
redis之所以性能强,主要原因是基于内存存储,但内存有限,如同貔貅,只进不出的话,那早晚奔溃。
单节点的内存大小不宜过大,会影响持久化或者主从同步性能。我们可以通过修改配置文件来设置redis的最大内存:
# In short... if you have replicas attached it is suggested that you set a lower
# limit for maxmemory so that there is some free RAM on the system for replica
# output buffers (but this is not needed if the policy is 'noeviction').
# maxmemory <bytes>
maxmemory 1gb
但是设置的话,总归有限制,如果达到上限了,就无法存储更多的数据了。所以,redis提供了两种策略:过期策略和淘汰策略。
过期策略
相信这个大部分业务都有涉及过,就是通过expire命令给redis的key设置TTL:
124.223.47.250_6379:0>set myname milo
124.223.47.250_6379:0>expire myname 5 # 设置成5s过期
124.223.47.250_6379:0>get myname
"milo"
124.223.47.250_6379:0>get myname # 5秒后
null
由上,key的TTL到期后,再次访问为null,说明这个key不存在了,对应的内存也释放了,从而起到内存回收的目的。
但是,这只是使用方,我们要知其所以然,它底层是怎么实现的呢? 由数百万个key,redis是如何知道哪个key是否过期呢? 是不是TTL到期就立即删除了呢?
Redis如何知道key是否过期。
redis本身是一个典型的k-v内存存储数据库,因此所有的key、value都保存在dict结构中,不过在database结构体中,由两个Dict,一个是来记录key-value的,一个是记录key-TTL的。
我们知道redis有0-15总共有16个库,每个库其实都是一个redisDb的结构。如下源码:
typedef struct redisDb {
dict *dict; /* 存放所有key及value(redisObject)的地方,也被称为keyspace*/
dict *expires; /* 存放每一个key及其对应的TTL存活时间,只包含设置了TTL的key*/
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID,0~15 */
long long avg_ttl; /* 记录平均TTL时长 */
unsigned long expires_cursor; /* expire检查时在dict中抽样的索引位置. */
list *defrag_later; /* 等待碎片整理的key列表. */
} redisDb;
看到这个源码,相信就有答案了,是不是有一个expires,记录了key和过期时间,这个就是redis它知道key是否过期了。
再来一个DB架构图吧。
