
知其然,知其所以然,知道redis底层是什么,才知道如何选择最优解。
可以先简单看看 redis底层数据结构介绍 ,来了解底层有哪些数据结构。
在redis中,我们有五种数据类型,分别是:string/list/set/zset/hash,至于其他的都是这五种的派生。
string
最常见的数据类型,编码有三种,常见的是raw。
RAW
就是基于简单动态字符串(SDS)实现的,存储上限为512MB,当然我们肯定不能存储这么大,不然就产生了bigkey。
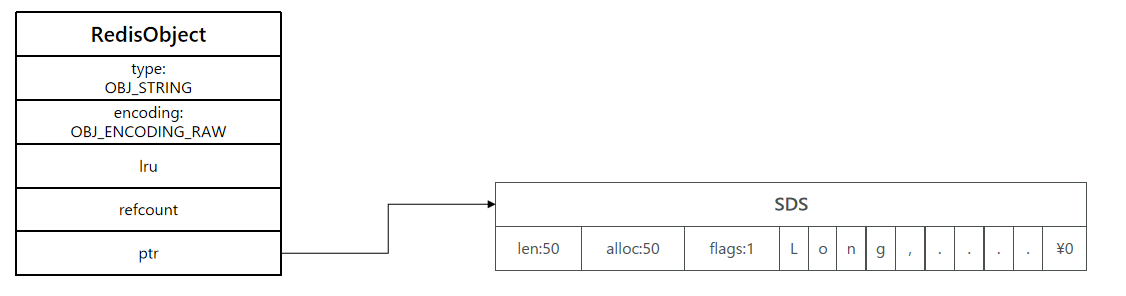
- 关于redisObject,可以看上述链接最后有介绍,也就是redisobject就是头结点信息。每个数据类型都有。
- 可以看到,type是string,encoding为raw,ptr是指向了底层的一个SDS实现的对象的指针。也就是有两块内存空间,先申请头部,再申请对象的。
但是,string还有一种类型,就是embstr,定义为:如果存储的SDS长度小于44字节,则采用EMBSTR编码,此时object head与SDS是一段连续的空间。(上述的是两个空间,通过ptr指针链接)。
EMBSTR
存储的sds长度小于44字节时,结构如下:

也就是连续内存的话,就是在一块,申请内存时只需要调用一次内存分配函数,效率更高。
为什么小于44呢?先看下图
 44个字节的话,非常下,1个字节就能表示,采用的结构就是sds_type_8。
44个字节的话,非常下,1个字节就能表示,采用的结构就是sds_type_8。
- 也就是len和alloc、flags各占1个字节,说明sds的Header为3字节+尾部\0,合在一起4个字节。
- 字符串44个字节+头尾4个字节,就是48个字节。
- redisObject一起16个字节+48个字节=64个字节。
redis在分配内存的时候是jemalloc算法,它是通过2的N次方来分配,宁多勿少,多了的就是内存碎片了。64字节凑巧是2^6,一个分片大小,没有丁点的内存碎片的产生。
所以在使用string的时候,尽量超过44个字节。
INT编码
当存储的字符串是整数值,并且大小在long_max(long类型的最大值)范围内,则采用int编码,也就是直接保存数据在redisobject的ptr指针位置(刚好是8字节),就不需要SDS了。因为数组可以直接转成二进制位去表示了,这样更加节省内存了。

测试
124.223.47.250_6379:0>set name milo
124.223.47.250_6379:0>object encoding name
"embstr"
124.223.47.250_6379:0>set name milooooooooooooooooooooooooooooooooooooooooooooooooooo
124.223.47.250_6379:0>object encoding name
"raw"
124.223.47.250_6379:0>set age 30
124.223.47.250_6379:0>object encoding age
"int"
所以在使用string的时候,尽量超过44个字节。能用数值表示,尽量用数值。
List
一个双向链表结构,也就是既可以支持正向检索,也可以支持反向检索。也就是即可当做队列来用,也可当做栈来用。
在底层数据结构时候发现,符合链表的是:
- linkedlist:普通链表,没研究
- ziplist,压缩链表,可以从双端访问,内存占用低,存储上限低。
- quickList,ziplist增强版,双端访问,内存占用低,包含多个ziplist,存储上限高。
