
如同学习java,要了解JVM一样,不深入看看GMP实现原理,又何尝学好golang呢?
我们知道go语言处理并发能力很强,但是为什么强呢?较比于其他语言,强在哪里?协程又是一个什么概念呢?如何调度呢?等等问题,我们在本文一一讲解。本文学习-知乎:“小徐先生编程世界”。把底层的GMP模型弄懂了,后面再学习go语言,才会得心应手。
概念回顾
用户空间和内核空间
操作系统会把用户空间和内核空间进行分离的。进程的寻找空间也会划分为:内核空间和用户空间两种。寻址空间:我们内核和用户应用,都没办法直接访问实际的内存,而是先给他们划分一片虚拟的内存,通过虚拟的内容来映射到物理内存。所以访问虚拟的内存的时候,就需要一个虚拟的地址了,这个虚拟的地址就是一个无符号的整数,从0开始,最大值取决于CPU地址总线和内存带宽,比如一个32位的系统,它的带宽就是32,所以他的地址最大值就是2^32,也就是寻址的范围,就是从0到2^32这个空间,这个空间就是寻址空间,而内存地址每一个值,都是一个存储单元,也就是一个字节byte。2^32字节=4GB,也就是一个32位系统,它最大的内存限制也就是4GB。
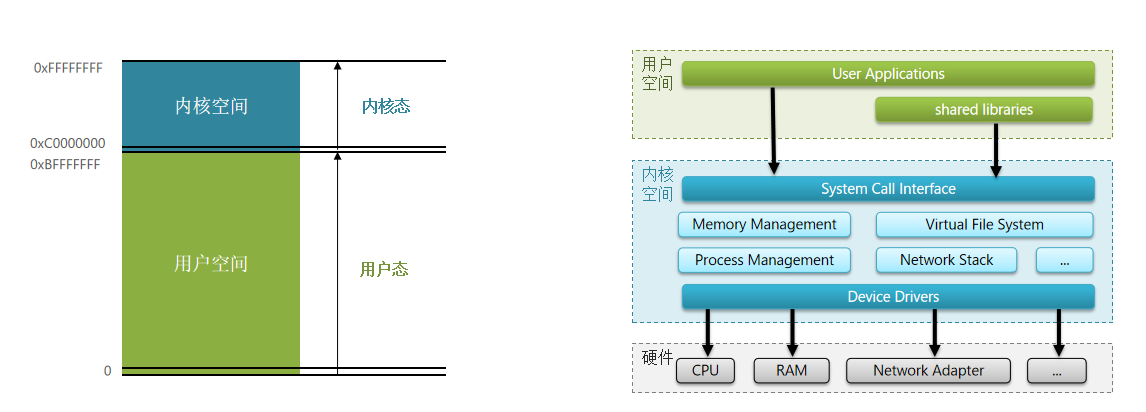
- 内核空间和用户空间的总集代表整个内存的4GB空间,从0开始到0xFFFFFFFF(一起4GB),其中0-0xBFFFFFFF(3GB)成为用户空间,称为用户态。高位的0xC0000000-0xFFFFFFFF(1GB)划分成内核空间,称为内核态。
- 一般来说,用户的应用,都是运行在用户空间,内核的运行在内核空间。
- cpu有些命名是比较机密,一旦运行可能导致灾难,在Linux系统有两种命令(Ring0和Ring3),Ring0等级最高,可以调用一切系统资源,所以只能在内核空间上执行。Ring3为受限制的命令,不能直接调用系统资源,只能通过内核提供的接口来访问。
线程和协程
线程
我们说的线程,指的是运行在内核级别线程,它是操作系统最小调度单元:
- 创建、消耗、调用都是操作系统内核态完成,CPU需要完成用户态和内核态之间的切换。
- 在内核运行调度,在多核CPU下,可以充分利用,实现并行。
协程
协程和线程不一样,协程是线程的子集,必须要建立在线程之上,而且是运行在用户态之中。可能更加是一个逻辑上面的概念,在物理上面还是操作线程。只不过一个线程可以有多个协程,如: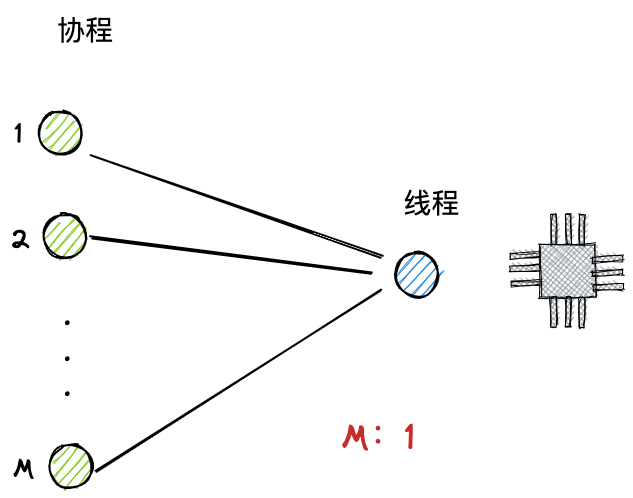
- 线程和协程存在映射关系,一个线程可以对应多个协程。
- 协程依附于线程而生,是用户态基于特殊的操作,划分成更细的粒度叫做协程,但是本质还是依附线程。
- 既然基于用户态,协程的创建、销毁、调度都是在用户态完成,对内核透明的,所以更轻。
- 很多用户态协程属于一个内核态线程,所以协程无法并行,只能并发。如果一个协程执行时间长,可能会阻塞从属于同一线程的所有协程无法执行,会陷入到线程级别的阻塞。因为内核态完全不知道还有协程这个东西。这也是协程的缺陷。
Goroutine
我们刚刚说了,协程是基于线程的,强依赖的,一个线程可能又有很多个协程,这样协程与协程、线程与线程之间的调度不处理好的话,会导致线程阻塞。而Goroutine,就是已经过Golang优化后的特色的一个改良版协程,如下图:
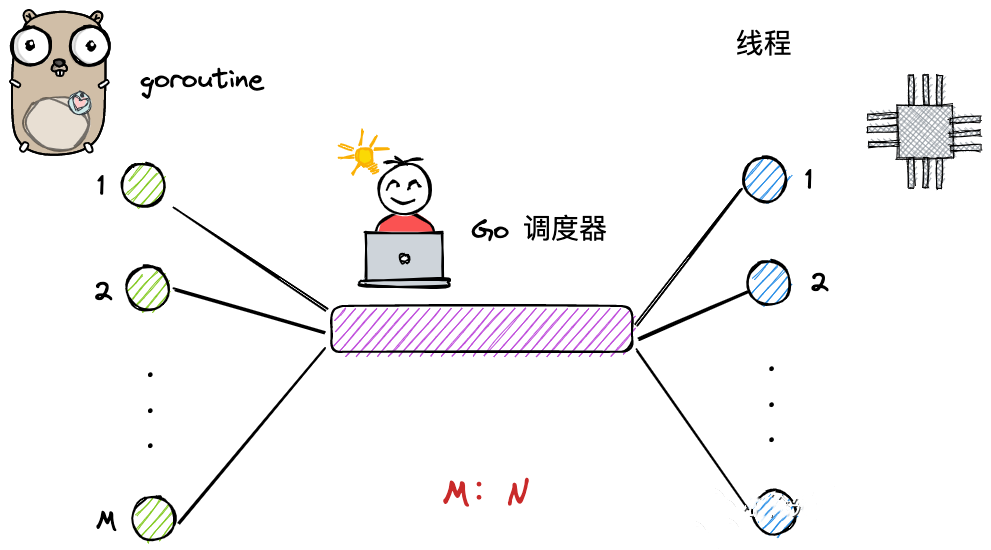
上图明显看出,协程经过Go调度器之后,会动态的和线程之间进行绑定和调度,简而言之就是如果一个线程下很多协程的话,会把某个协程分配到其他空闲的线程,而不是阻塞。
- 通过中间件Go调度器,协程和线程存在映射关系,为多对多。M:N。也就是一个协程可能由不同线程执行,一个线程也可以执行多个协程。
- 同样,还是协程,创建、销毁、调度都是在用户态视角下完成,无需内核态,很轻便。
- 相比于上图,通过Go调度器,一个协程可以利用多个线程,从而实现并行操作。
- 通过调度器的斡旋,协程和线程之间会动态绑定和灵活调动。