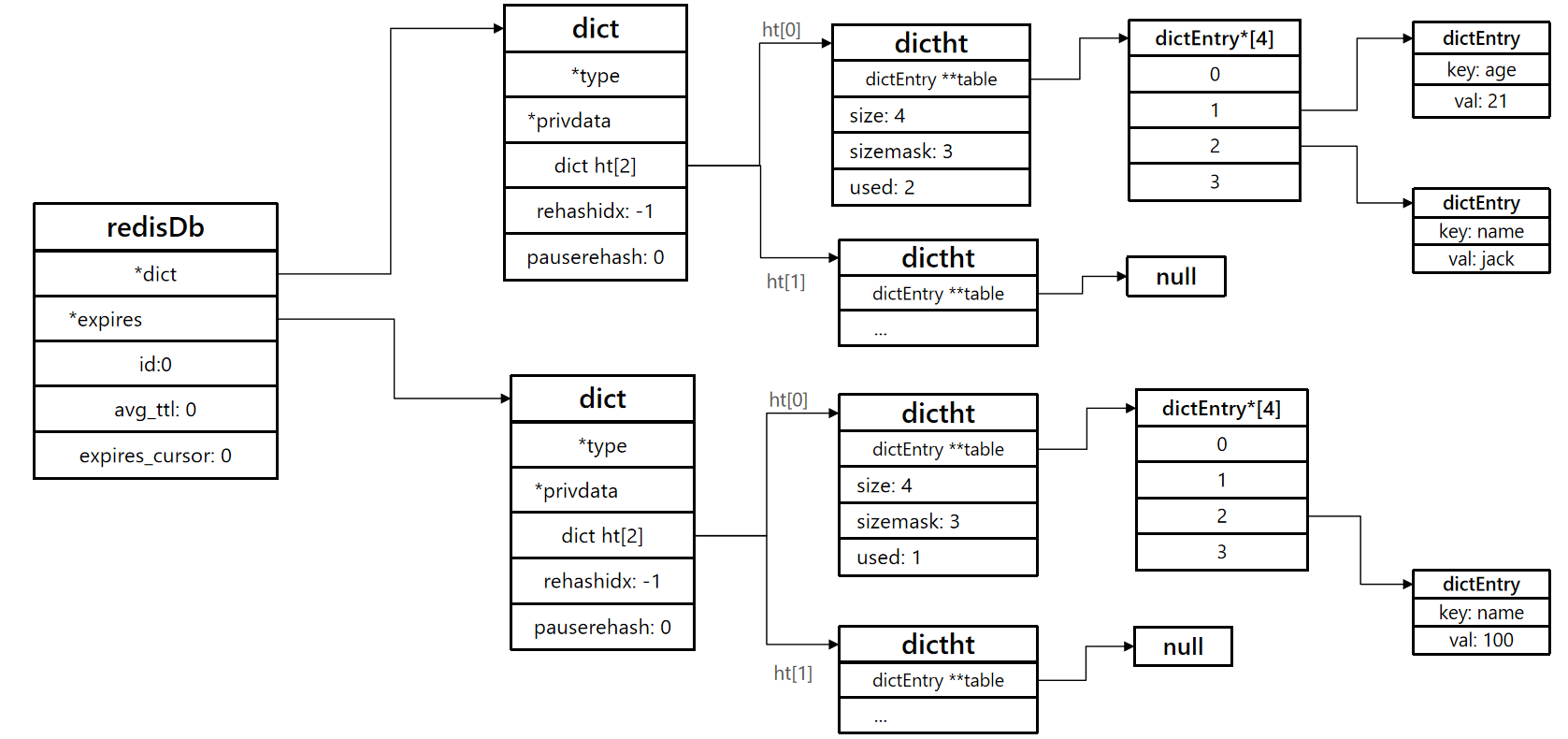
- dict,存储所有键值对的地方,也是keyspace。它就是dict结构,包含了两个hashtable,一个是rehash,为null,一个是真正的数据,里面是一个数组,数组中是一个个entry,对应的键值对的信息。其中key就是key,value为redisObject,取决于你的具体数据类型。
- expires,同样是一个dict,同样有两个hashtable,一个为rehash,一个存真实的数据,但它的entry下面的key,就是key,它的value,存的就是过期时间。
所以:redis如何知道key是否过期:
答案是: 利用两个Dict分别记录key-value和key-ttl对。如何知道是否过期,那就拿key去key-ttl中查,然后判断即可。
Redis知道key过期了,是立即删除吗?
所谓立即删除,是到期了立马删除,那岂不是要给每个设置ttl的key给个监视器,key少还行,key多了,cpu压力大得很,这意义何在?
所以,在实际应用中,采用的是两个策略,一个是惰性删除,一个是周期删除。
过期策略-惰性删除
顾名思义:也就是在访问一个key的时候,检查该key的存活事件,如果已经过期了才执行删除。 访问一个key,就是增删改查。
// 查找一个key执行写操作
robj *lookupKeyWriteWithFlags(redisDb *db, robj *key, int flags) {
// 检查key是否过期
expireIfNeeded(db,key);
return lookupKey(db,key,flags);
}
// 查找一个key执行读操作
robj *lookupKeyReadWithFlags(redisDb *db, robj *key, int flags) {
robj *val;
// 检查key是否过期
if (expireIfNeeded(db,key) == 1) {
// ...略
}
return NULL;
}
int expireIfNeeded(redisDb *db, robj *key) {
// 判断是否过期,如果未过期直接结束并返回0
if (!keyIsExpired(db,key)) return 0;
// ... 略
// 删除过期key
deleteExpiredKeyAndPropagate(db,key);
return 1;
}
这样有个问题,访问的时候删除,但是有一个key,或者有一批key,特别是bigkey过期了,在很长的时间一直没有访问,内存都快没有了,这样,是不是占着茅坑不拉屎?
过期删除-周期删除
为了解决 占着茅坑不拉屎的问题,Redis来了另外一个周期删除,顾名思义:通过一个定时任务,周期性的抽样部分过期的key,然后执行删除,执行周期有两种:
- redis初始化的时候,会设置一个定时任务 serverCron(),按照server.hz的频率来执行过期key清理,模式为slow,执行的时间长,但是频率低。默认10,也就是1s10次,100毫秒执行一次。 当然这个server.hz这个值是可以配置的。
void initServer(void){
// ...