所以,quickList胜出。
在3.2版本之前,Redis采用ZipList和LinkedList来实现List,当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则采用LinkedList编码。
在3.2之后,redis统一采用QuickList来实现了。
内存结构
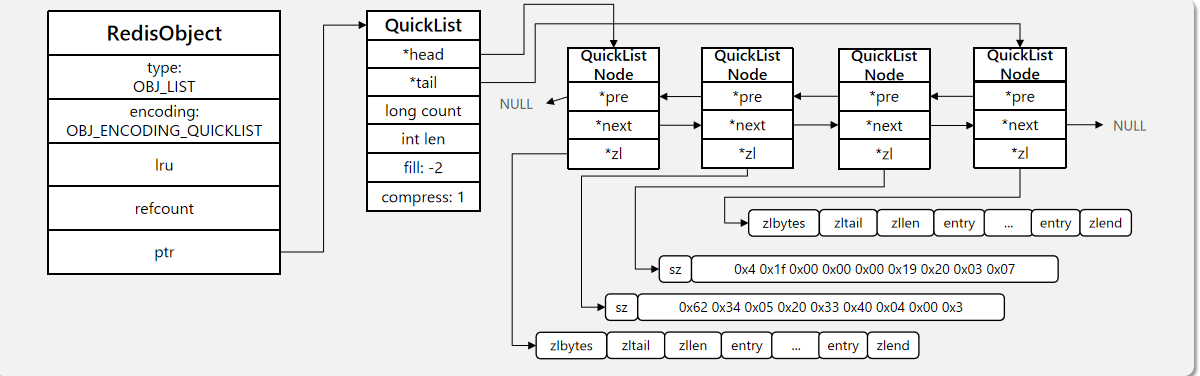
- 类型是List,编码是QuickList,指针指向一个QuickList。
- quickList里面有首尾节点,每个首尾节点都指向了一个QuickListNode,
- 每个QuickListNode,都有一个指向了zipList
源码
void pushGenericCommand(client *c, int where, int xx) {
int j;
// 判断元素大小,不能超过list_max_item_size
for (j = 2; j < c->argc; j++) {
if (sdslen(c->argv[j]->ptr) > LIST_MAX_ITEM_SIZE) {
addReplyError(c, "Element too large");
return;
}
}
// 尝试找到key对应的list,你要push,你要往哪push呢?这里返回的,就是redisObject,本质就是list
robj *lobj = lookupKeyWrite(c->db, c->argv[1]); // argv:lpush key v1 v2, argv[1]就是key
// 检查类型是否正确
if (checkType(c,lobj,OBJ_LIST)) return; // 根据robj的type来校验类型是否正确
// 找不到的
if (!lobj) {
if (xx) {
addReply(c, shared.czero);
return;
}
// 如果为 创建新的quickList
lobj = createQuicklistObject(); // 首先创建quickList,申请内存,再创建RedisObject,设置编码为QuickList,设置指针,返回。
//创建完成后, 限制了配置,比如ziplist的大小,就是根据配置来的。比如首尾压缩深度
quicklistSetOptions(lobj->ptr, server.list_max_ziplist_size,
server.list_compress_depth);
dbAdd(c->db,c->argv[1],lobj); // 根据db添加进去
}
for (j = 2; j < c->argc; j++) {
listTypePush(lobj,c->argv[j],where); //添加进去
server.dirty++;
}
addReplyLongLong(c, listTypeLength(lobj));
char *event = (where == LIST_HEAD) ? "lpush" : "rpush"; // 判断命令从首尾?添加
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_LIST,event,c->argv[1],c->db->id);
}
Set
redis的set结构和go语言中的map[string]struct{},因为不关心value,只关心key。但是需要查询效率,也不关心顺序,但需要保证元素唯一,也就是存在插入,不存在插入。
可以看出,Set对查询元素的效率要求非常高,思考一下,什么样的数据结构可以满足?
