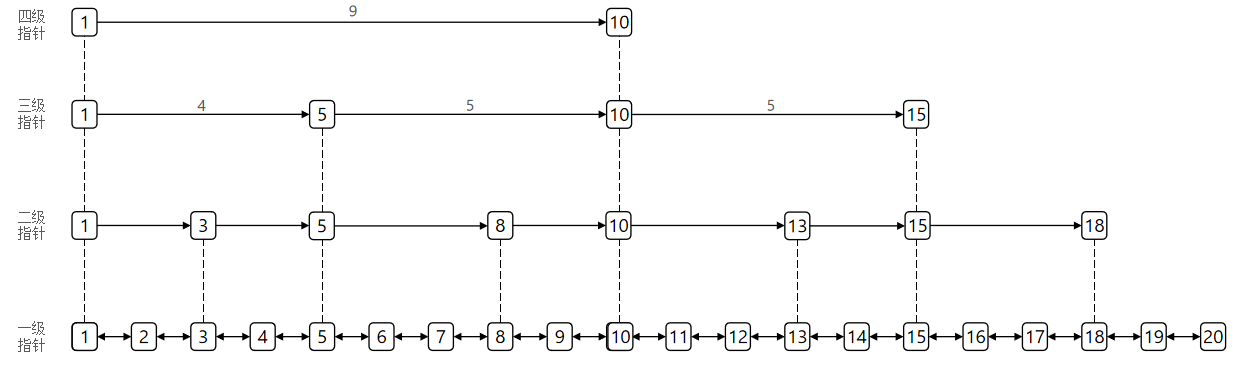 前提是,它所有的元素必须按照升序排列存储。
前提是,它所有的元素必须按照升序排列存储。
如上图,我如果想从1号找到10号,可以直接建立一个指针指向10号。所以他的跨度就是9。那么建立起来之后,我如果想找到11号,是不是找到了10号,11号就在下一个节点,也就是两次就找到了。
那如果是找16号呢?是不是先找到10再下一节点的找?并不是,直接从10号节点和16号节点建立链接,这样找到16,就是先找到10,然后就找到了16,找两次。
或者是1号节点和15号节点再次建立链接,这样也就通过15来和16进行查找,也是两次。
这就说明,当前节点可以和多个节点家里指针,这就是指针级数,最多可以建立32级指针。但是指针和指针之间的倍数是指数递增的,32级也就是2^31数量。
这性能差不多和红黑树或者是二分查找差不多了。
一直觉得,跳表符合,六度分隔理论:世界上任何两个互不相识的人,最多只需要通过 6 个中间人,就可以建立联系。
源码:
typedef struct zskiplist {
// 头尾节点指针
struct zskiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 最大的索引层级,默认是1
int level;
} zskiplist;
typedef struct zskiplistNode {
sds ele; // 节点存储的值
double score;// 节点分数,排序、查找用
struct zskiplistNode *backward; // 前一个节点指针
struct zskiplistLevel {
struct zskiplistNode *forward; // 下一个节点指针
unsigned long span; // 索引跨度
} level[]; // 多级索引数组
} zskiplistNode;
总结
- 跳跃表是一个双向链表,每个节点都包含了score和ele值(保存的数据)
- 节点按照score值排序,如果score值一样则按照ele字典排序,排完序之后就形成了指针
- 每个节点都可以包含多层指针,层数是1-32之间的随机数,当然也不是真正随机,是有一个算法去推测究竟多少级最佳。
- 不同层数指针到下一个节点的跨度不同,层级越高,跨度越大
- 增删改查效率基本和红黑树一致,实现却更简单
RedisObject
ok,到这里,以上的动态字符串SDS、DICT、ZIPLIST、QUICKLIST、SKIPLIST这五种都是最底层的数据结构了,他们在redis中不是直接使用,而是要封装到一个数据类型中,这个数据类型,就是RedisObject,也叫做Redis对象,也就是redis中的任意数据类型的键和值都会被封装盗RedisObject中。源码如下:

我们来计算下,一个redisobject占多少内存:
type 4 bit + encoding 4 bit + lru 24 bit +refcount 32bit + ptr 64bit = 128 bit = 16 byte
所以一个redisObject占用16字节,不包含指针指向的空间。
假设我有10个字符串,如果我存一个集合,那么一个集合是一个对象,需要一个redis头,也就是16字节表示头信息,其他都是真实存储。
但是如果我存10个字符串,那么需要160字节表示头信息,所以大量内存浪费在头信息去了。当然看业务,如果只能使用字符串来表示,那就使用字符串吧。
编码方式
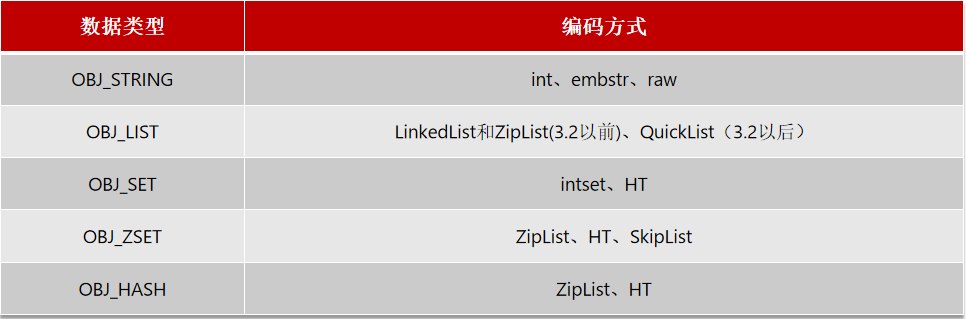
如上的encoding,由11中编码方式,那么这11种具体是什么呢? 如下: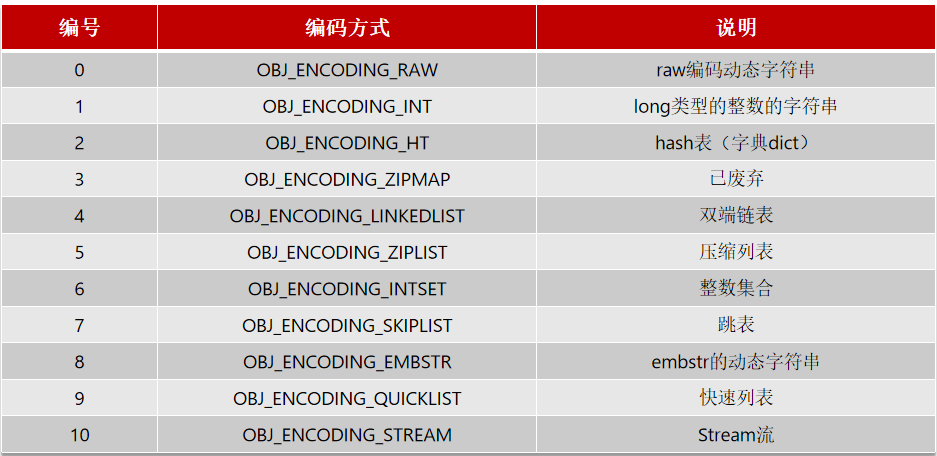
那我们redis中,每种数据类型,究竟对应哪些编码呢?