// 创建定时器,关联回调函数serverCron,处理周期取决于server.hz,默认10
aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL)
}
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
// 更新lruclock到当前时间,为后期的LRU和LFU做准备
unsigned int lruclock = getLRUClock();
atomicSet(server.lruclock,lruclock);
// 执行database的数据清理,例如过期key处理
databasesCron();
return 1000/server.hz
}
void databasesCron(void) {
// 尝试清理部分过期key,清理模式默认为SLOW
activeExpireCycle(
ACTIVE_EXPIRE_CYCLE_SLOW);
}
- redis每个事件循环前会调用beforeSleep函数,执行过期key清理,模式为FAST,执行频率高,但是执行时间短,不超过1毫秒。
void beforeSleep(struct aeEventLoop *eventLoop){
// ...
// 尝试清理部分过期key,清理模式默认为FAST
activeExpireCycle(
ACTIVE_EXPIRE_CYCLE_FAST);
}
规则详解:
SLOW模式规则:
执行频率受server.hz影响,默认为10,即每秒执行10次,每个执行周期100ms。
执行清理耗时不超过一次执行周期的25%.默认slow模式耗时不超过25ms
逐个遍历db,逐个遍历db中的bucket(数组的角标),抽取20个key判断是否过期,每次都会记录下进度,在redis的全局变量里面。所以这样一步步,每个db的key都会遍历掉。
如果没达到时间上限(25ms)并且过期key比例大于10%,再进行一次抽样,否则结束。
FAST模式规则(过期key比例小于10%不执行 ):
执行频率受beforeSleep()调用频率影响,但两次FAST模式间隔不低于2ms
执行清理耗时不超过1ms
逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
如果没达到时间上限(1ms)并且过期key比例大于10%,再进行一次抽样,否则结束
所以:过期key的删除策略:
- 惰性清理:每次查找key时判断是否过期,如果过期则删除
- 定期清理:定期抽样部分key,判断是否过期,如果过期则删除。
但是,如果在及其庞大的项目中,哪怕淘汰过期的key也难以满足内存的使用,此时如何处理?
淘汰策略
如上,内存淘汰:当redis内存使用达到设置的阈值的时候,redis主动挑选部分key删除以释放更多内存的流程。但是面临着:
- 什么时候检查内存是否到达了阈值?
- 如何删除?随便删吗?把我热点key删掉了,出问题谁负责?redis开发吗?
内存检查时机
redis会在处理客户端命令的方法,processCommand中尝试做内存淘汰,也就是在这里检查内存够不够,不够我就删,每次都检查。一把梭哈。
当然,也是要配置了maxmemory,如果没有配置,我认为你是土豪,没有内存上限的。
int processCommand(client *c) {
// 如果服务器设置了server.maxmemory属性,并且并未有执行lua脚本,万一你在执行lua脚本,我删除了,你肯定怪我
if (server.maxmemory && !server.lua_timedout) {
// 尝试进行内存淘汰performEvictions
int out_of_memory = (performEvictions() == EVICT_FAIL); // 如果是fail,表示我去清理内存,但是清理内存失败了。一般是内存不够了
// ...
if (out_of_memory && reject_cmd_on_oom) {
rejectCommand(c, shared.oomerr); // 拒绝提交,内存都不够了,怎么存。
return C_OK;
}
// ....
}
}
performEvictions中去判断内存大小,且判断是否要删除以及做删除的动作,返回值有如下:
- EVICT_OK - 内存正常或者现在无法执行内存淘汰
- EVICT_RUNNING - 内存超出限制,但内存淘汰仍在处理中
- EVICT_FAIL - 内存超出限制,没有什么可以淘汰的
所以,内存检查是在每一个命令执行之前,要去做内存的检查,根据配置信息,如果达到了阈值则去做内存淘汰。
如何淘汰?淘汰谁
在redis中,支持8种不同的策略来选择要删除的key,当然,我也可以修改这个策略:
# volatile-lru -> Evict using approximated LRU, only keys with an expire set.
# allkeys-lru -> Evict any key using approximated LRU.
# volatile-lfu -> Evict using approximated LFU, only keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
# volatile-random -> Remove a random key having an expire set.
# allkeys-random -> Remove a random key, any key.
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# noeviction -> Don't evict anything, just return an error on write operations.
