
redis到底是单线程还是多线程?
先说答案,分情况而定:
- 如果仅仅是redis的核心业务部分(命令处理),答案是单线程。
- 如果是聊整个Redis,答案是多线程。
因为在redis6.0之后,核心网络模型中引入了多线程,进一步提高对于多核CPU的利用率。
那么,为什么redis的核心业务部分一直遵循着单线程呢?
- 抛开持久化,redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而非执行速度,因此多线程并不会带来巨大的性能提升,你还不如去考虑下网络优化。
- 多线程会导致过多的上下文切换,带来不必要的开销。
- 引入多线程会面临线程安全问题,必然要引入线程锁这样的安全手段,实现复杂度增高,而且性能也会大打折扣。单线程是依次执行,它是线程安全的。
redis网络模型
如果对Linux网络模型不了解的,请异步:Linux的IO模型
所有的web服务流程几乎一致: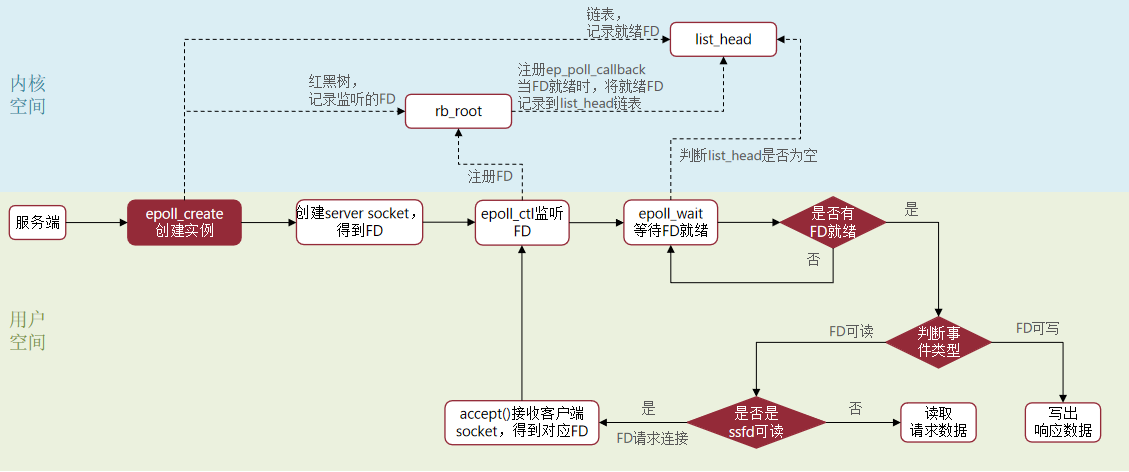
Redis通过IO多路复用来提高网络性能,并且支持各种不同的多路复用实现,并且将这些实现进行封装, 提供了统一的高性能事件库API库。
先看看Redis单线程网络模型的整个流程,直接上源码:
初始化服务流程:
int main(
int argc,
char **argv
) {
// ...
// 初始化服务
initServer();
// ...
// 开始监听事件循环
aeMain(server.el);
// ...
}
void initServer(void) {
// ...
// 内部会调用 aeApiCreate(eventLoop),类似epoll_create
server.el = aeCreateEventLoop(
server.maxclients+CONFIG_FDSET_INCR);
// ...
// 监听TCP端口,创建ServerSocket,并得到FD
listenToPort(server.port,&server.ipfd)
// ...
// 注册 连接处理器,内部会调用 aeApiCreate(&server.ipfd)监听FD
createSocketAcceptHandler(&server.ipfd, acceptTcpHandler)
// 注册 ae_api_poll 前的处理器
aeSetBeforeSleepProc(server.el,beforeSleep);
}
// 数据读处理器
void acceptTcpHandler(...) {
// ...
// 接收socket连接,获取FD
fd = accept(s,sa,len);
// ...
// 创建connection,关联fd
connection *conn = connCreateSocket();
conn.fd = fd;
// ...
