
本文讲解下redis的热门问题,以及解决方案。
缓存穿透
缓存穿透指的是客户端请求的数据,在缓存中和数据库中都不存在,这样的缓存永远不会生效,这些请求直接打到数据库来了。
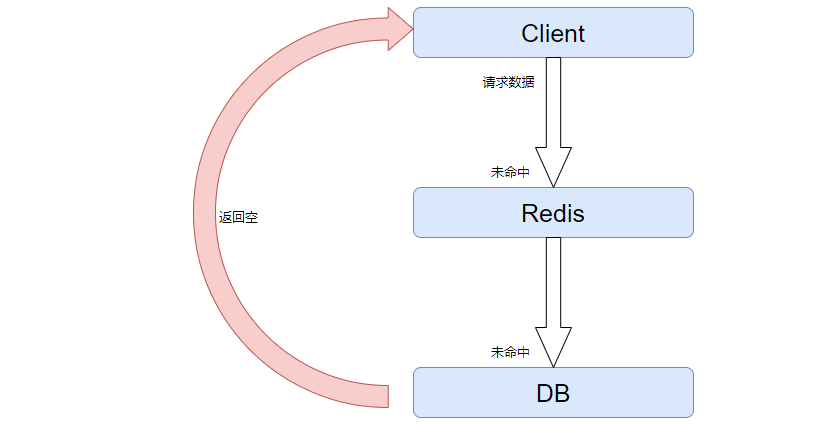
由此可见,redis和db都不存在数据,会返回空。这样的数据经过客户端请求,会直接打到数据库来,如果被不法分子知道这个bug,则多起几个线程频繁请求,这样所有的请求都会打到数据库,数据库一下就打挂了。
目前业内有两种常见的方案,一个是缓存空对象,一个是布隆过滤器。
缓存空对象
这是一个简单暴力的解决方案,本质就是缓存一个空对象到缓存中。
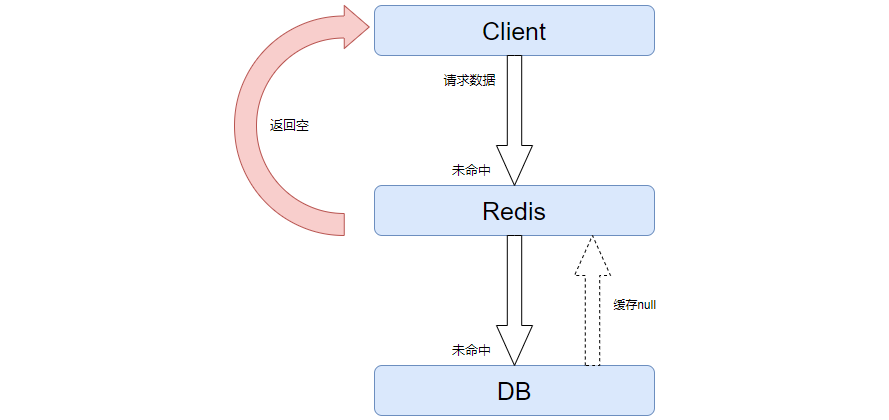
当没有数据的时候,缓存一个null进入缓存,后续直接返回null出去。这样就不需要进入到库来查询了。
这样的优点,就是简单,维护方便,缺点也有,不过都可以规避:
- 额外的内存消耗,查询不到就缓存,后续随着业务扩大时间推移,会缓存很多垃圾数据。但是可以经过设置缓存的TTL进行解决,由redis自身的存储缓存淘汰机制进行维护。
- 可能造成短期的不一致,比如缓存的id最开始查询不到,缓存为空,后续有值了,落库了,但是还未到缓存,此时会造成不一致。但是也可以通过设置TTL时间,以及手动在落库之后再次维护缓存来得到解决。
总而来说,这是一个不错的方案,目前大部分的企业也是采用的这个方案,及时缓存空对象+设置TTL+手动维护缓存的方案。
布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
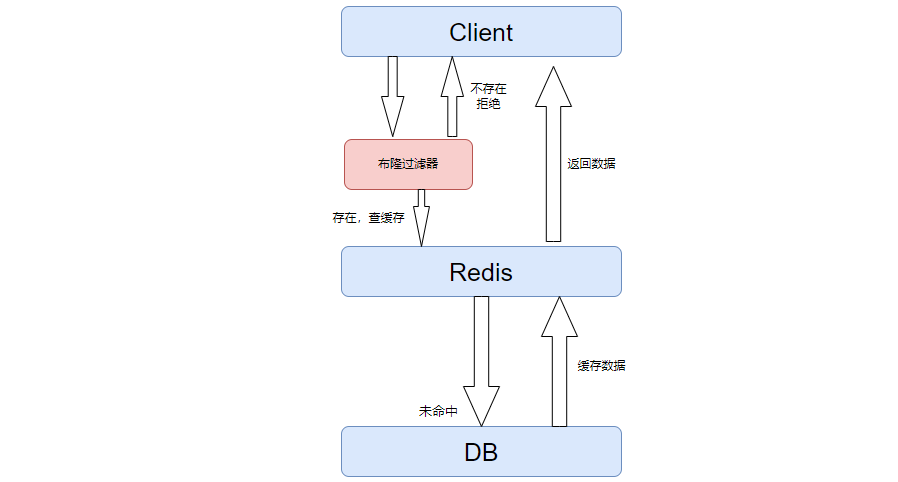
布隆过滤器是一个算法,一个有很多bit位的二维数组,把数据经过hash运算得到的hash值,标记到对应的数组中,把value置为1,表示缓存中有值。数据过来后,先来布隆过滤器中查看是否有缓存过,如果有则进入缓存,如果没有直接拒绝了。当然有数据的时候,需要手动的更新布隆过滤器。
一般来说,我们都不会删除布隆过滤器中的数据,因为删除比较困难,这就导致了里面会有一些不准确的数据,也就是布隆过滤器告诉你没有缓存,那么就一定没有缓存,如果告诉你有缓存的数据,此时不一定有缓存的数据。