# The default is:
#
# maxmemory-policy noeviction
这八个策略解释为:
noeviction:
不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。
volatile-ttl:
对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰,也就是你都快不行了,我干脆送你一程吧。
allkeys-random:
对全体key ,随机进行淘汰。也就是直接从db->dict中随机挑选,点兵点将,点到谁谁淘汰,一般不会使用这个,这个就太任性了。
volatile-random:
对设置了TTL的key ,随机进行淘汰。也就是从db->expires中随机挑选。
allkeys-lru:
对全体key,基于LRU算法进行淘汰
volatile-lru:
对设置了TTL的key,基于LRU算法进行淘汰
allkeys-lfu:
对全体key,基于LFU算法进行淘汰
volatile-lfu:
对设置了TTL的key,基于LFI算法进行淘汰
当然,比较容易混淆的是这两个:
- LRU(Least Recently Used),最少最近使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
- LFU(Least Frequently Used),最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。这个可以理解为 最近最少使用。
这些,随机的好理解,点兵点将,设置了ttl的也好理解,直接查。 但是最少最近,和最少频率使用,如何计算呢?
如何计算最近、最少?
我们在redisObject中,有一个lru,好像一直没说...
typedef struct redisObject {
unsigned type:4; // 对象类型
unsigned encoding:4; // 编码方式
unsigned lru:LRU_BITS; // 配置的策略不一样,记录的信息也不一样。
// LRU:以秒为单位记录最近一次访问时间,长度24bit
// LFU:记录频率,高16位以分钟为单位记录最近一次访问时间,低8位记录逻辑访问次数,总共为256,但是一个key怎么可能才访问256?所以是逻辑访问。
int refcount; // 引用计数,计数为0则可以回收
void *ptr; // 数据指针,指向真实数据
} robj;
其中LFU的访问次数之所以叫做逻辑访问次数,是因为并不是每次key被访问都计数,而是通过运算:
- 生成0~1之间的随机数R
- 计算 (旧次数 * lfu_log_factor + 1),记录为P
- 如果 R < P ,则计数器 + 1,且最大不超过255。如果只是到这里,那有bug,比如这个key前一周就达到了255,后面好几年都不访问了,那也不淘汰?
- 访问次数会随时间衰减,距离上一次访问时间每隔(高16位记录了最近访问一次时间-当前时间)/lfu_decay_time 分钟,计数器 -1 。所以这里就解决了好久不访问的bug。
也就是是一个概率值,但也可以反应访问次数,访问越高,这个值越大。
再看看performEvictions执行流程
源码太长,对C不熟。
看流程图:
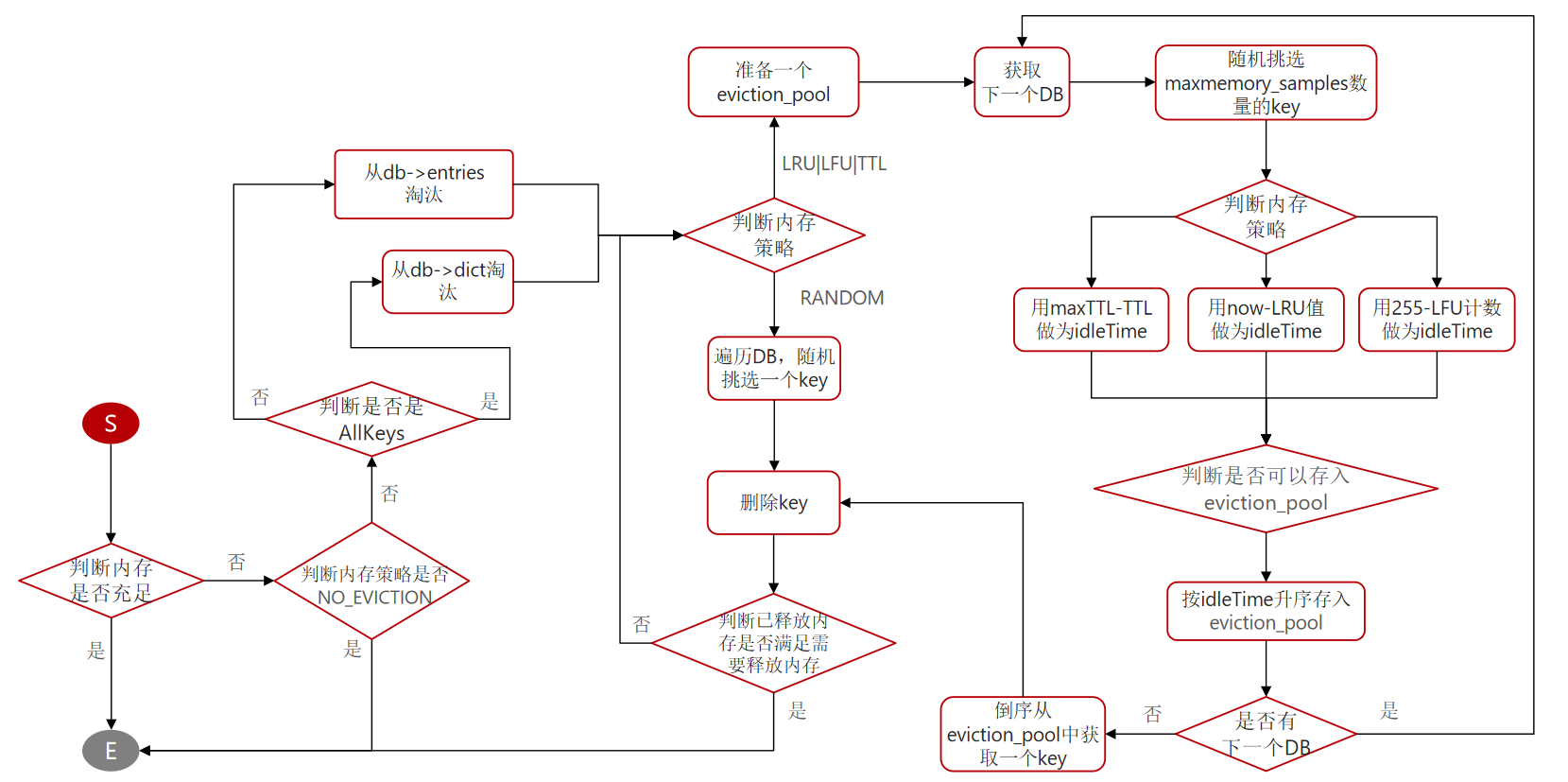
- 一上来,判断内存是否充足,如果充足,直接返回EVICT_OK,结束。
if (getMaxmemoryState(&mem_reported,NULL,&mem_tofree,NULL) == C_OK)
return EVICT_OK;
- 判断内存策略是否是NO_EVICTION,如果是,返回。