- Goroutine之间的栈,它空间大小是可以动态扩缩容的,不会存在空间上的浪费,相比之下,线程就会浪费,因为每次给你分配一个固定大小,就是4M,可能在大部分下是浪费的,在极端下又不够用。
好,概念回顾玩了,我们来做一个对比:
| 模型 | 弱依赖内核 | 可并行 | 可应对阻塞 | 栈可动态扩缩 |
|---|---|---|---|---|
| 线程 | × | √ | √ | × |
| 协程 | √ | × | × | × |
| Goroutine | √ | √ | √ | √ |
王婆卖瓜,自卖自夸,通过对比,明显感觉Goroutine是极为优秀的存在,博采众长之物。
GMP模型
GMP是goalng的线程模型,包含三个概念:内核线程(M),goroutine(G),G的上下文环境(P),其实我们上面多多少少都涉及了一点。
- G:goroutine协程,基于协程建立的用户态线程
- M:machine,它直接关联一个os内核线程,用于执行G,非常珍贵的一个资源。
- P:processor处理器,P里面一般会存当前goroutine运行的上下文环境(函数指针,堆栈地址及地址边界),P会对自己管理的goroutine队列做一些调度。G和M的承上启下的作用。
下面我们拆分单个,逐步讲解。
G
G就是goroutine协程,基于协程建立的用户态线程,经过优化改良后的协程。
它有自己的运行态、状态、以及执行的任务函数go func() test{}()这样就启动了一个协程。
G需要绑定到P才能执行,如果想象go是一个微观的操作系统的话,在G的视角中,P就是它的CPU。
P
processor:中央处理器,也可以理解为调度器,它的功能就是把可运行的Goroutine分配到工作线程上去
也就是协程和线程,是通过P来进行承上启下的作用,实现了g和m之间的动态有机结合。
如果把go比作操作系统的话,对于G而言,P是CPU,G只有P调度才得以执行。对于M而言,P是执行代理。