// 内部调用aeApiAddEvent(fd,READABLE),
// 监听socket的FD读事件,并绑定读处理器readQueryFromClient
connSetReadHandler(conn, readQueryFromClient);
}
监听时间循环
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
// 循环监听事件
while (!eventLoop->stop) {
aeProcessEvents(
eventLoop,
AE_ALL_EVENTS|
AE_CALL_BEFORE_SLEEP|
AE_CALL_AFTER_SLEEP);
}
}
int aeProcessEvents(
aeEventLoop *eventLoop,
int flags ){
// ... 调用前置处理器 beforeSleep
eventLoop->beforesleep(eventLoop);
// 等待FD就绪,类似epoll_wait
numevents = aeApiPoll(eventLoop, tvp);
for (j = 0; j < numevents; j++) {
// 遍历处理就绪的FD,调用对应的处理器
}
}
redis单线程网络模型的整个流程
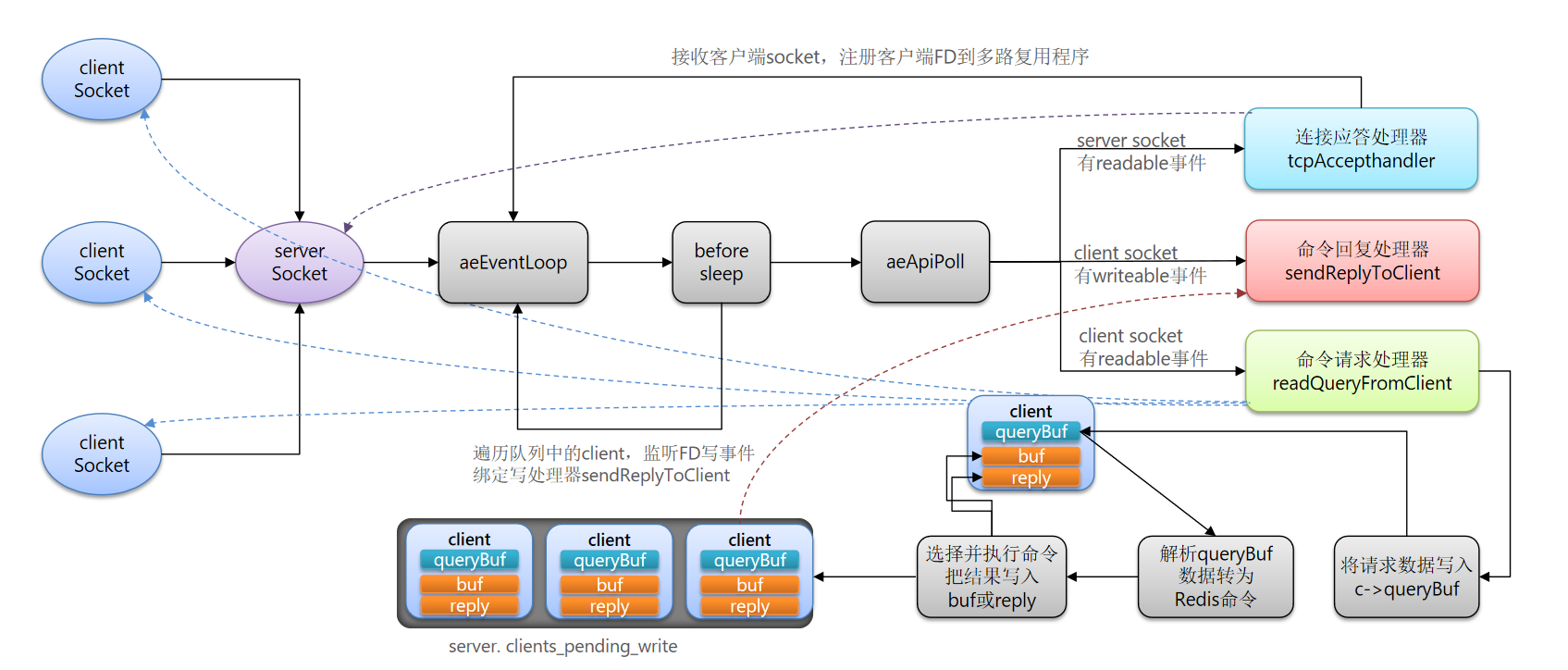
- 最开始有个serverSocket,创建完成后有个FD(file describe 文件描述符),注册到aeEventLoop上,再绑定一个处理器(tcpAcceptHandler),专门来处理serverSocket可读事件,一旦可读,处理器会被调用。
- aeEventLoop创建之后,应该是要调用await等待就绪了?不是,在这之前,先调用before sleep(这个作用后续说),然后再调用aeApiPoll(等同await等待就绪)。
- 等待server socket就绪了,就会调用处理器,代表有readable事件了,什么时候可读呢?那就是当clientSocket链接上来的时候,如果有连接,就会触发server的读事件,一旦触发,就会调用对应的处理器。
- 处理器会接收客户端的请求,然后得到客户端Socket的FD,然后再次注册到aeEventLoop上,所以这个aeEventLoop上注册的FD现在有多个,一个是serverSocket,一个是客户端的clientSocket。这时候再次循环流程,又一次等待,这时候获取到的读事件,可能就有多个了,有可能是server Socket readable,也有可能是 client socket的readable事件。如果是server socket,那就再次循环。
- 如果是client Socket的readable事件,它也有一个处理器,readQueryFromClient(命令请求处理器),它内部做了一些事情,将请求数据写入到queryBuf中,然后解析数据转为Redis命令,然后根据命令去找对应的command的处理函数(命令和处理函数对应关系在一个dict里面),然后执行处理函数之后,把结果写入到客户端的缓冲区,buf或者reply中(取决于缓冲区大小,缓冲区写不下,就写到reply中,这是一个链表,容量无上限),那什么时候写到客户端的socket呢?