可以看出,HashTable,也就是我们的Dict,可以满足。所以:
- 为了查询效率和唯一性,set采用HT(Dict),dict中的key用来存储元素,value统一为null。
- 当存储的所有数据都是整数,并且元素数量不超过
set-max-intset-entries时,set会采用intset编码以节省内存。
ps:在redis7.0之后,set已经弃用
set内存图
首先插入元素为 sadd s1 5 10 20
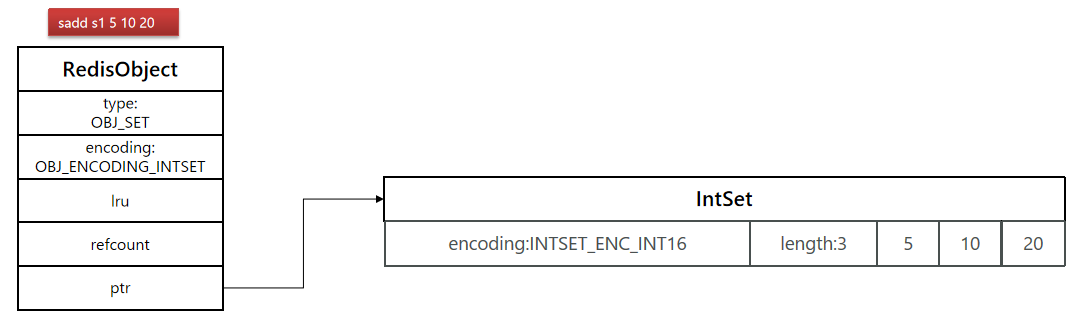
- 三个都是数值,直接采用intset格式进行存储,也就是ptr指向了intset对象。
此时 继续插入 sadd s1 m1
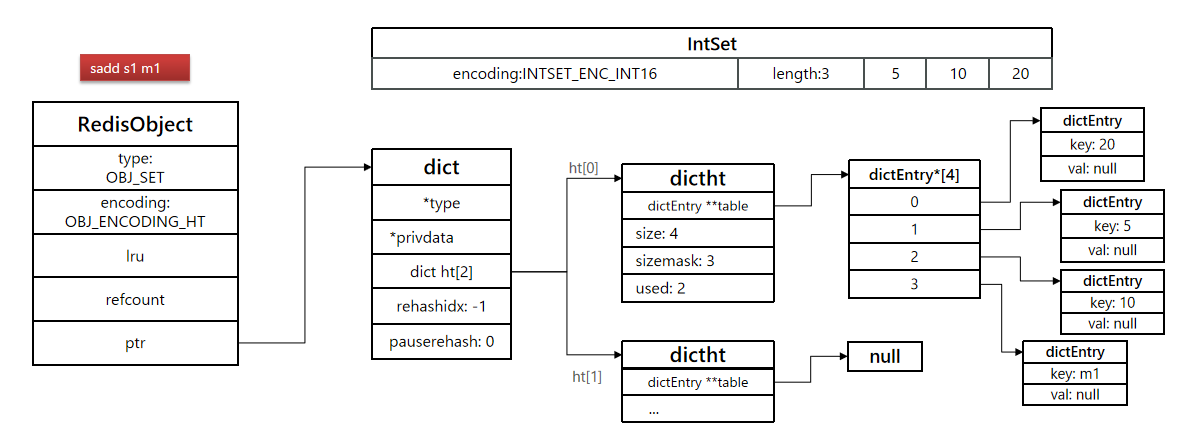
- 新建一个dict格式的对象,然后把之前的5,10,20都拷贝进去。
- 再把新加入的m1放进entry中。
- 所有的值,都放在了key中,value都是null,因为我们只需要关系key即可。
- 再把redisObject的encoding转为ht,且把ptr指向新的dict对象。
源码片段
创建redisObject
在首次创建对象的时候
robj *setTypeCreate(sds value) {
// 判断value是否是数值类型 long
if (isSdsRepresentableAsLongLong(value,NULL) == C_OK)
return createIntsetObject(); // 是的话采用intset编码
return createSetObject(); // 否则采用默认编码,也就是hashtable
}
robj *createIntsetObject(void) {
intset *is = intsetNew();
robj *o = createObject(OBJ_SET,is);
o->encoding = OBJ_ENCODING_INTSET; // 设置encoding为intset
return o;
}
robj *createSetObject(void) {
dict *d = dictCreate(&setDictType,NULL);
robj *o = createObject(OBJ_SET,d);
o->encoding = OBJ_ENCODING_HT; // 设置encoding为ht
return o;
}
判断是否要转换成ht
在每次add操作的时候
int setTypeAdd(robj *subject, sds value) {
long long llval;
if (subject->encoding == OBJ_ENCODING_HT) { // 如果已经是ht编码,直接添加元素
dictEntry *de = dictAddRaw(ht,value,NULL);
return 1;