P的数量决定了G最大并行数量,可由GOMAXPROCS进行设定,不过超过CPU核数时没有意义,一般都是默认自行处理。
M
machine,就是关联了一个内核线程,真正执行的地方。M不直接执行P,而是先和P绑定,由其实现代理。
全局模型
这样有点虚是吧,来个图吧。
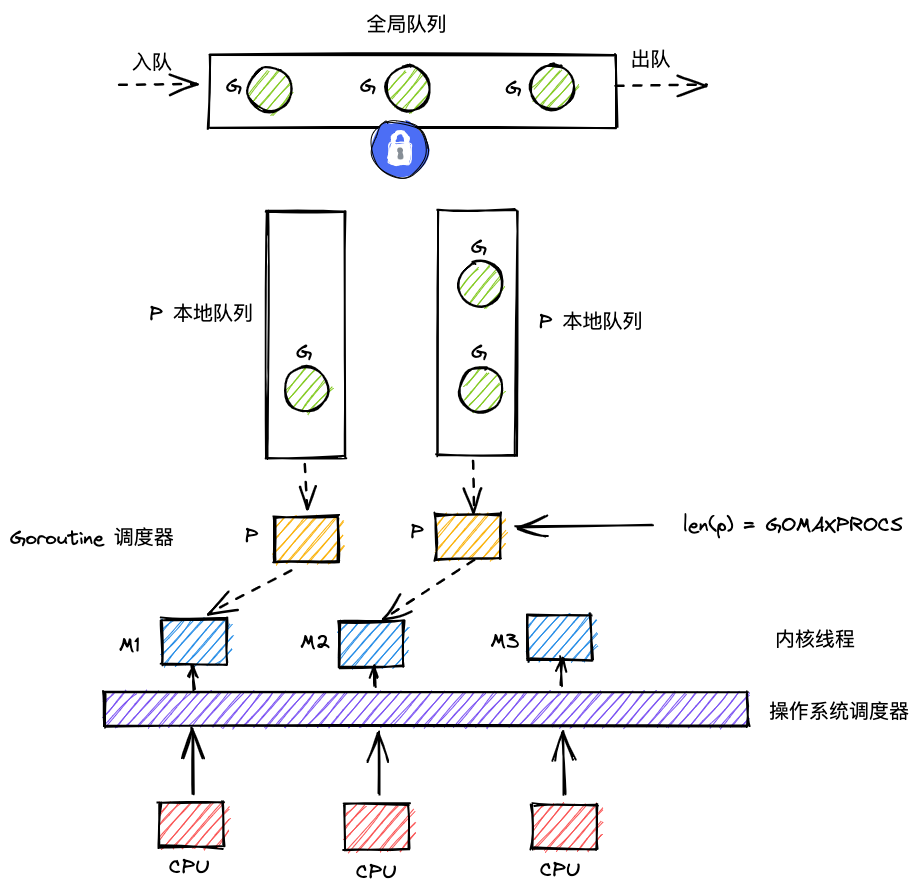
自下而上,就是从内核到用户态的一个平面图。
- 在内核下,CPU通过操作系统单个调度的最小单元,就是线程。
- 线程在Golang中,就是一个个M,然后把一个个的M和P进行绑定。但是数量上面并非完全一样,而且不是一个完全绑定的状态,可以自行解绑,再绑定的状态。
- 全局有多个M和多个P,但同事并行的G的最大数量等于P的数量。
- 上层为用户态,G存在于用户态。
- G的存放队列有三类:P的本地队列、全局队列和wait队列(就是io阻塞就绪态的goroutine队列)
- 调度器P执行Goroutine的时候,会优先从本地队列中获取本身私有的Goroutine进行执行,这样好处是更少的获取临界资源的操作,接近于无锁化,因为从全队列中获取,需要加锁,防止其它调度器同时获取。
- 如果某个P发现自己没有可运行的Goroutine的话,它会从全局队列中获取可执行的goroutine,这样就需要加锁了。
- 如果某个P发现自己的本地队列和全局队列都没有可执行的Goroutine的话,会有一个
work-stealing机制,也就是从其他P的本地队列偷取一半的G补充到自身的本地队列。所以哪怕是P的本地队列,也没法做到绝对意义上的并发安全,因为其他的P也会来你家获取G。但是这个频率还是很低的,虽然也是要加锁,但是这个锁互斥概率低,只能是轻锁化。
数据结构
上面介绍了G、M、P,下面我们深入源码看看,这三个究竟是什么东东。gmp数据结构定义在 runtime/runtime2.go文件中。以下截取片段:
G
type g struct {
// ...
m *m
sched gobuf
// ...