关于布隆过滤器,可以移步布隆(Bloom Filter)过滤器——全面讲解 本文不展开了。
布隆过滤器的优点,就是内存占用较少,没有多余的key,但是缺点就是实现比较复杂,需要多一层中间件,且存在误判的可能性,最终还是会造成穿透。
缓存雪崩
听名字就知道,肯定是发生了严重的事故了。一直觉得这个名字命名的特别的合适,言简意赅。
缓存雪崩,指的是同一时段大量的缓存key同时失效,几万或者几十万的key或者redis服务器宕机了,导致大量请求都到达了数据库,带来数据库的巨大压力。
所以,造成这方面的原因,一个是同时失效,一个是服务可靠性。分情况而定。
同时失效
解决这个,我们可以给不同的key的TTL添加随机值,防止同时失效。特别是在预热数据或者是批量导入数据的时候,万万不能给一个固定值,很容易造成雪崩现象,我们可以在TTL后面,跟一个随机数,分散过期时间。
这个比较简单,几乎没有什么实现的成本,强烈建议加一个随机数。
服务可靠性
redis宕机导致的,这个问题比较严重,我们的前提肯定是避免宕机:
- 提高redis集群提高服务的可用性,具体的可移步 redis分布式缓存 ,里面详细的介绍了各种分布式架构,提高服务的可用性。
- 给缓存业务添加降级限流策略,比如出现无法抗拒的事故,某个机房或者某个城市的机房挂了,整个redis集群都完蛋了。这样我们可以做业务失败处理,而不是把请求压到服务器上面去,这样牺牲部分的业务,但是保证的整体服务的健康。
- 给业务添加多级缓存,不单单添加是redis缓存,可以nginx、cdn等等其他的缓存同时添加。可有效的避免雪崩了。
缓存击穿
如果说缓存雪崩,是由于大量的key同时过期导致的后果,那么缓存击穿,就是部分的key失效导致的后果。
缓存击穿问题,也被成为热点key问题,就是一个被高并发访问并且缓存重建业务复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
比如说微博中的某个大V离婚了,但是突然ta的缓存数据突然失效了,而且ta的数据重建比较麻烦,可能要经过大量的运算才能得到。此时突然几百上千万的粉丝过来访问,全部打到数据库了,给数据库造成巨大的冲击。