} else if (subject->encoding == OBJ_ENCODING_INTSET) { // 如果是intset编码
if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) { // 添加的元素是整数
uint8_t success = 0;
subject->ptr = intsetAdd(subject->ptr,llval,&success);
if (success) {
/* Convert to regular set when the intset contains
* too many entries. */
size_t max_entries = server.set_max_intset_entries;
/* limit to 1G entries due to intset internals. */
if (max_entries >= 1<<30) max_entries = 1<<30;
if (intsetLen(subject->ptr) > max_entries)
setTypeConvert(subject,OBJ_ENCODING_HT); // 超过了数量,转成ht编码
return 1;
}
} else {
/* Failed to get integer from object, convert to regular set. */
setTypeConvert(subject,OBJ_ENCODING_HT); // 添加的元素非整数,直接转ht编码
/* The set *was* an intset and this value is not integer
* encodable, so dictAdd should always work. */
serverAssert(dictAdd(subject->ptr,sdsdup(value),NULL) == DICT_OK);
return 1;
}
} else {
serverPanic("Unknown set encoding");
}
return 0;
}
ZSet(SortedSet)
是一个可排序的set集合,和java的treeset类似。但sortedset每个元素都带了一个score值和member值,基于score属性对元素进行排序。
- 可排序
- 元素不重复,后添加覆盖前添加
- 查询速度快 使用场景,微信运动的排行榜,福布斯财富排行榜。
所以zet底层数据结构必须满足 键值存储、键必须唯一、可排序这几个需求。那么有以下几个底层数据类型:
- skipList:键值存储,可排序,也可以同时存储score和ele值(member),但是不能根据member找score,除非把跳表当初普通链表一个个遍历查找。满足键值和可排序,但是不满足元素不重复和根据member查score。
- HT(Dict):可以键值存储,并且可以根据key找value。键肯定是唯一的,同一个key存在就覆盖。但是,它不能做排序。它是随机的。