}
type gobuf struct {
sp uintptr
pc uintptr
ret uintptr
bp uintptr // for framepointer-enabled architectures
}
如上,在g中,有两个成员变量:
- m:是一个指向m的指针,之前说过,g和m是一个动态映射的,由p进行调整。 这个是一个指针,在p的作用下,也会实时调整的,会指向某个对象。
- sched:是一个gobuf的结构体,用户缓存相关内容
- sp:保存CPU的rsp寄存器的值,指向函数调用栈的栈顶;
- pc:保存CPU的rip寄存器的值,指向程序下一条执行指令的地址;
- ret:保存系统调用的返回值;
- bp:保存CPU的rbp寄存器的值,存储函数栈帧的起始位置;
生命周期
我们看看g的生命周期,主要是由以下几种状态组成:
const (
// G status
// 最开始的状态,为协程开始创建时的状态,此时尚未初始化完成。
_Gidle = iota // 0
// 初始化完成后,进入一个就绪待,随时可以被p调度器调度运行的,
_Grunnable // 1
// 如果被调度器调度到了,就会进入该状态,真正的在执行用户在执行函数的逻辑
_Grunning // 2
// 在running的时候,如果代码涉及到越过用户态去,在内核态下面发起系统调用,会进入当前状态,可以理解为协程正在执行系统调用
_Gsyscall // 3
// 在用户态视角下的一些阻塞操作,如加锁后,当前锁被其他协程取得,当前协程就需要等待。或者一些channel相关的阻塞,也会为当前状态。
// 当然并非一直wait下去,不然就是死锁了,会在某些条件达成之后,重新唤醒,然后切换到grunning状态。
_Gwaiting // 4
// 当前未使用
_Gmoribund_unused // 5
// 完成初始化后,会进入该状态
// 奇怪的是,函数正常执行完成后,协程被销毁了也是进入该状态,费解。
_Gdead // 6
// 当前未
_Genqueue_unused // 7
// 协程正在栈扩容流程中
_Gcopystack // 8
// 协程被抢占后的状态
_Gpreempted // 9
)
整个生命周期的流程如下:
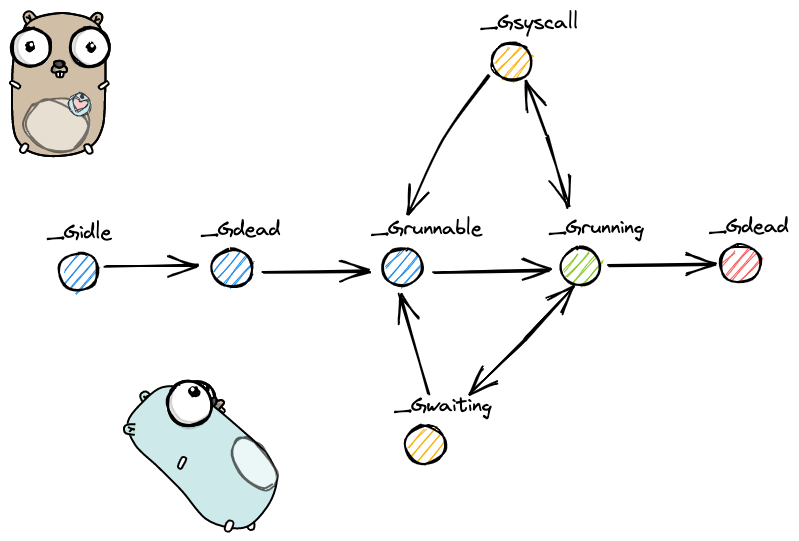
- 最开始协程开始创建后,状态为gidle;
- 在协程初始化完成后,状态为gdead;
- 初始化完成后,进入了一个就绪态,随时等待着被p调度器调度运行,状态为grunnable状态;
- 如果很幸运,被p调度器给调度运行了,则会进入grunning状态;
- 如果代码要调用一些系统相关的调用,则为gsyscall状态,如果调用完成后,继续进入grunnable状态,等待被p继续调用;
- 如果当前协程受到一些阻塞操作了,为gwating状态,当如不会一直等待,如果被唤醒,则进入grunnable状态,等待被p调度器调度;
- 最后,函数执行完成,正常流程结束,进入gdead状态。
M
machine,对一个线程的抽象,它直接关联一个os内核线程,用于执行G,非常珍贵的一个资源。 前面我们提到的g,是用户态下,异步创建好的协程,用户视角下执行的逻辑,而m中有一个特殊的goroutine,就是g0,它不执行用户函数,只是负责g之间的切换调度,也就是与不同g做调度切换,它来决定,执行哪个g,与m的关系为1:1。
type m struct {
g0 *g // goroutine with scheduling stack
// ...
tls [tlsSlots]uintptr // thread-local storage (for x86 extern register)
// ...