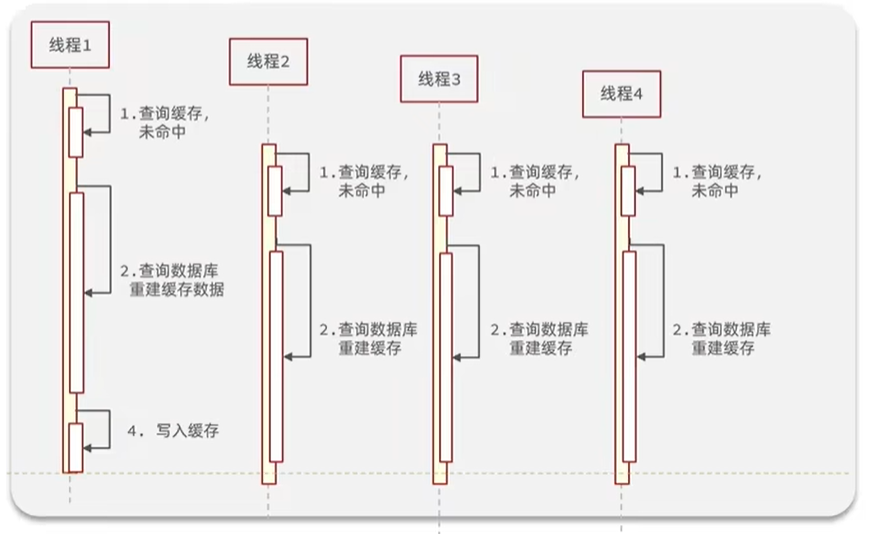
如上图,突然间很多并发访问,但是第二步缓存数据重建比较复杂,在缓存写入未完成之前,全部查询数据库了。
我们一般有几种解决访问:
互斥锁
不是有很多线程并发过来重建数据么,我们可以利用锁的方式,只让一个线程创建就好了,其余人搁那等着这个线程创建好数据吧。

- 线程1过来访问,未命中缓存,此时先获取互斥锁,然后经过查询数据库重建缓存数据,最后写入缓存后,再释放锁。
- 线程2也过来访问了,如果未命中缓存,也会先获取互斥锁,但是由于线程1还未释放锁,所以肯定是获取失败。此时程序阻塞,会一直休眠再重试查询缓存、获取锁等等,一直到线程1释放锁后,此时肯定会命中缓存。
该方案的问题,就是会阻塞等待,比如热点key实现,一千个线程过来了,其实只有一个线程在构建缓存数据,其余的所有线程都在等待阻塞,如果构建的时间比较久的话,那么在这一段的时间中涌入的所有线程,全部只能等待,这样的性能是比较差的。
逻辑过期
顾名思义,逻辑过期,也就是永不过期,比如微博,那些头部大V的数据TTL全部设置成-1,这样缓存就不会失效了。那么不设置TTL,那怎么知道这条数据是否过期了呢? 其实我们可以在缓存数据中的value再加一个expire,这并不是ttl,而是一个逻辑的过期时间。
key:user:wuyuetian value:{name:"wuyuetian",message:"略略略略",expire:162832532332} 类似这样的。
具体的业务操作流程如下:
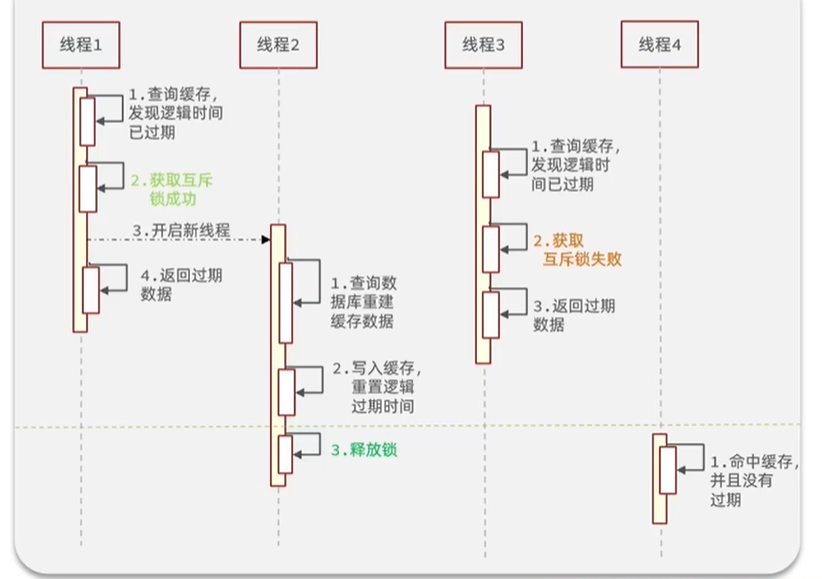
- 线程1过来,查询缓存后发现缓存过期了,它先获取互斥锁,成功后此时它立马开启一个新的线程2,但自己返回过期的旧数据。
- 线程2只是用于重建缓存数据,然后写入到缓存里面,再次重置过期时间后,进行释放锁。
- 线程3也是过来查询缓存,也发现时间过期了,但是准备重建的时候发现获取互斥锁失败了,说明有人(线程1)再进行重建数据了,此时它不管,直接过期的数据。
- 线程4是在线程2重建数据之后过来的线程,命中缓存后发现没有过期,那么就返回没有过期的数据出去。
总结
击穿问题,我们上面讨论了两种方案,这两种方案都有什么优缺点呢?