所以。小孩才做选择,大人全都要,redis在实现Zset的时候,两个都结合了。
源码
typedef struct zset {
dict *dict; // Dict指针实现键值存储和唯一
zskiplist *zsl; // skipList指针实现排序
} zset;
robj *createZsetObject(void) {
zset *zs = zmalloc(sizeof(*zs));
robj *o;
//创建Dict
zs->dict = dictCreate(&zsetDictType,NULL);
//创建skipList
zs->zsl = zslCreate();
o = createObject(OBJ_ZSET,zs);
o->encoding = OBJ_ENCODING_SKIPLIST; // 编码写的是skiplist,但是本质是两种结合,奈何编码只能选一个
return o;
}
内存图
如: 存入 zadd d1 10 m1 20 m2 30 m3 40 m4
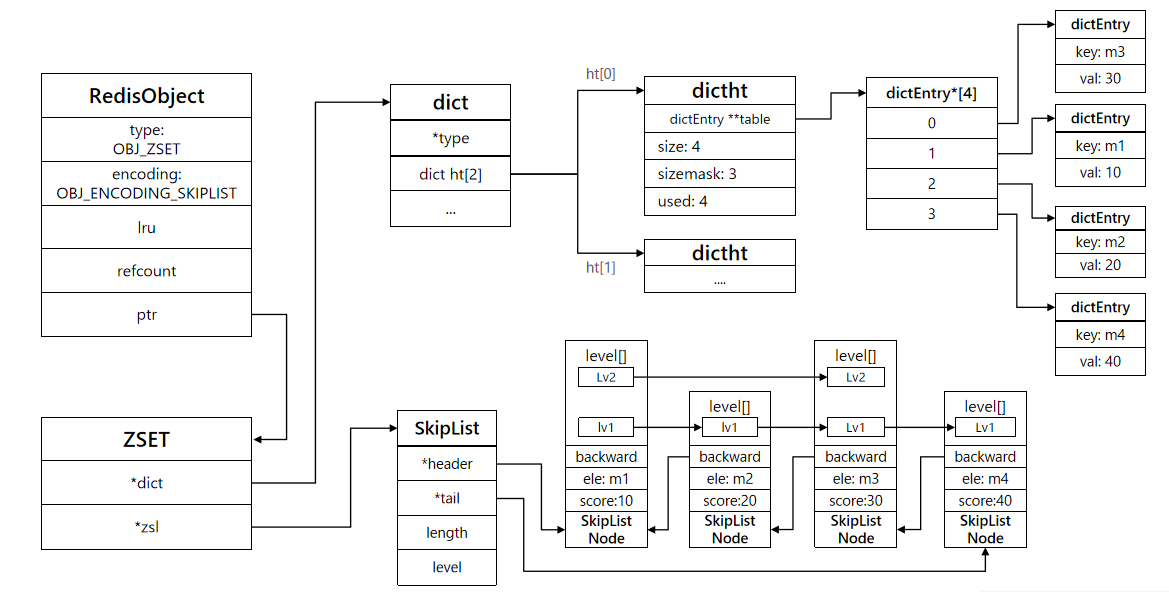
- redisobject的ptr指向了zset,zset又指向了两个,一个是dict,一个是skiplist。
- 其中dict中的entry的key保存了member,value保存了score。所以根据key找value直接通过dict来查找。把key做hash直接找到value。
- 如果要排序,就去skiplist中查找。skiplist中,可以通过score来排序。
但是,整个zset结构非常占用内存,又有dict,又有skiplist。
所以,在数据量不多的时候,dict和skiplist的优势不明显,而且耗能存,所以zset还会采用ziplist结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于
zset_max_ziplist_entries默认 128. - 每个元素都小于
zset_max_ziplist_value字节,默认为64
但是ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
- ziplist是连续内存的,因此score和element是紧挨着一起的两个entry,element在前,score在后。
- score越小越接近队首,越到越接近队尾。
- 至于查找,由于数据小,直接遍历,在数据小的情况下,遍历效率也是高的。
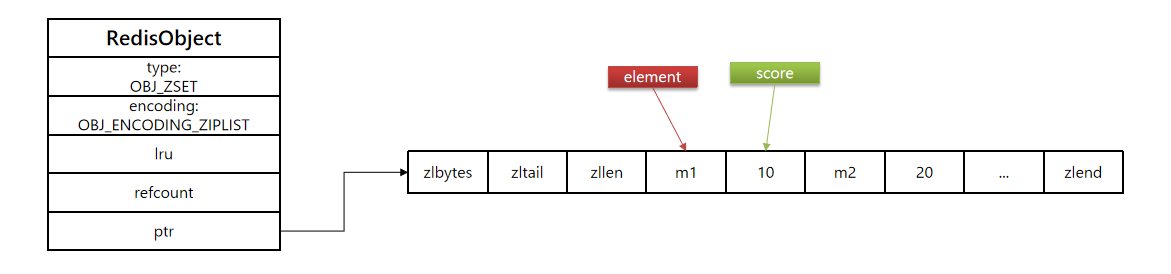
在redis7.0之后,采用了新的数据类型 listpack 。有时间了更新一版本。
Hash
hash类型,也叫散列,它的value是一个无序字典,类似java、go中的hashmap。
hash和zset非常类似,都是需要键值存储、根据键获取值、键必须唯一等等。但是不需要排序了。