}
- g0:特殊的调度协程,负责g之间的切换调度
- tls:线程本地存储,存储内容只对当前线程可见。线程本地存储的是m.tls的地址,m.tls[0] 存储的是当前运行的g,因此线程可以通过g找到当前的m、p、g0等信息。
P
中央处理器,也可以理解为调度器,它的功能就是把可运行的Goroutine分配到工作线程上去。
之前全局模型我们说过,每一个p,都有一个本地队列,缓存自己私有的goroutine。
type p struct {
// ...
runqhead uint32 // 指向头部的指针
runqtail uint32 // 执行尾部的指针
runq [256]guintptr // 基于数组,实现的一个双向队列,容量上线为256
runnext guintptr // 特殊的指针,执行下一个可执行的goroutine
// ...
}
我们还说过,有一个全局的队列,当某一个P,发现自己的本地队列没有G的时候,就会去全局队列中查找。全局队列结构体如下:
type schedt struct {
// ...
lock mutex // 因为有很多P可能都会读取全局队列,所以有一把互斥锁
// ...
runq gQueue // 他本质也是队列
runqsize int32 // 全局队列的容量
// ...
}
调度链路
最为核心的功能讲解。
两种G的转换
就是g0和普通的g之间的转换。
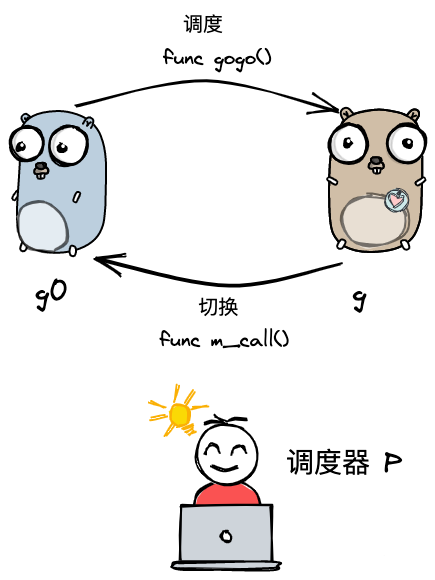
- 负责调度普通的g的g0,执行固定的调度流程,与m的关系为一对一;
- 负责执行用户函数的普通g。
m通过p调度执行Goroutine永远在普通g和g0之间进行切换,当g0找到可执行的g时,会调用gogo方法,调度g执行用户定义的任务;
当g需要主动让渡或被动调度时,会触发mcall方法,将执行权重新交给g0;
gogo和mcall可以理解为对偶关系。
调度类型
先上一个架构图吧。
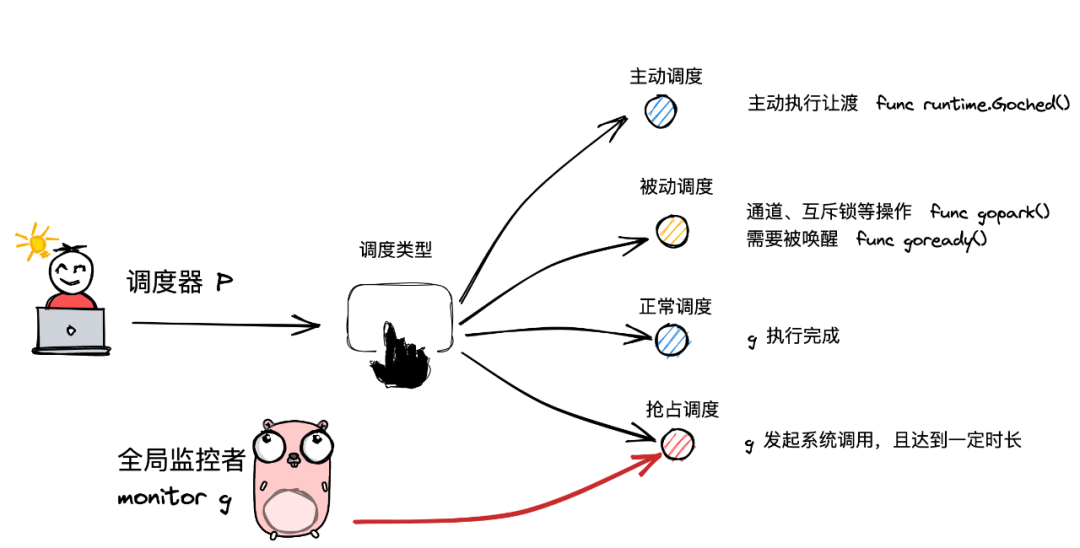
上图可见,我们调度器在调度的时候,由四种类型,分别是主动调度、被动调度、正常调度和一个抢占调度。下面我们分别讲解:
主动调度
一种用户主动执行让渡的方式,由用户发起,用户直接在执行代码中调用runtime包的一个到导出方法Gosched,此时当前g会让出执行权的能力,主动进行队列等待下次被调度执行。也就是当前g会从一个running切换成runnable状态,然后投递到全局队列中。
被动调度
并非用于意愿达成的,而是外在的因素导致Goroutine不得不调度的一个状态,比如加锁互斥,比如channel(读空通道、写满额)等待等等。因为这些情况没必要再去抢占P调度器的调度了,你只要安安静静的等待被唤醒即可。 被动调度,会陷入wait的状态。这个状态的转换,是由gopark函数,把running状态切换到wait状态。一旦被唤醒,则由goready函数,把wait状态切换成runable状态,重新拥有被P执行的权利。
正常调度
这就很简单了,对应的Goroutine把用户所有函数的代码逻辑执行完成,正常的销毁掉。把回归权到g0手上,然后由g0来决定下一个执行的g是谁。 g 中的执行任务已完成,g0 会将当前 g 置为死亡状态,发起新一轮调度.
抢占调度
比较特别,前三面都是由g0来完成,也就是用户态的来达成的。但是抢占并非如此。 比如g执行系统调用超过指定的时长,且全局的p资源比较紧张,此时将p和g解绑,抢占出来用于其他g的调度,等g完成系统调用后,会重新进入可执行队列中等待被调度。
因为发起系统调用时。需要打破用户态的边界进入内核态,此时m也会因系统调用而陷入僵局,无法主动完成抢占调度行为。 所以在Golang进程会有一个全局监控协程,monitor g 的存在,这个g会越过p直接与一个m进行绑定,不断轮询对所有的p的执行状态进行监控,一旦发现满足抢占调度的条件,则会从第三方的角度出手干预,主动发起该动作。
调度总概览图
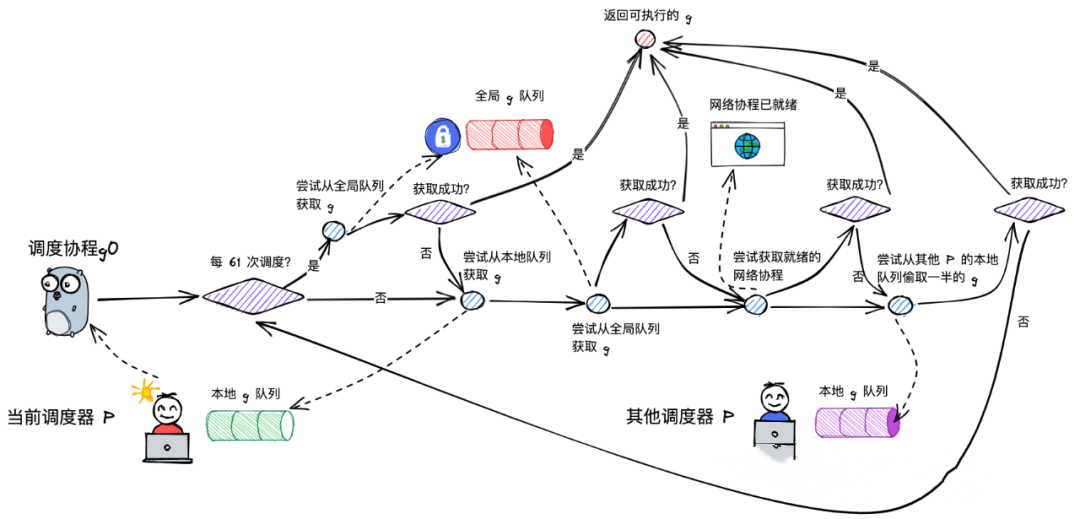 p或者g0,在获取普通g的时候,都是先从本地队列,然后再全局队列,然后再窃取其他队列获取,都是通过这三步。
p或者g0,在获取普通g的时候,都是先从本地队列,然后再全局队列,然后再窃取其他队列获取,都是通过这三步。