if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION)
return EVICT_FAIL; /* We need to free memory, but policy forbids. */
- 判断你是从所有key淘汰,还是从过期key淘汰,走不同的分支。
if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) ||
server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL)
{
/* We don't want to make local-db choices when expiring keys,
* so to start populate the eviction pool sampling keys from
* every DB. */
// ...
}
/* volatile-random and allkeys-random policy */
else if (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM ||
server.maxmemory_policy == MAXMEMORY_VOLATILE_RANDOM)
{
/* When evicting a random key, we try to evict a key for
* each DB, so we use the static 'next_db' variable to
* incrementally visit all DBs. */
// ...
}
- 在判断内存策略,是否随机,如果是随机,直接随便挑一个删除,然后再判断释放策略考虑继续删或者结束本次。
- 如果非随机,那就是LRU|LFU|TTL,那就去找一个eviction_pool ,然后去数据库里面随机挑一些样本,把样本放到池子里面再去比较,看看谁快到期了等等,然后放到池子里面。
if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) || server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) { struct evictionPoolEntry *pool = EvictionPoolLRU; // todo something } - 随机挑选多少个呢? 通过
maxmemory_samples中的个数。 - 根据判断内存的策略,然后分别计算出一个固定的字段,比如idleTime,统一状态,计算idle。
if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) {
idle = estimateObjectIdleTime(o);
} else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
idle = 255-LFUDecrAndReturn(o);
} else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) {
idle = ULLONG_MAX - (long)dictGetVal(de);
} else {
serverPanic("Unknown eviction policy in evictionPoolPopulate()");
}
- 判断是否可以进eviction_pool。
- 再判断是否还有下一个DB,如果有,继续循环找。所以,一般情况下使用0号db吧。
- 如果没有了,则倒序从pool中获取一个key,然后删除。因为越大的在后面。
- 删掉后再看看内存还够不够。不够继续来吧,够的话结束。