所以能否借鉴zset的数据量小的情况下使用ziplist,数据量多的话使用dict呢? 答案是可以的。
底层实现
- hash结构默认采用ziplist,来节省内存,ziplist中相邻的两个entry分别保存field和value。
- 当数据量较大的时候,hash结构会转为ht编码,也就是Dict,触发条件有两个:
- ziplist中的元素数量超过了
hash-max-ziplist-entries默认 512 - ziplist中的任意entry大小超过了
hash-max-ziplist-value默认64
- ziplist中的元素数量超过了
结构图
如当存储量比较小的时候,为ziplist存储
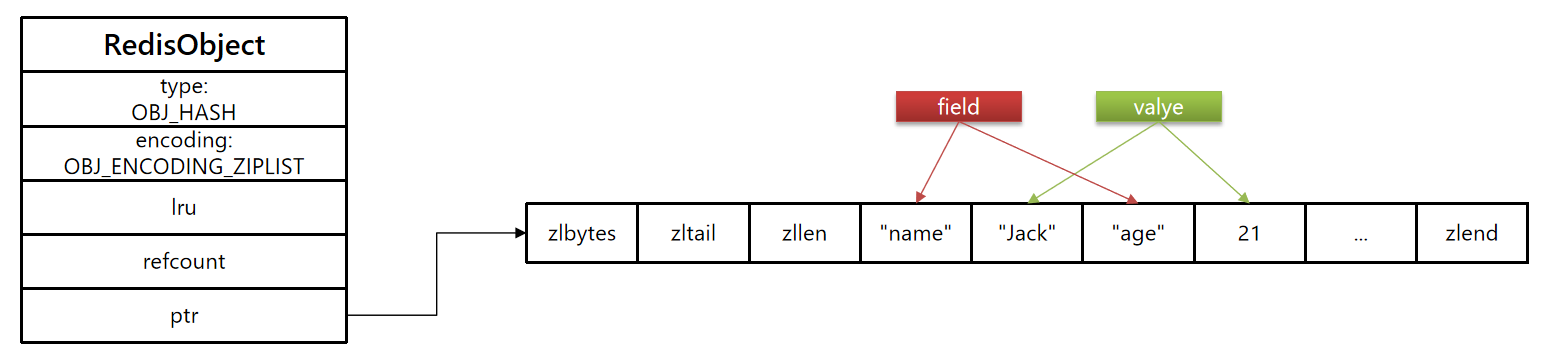
但是一旦数据量大了,或者大小超过了配置,就会转成ht存储。
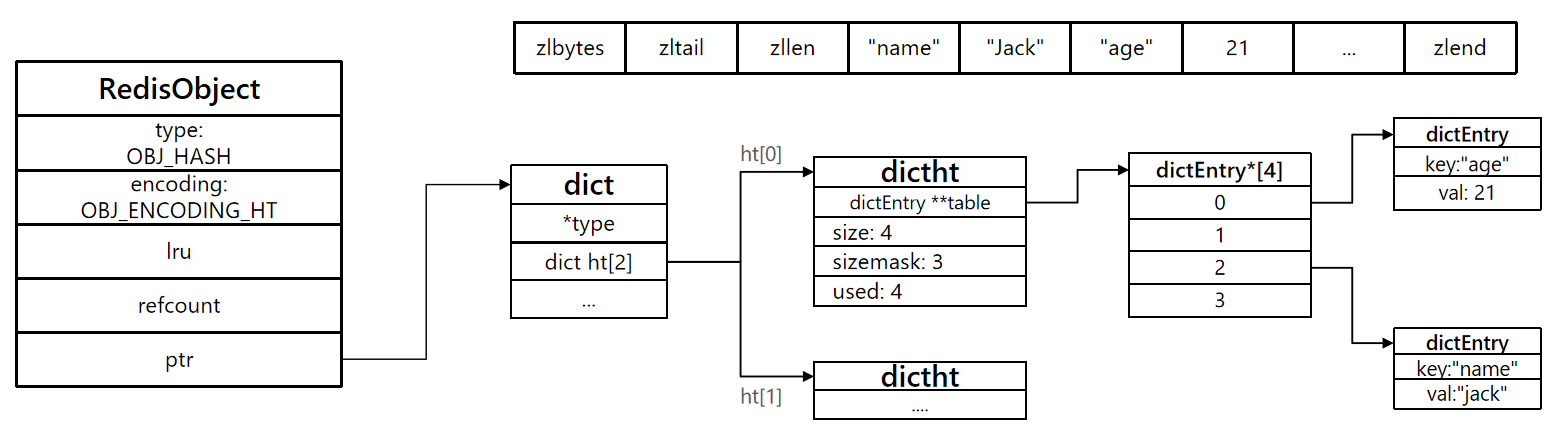
代码片段
void hsetCommand(client *c) {
int i, created = 0;
robj *o;
// 判断hash的key是否存在,不存在则创建一个新的,默认采用ziplist编码
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
hashTypeTryConversion(o,c->argv,2,c->argc-1); // 判断是否需要把ziplist转为dict编码
//遍历每一个field和value,并执行hset命令
for (i = 2; i < c->argc; i += 2)
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
// ....
}
总结
所以,在redis版本7.0以下,五大数据类型底层分别是:
- string:底层为简单动态字符串
数据类型 底层实现 其他 string(字符串) raw(SDS)、embstr、int 存储的sds长度小于44为embstr,存储的字符串为整数且大小在long范围类为int,其余为raw。上限512 list(列表) 采用quicklist 双向链表,每个quicklist都包含了多个ziplist set(集合) intset和HT(Dict) 存储的数据为整数且数量不超过配置时为intset、否则自动转为hashtable(Dict) sortedSet(有序集合) ziplist、skiplist加HT(Dict) 数量和内存不超过配置时使用ziplist(ele在前score在后),否则为dict(查找和唯一)和skiplist(排序)的结合体 hash(哈希表) ziplist、HT(Dict) 数量和内存不超过配置时使用ziplist,否则为dict
当然在后续的7.0版本后,redis把ziplist替换成listpack,从而彻底解决ziplist更新时出现的连锁内存更新问题。后续有时间继续更正。