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | 没有额外的内存消耗,保证一致性,实现简单 | 线程需要等待,性能受影响,可能有死锁问题 |
| 逻辑过期 | 线程无序等待,性能良好 | 不保证一致性,有额外的内存开销,实现较为复杂 |
这就明显涉及了CAP理论了,在分布式下,可用性和一致性是无法得到同时满足的。 互斥锁虽然保证了一致性,但是性能有很大下降,特别是死锁下,可能不可用。但逻辑过期呢,虽然程序无序等待,但是重建需要时间,无法保证一致性了,具体如何取舍,看各位看官的业务了。
全局唯一ID
我们有一些业务场景,是不能使用数据自增ID的,比如用户id,这样id的规律性太明显了,而且受到单表数量的限制。当然你也不能使用uuid这种没有任何规律的id,我们一般使用分布式系统下的唯一id,需要满足如下的特征:
- 全局唯一性
- 高可用,你作为id生成器,不能人家找你你挂了
- 高性能,不仅仅正确的生成id,也需要保证生成id的速度足够快,不能生成一个id需要几秒钟。
- 提增性,需要一个单调特性,就是不断变化的,而且是递增的,在mysql中整理过,索引的叶子节点,也是递增的,有利于创建索引。
- 安全性,数据库的自增id,是快但是不安全,因为很容易让其他人猜测到你的其他id。
redis自增
那,我们如何使用redis的特性,来进行生成全局唯一ID,满足如上特性呢?
我们可以使用redis自增的特性来处理,因为无论多少人来访问redis,它都是自增的,不存在每个自增不一样,而且redis有很多分布式架构来保证高可用,而且性能比mysql不知道好了多少。但安全性,不能这么递增的玩,不然和mysql是一样的。我们可以拼接一点其他的信息:

- 符号位,0,1bit,永远为0
- 时间戳,31bit,以s为单位,最多可以使用69年
- 序列号,32bit,也就是1s中生成的多个id,可以使用序列号来区别,支持每秒产生2^32个不同的ID,足够使用了。使用redis的自增来处理。
go代码如下:
var redisClient *redis.Client
func init() {
redisClient = initRedis()
}
func RedisWorker(keyPrefix string) (int64, error) {
timestamp := time.Now().Unix()
// 生成序列号
year, monty, day := time.Now().Date()
nowDateStr := fmt.Sprintf("%d-%02d-%02d", year, monty, day)
// 因为是递增的,最好是按照每个业务的每天进行递增而不是全部递增
incrKey := fmt.Sprintf("%s:%s:%s", "icr:", keyPrefix, nowDateStr)
incrVal, err := operateIncr(context.Background(), incrKey)
if err != nil {
return -1, err
}
return timestamp<<32 | incrVal, nil
}
func operateIncr(ctx context.Context, incrKey string) (int64, error) {
return redisClient.Incr(ctx, incrKey).Result()
}
func initRedis() *redis.Client {
rClint := redis.NewClient(&redis.Options{
Addr: "", // Redis服务器地址和端口
Password: "", // Redis服务器密码(如果有的话)
DB: 0, // 使用的数据库编号,默认为0
})
return rClint
}
snowflake算法
很知名的一个算法,叫做雪花算法,和redis类似,只不过自增是当前机器的自增,需要内部维护的。
数据库自增
不太划算,需要单独维护一张表作为自增的效果,redis自增的数据库表,对mysql的消耗大。