- 对应的执行命令结果,先放到客户端的缓冲区,且一起(queryBuf/buf/reply)放到了一个队列(client_pending_write)中去,随着客户端越来越多,那么待写出的客户端也越来越多,它们都排在队列之中。到这里,readQueryFromClient这个函数完成使命,但是,结果还没写出去。
- 此时,beforesleep的作用来了,这个函数就是来写的,它通过迭代器,遍历待写出的client,监听FD写事件,然后绑定写处理器(sendReplyToClient)。此时,clientSocket就获取到了writeable事件,然后命令回复处理器(sendReplyToClient)就会把结果,写到客户端的socket里面。
此时,整个流程都形成闭环了。简而言之:
1:serversocket起来后,注册且监听了事件,当有serversocket的readable事件来了后,丢给了tcpAccethHandler。
2:当有client socket的readable事件来了后,我们丢给了readQueryFromClient的处理器去处理,里面把结果丢给了队列,然后before sleep会写到写处理器里面。
3:clientsocket的writeable事件来了后,发送到客户端的socket里面去。
看起来比较复杂,但是整体简单一点,我们把 aeEventLoop、beforesleep、aeApiPoll都不用管的,它其实就是一个IO多路复用+事件派发。因为就是不端的监听,事件有多种,监听到事件了就派发,派发到不同的处理器。
redis多线程网络模型的整个流程
在redis6.0后引入了多线程,目的是为了提高IO读写效率,因此在解析客户端命令、写响应结果时采用了多线程,核心的命令执行并将结果写到缓冲区、IO多路复用模块依旧是主线程执行的。
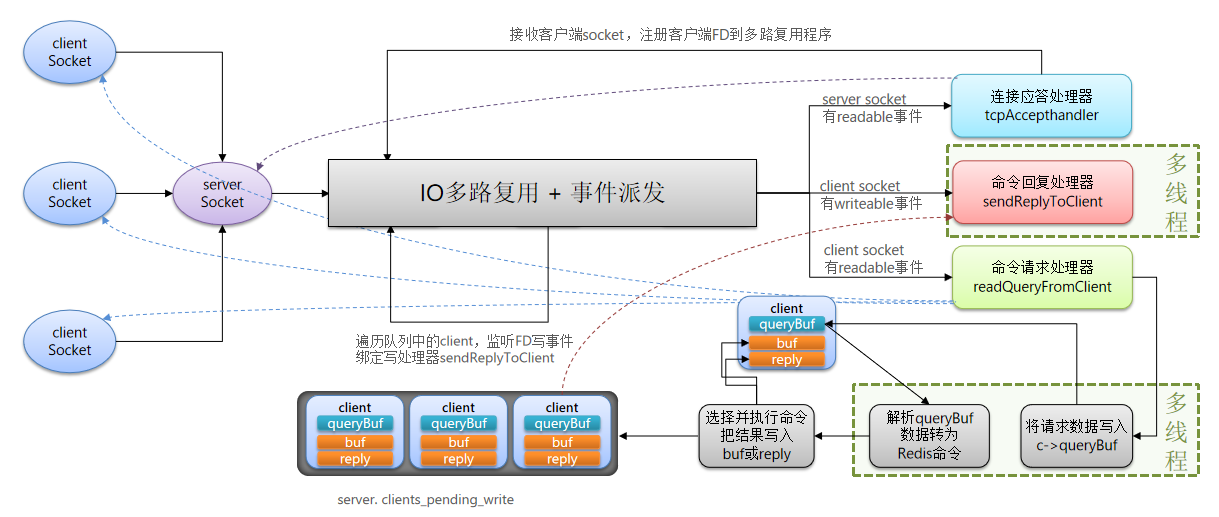
- 客户端socket来了之后,在高并发的情况下,会有无数的请求过来,那client socket 的readable事件会非常多,如果一个个读,单线程下会忙不过来。所以开启多线程,主线程轮询的方式,把有多个不同的客户端来分发给不同的线程,并行的解析请求当中的数据,解析成redis的命令。但是真正找到对应的redis命令的command函数执行的时候,还是有多线程自己去执行,并把执行的结果写入到缓存或者reply中。
- 在写事件的时候,比较耗时,所以在回复client socket的时候,也采用了多线程。
这种情况,虽然单个请求的时间没有减少,但是吞吐量有不少的提升。
所以:redis的核心业务部分(命令处理)是单线程的,但是整个redis架构,有些架构是多线程的,比如解析客户端命令和写响应结果。
redis为什么这么快呢?
主要原因,是redis是内存操作,可以避免频繁的进行写盘操作,大大降低响应时间。次要原因是采用了高性能的多路复用IO模型+事件派发。