如上图:
- 每 61 次的本地队列获取g,这个61是写死的,经验值。这个次数达成的的情况下,会先从全局队列中获取g,这是防止每个p中的本地队列g过于充实,导致全局队列的g会陷入饥饿状态,则会每61次后,去全局里面看看。
- 否则,从本地队列获取g,本地队列有,则返回本地g队列,如果没有,则从全局队列获取g(通过加锁的方式)
- 如果全局队列获取g失败,则继续尝试从就绪态Goroutine中,获取g。如果没有获取成功,继续尝试从其他P的本地队列偷取(work-stealing )一半的g,如果偷取成功,返回可执行的g,如果失败,则继续调度循环。
work-stealing
从其他p中偷取g来执行的一个机制,叫做woek-stealing。
func stealWork(now int64) (gp *g, inheritTime bool, rnow, pollUntil int64, newWork bool) {
pp := getg().m.p.ptr()
ranTimer := false
const stealTries = 4
for i := 0; i < stealTries; i++ {
stealTimersOrRunNextG := i == stealTries-1
for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {
// ...
}
}
return nil, false, now, pollUntil, ranTime
可以看到,会尝试发起4次循环从其他p中获取g,一旦某一次窃取成功则返回了。引入了一个fastrand()随机的遍历的,保证公平性。
execute
成功找到了goroutine之后,要做哪些事情呢?
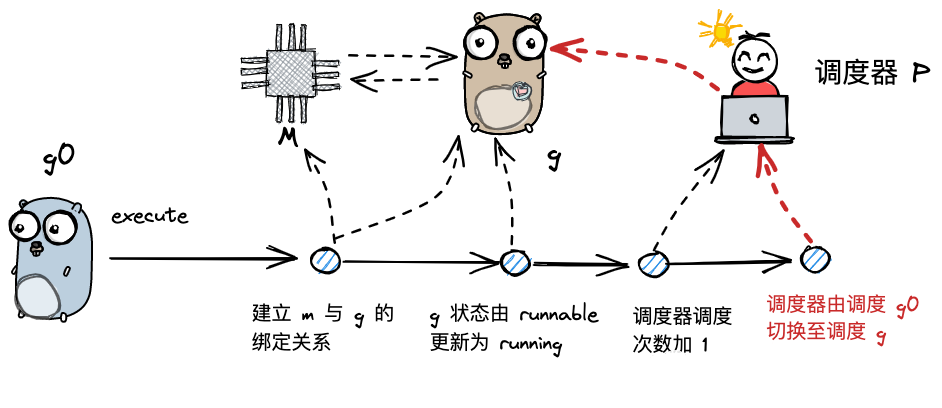
上图可以看出,找到需要执行g的时候:
- 先建立m和g的绑定关系,确定关系
- 把状态从runnable更新为runing,然后真正的执行用户的代码逻辑。
- 等到执行完成后,调度器由调度g0切换到调度g。

