
初始kafka
最开始有linkedin公司开发,是一个分布式的、支持分区的(partition),多副本的(replica),基于zookeeper协调的分布式消息系统,最大的特点就是可以实时的处理大量数据以满足各种场景需求,比如消息服务、日志存储分析,在2010年的时候贡献给了Apache基金会并成为顶级开源项目。

使用场景
一般来说,有如下场景需求,kafka可以解决:
日志收集
一个公司可以用Kafka收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
消息系统
解耦和生产者和消费者、缓存消息等。
用户活动跟踪
Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
运营指标
Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
基本概念
kafka是一个分布式的,分区的消息(官方称之为commit log)服务。它提供一个消息系统应该具备的功能,但是确有着独特的设计。可以这样来说,Kafka借鉴了JMS规范的思想,但是确并没有完全遵循JMS规范。
首先,让我们来看一下基础的消息(Message)相关术语:
- Broker:消息中间件处理节点,一个kafka节点就是一个Broker,一个或多个Broker可以组成一个kafka集群。
- Topic:kakfa根据Topic对消息进行归类,发布到kafka集群的每条消息都需要指定的topic,熟悉rbmq的话,这类似于交换机上面的路由key。
- Producer:生产者,每个mq都有这个角色,向Broker发送消息的客户端
- consumer:消费者,同样,每个mq都有这个角色,从Broker读取消息的客户端。
- ConsumerGroup: 当消费者处理不过来的时候,就需要一个消费者群组,每个consumer属于特定的consumerGroup,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该条消息。
- Partition: 物理上的概念,一个topic可以分为多个Partition,每个Partition内部消息是有序的。
- Replica: 副本,一个topic的每个分区都有若干个副本,一个Leader和若干个Follower。
- Leader:每个分区多个副本的主节点,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
- Follower: 每个分区多个副本的从节点,实时从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个follower,也就是从节点会成为新的Leader。
其中的关系如下图: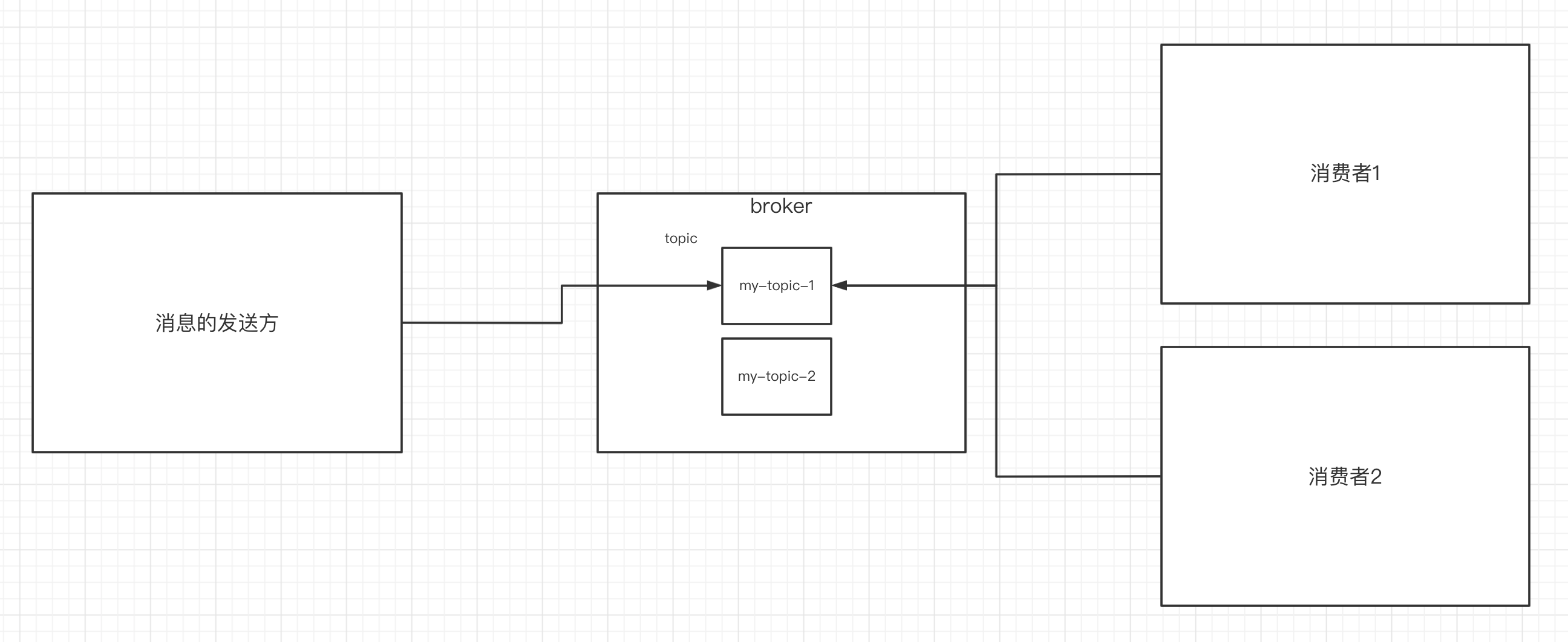
这些概念,我们先了解,后续再继续强调。
安装
熟悉的胖友都知道,我一般喜欢使用docker安装,这次也不例外。在kafka2.8版本之前,kafka都是强依赖zookeeper这个分布式服务协调管理工具,在2.8版本开始尝试从服务架构中去掉zookeeper,到了3.0版本,这个工作基本完成,这是kafka一个非常重要的里程碑。
zookeeper相关可以移步:zookeeper应用及其原理解析
但是如果想要理解kafka3.0的新架构设计,还是有必要了解下kafka2.X版本中zp的作用是什么,而且在大部分的企业中,用的还是2.X版本的kafka,所以我们学习也是基于2.x版本,后续会出一篇3.0版本的讲解,算是一个flag。
拉取相关镜像
docker pull wurstmeister/kafka:2.12-2.5.0 docker pull zookeeper启动容器
docker run -d \ --name kafka \ -p 9092:9092 \ -e KAFKA_ZOOKEEPER_CONNECT=124.223.47.250:2182 \ -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \ -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://124.223.47.250:9092 \ wurstmeister/kafka:2.12-2.5.0- KAFKA_ZOOKEEPER_CONNECT:为zookeeper的地址,因为kafka是需要依赖zk做无状态化
- KAFKA_LISTENERS=PLAINTEXT:是 Kafka Broker 的监听器配置的一部分,用于指定 Kafka Broker 内部监听的地址和传输协议,plaintext为明文传输
- KAFKA_ADVERTISED_LISTENERS:是 Kafka Broker 的广告监听器配置的一部分,用于指定 Kafka Broker 向外部客户端广告的地址和传输协议
验证
直接docker ps,如果两容器都在,说明正常安装。需要注意的是kafka会和zookeeper保持心跳,如果中间链接不起来的话,kafka容器会宕机,可以再等30s左右再看看kafka容器是否存在。如果链接不上,可以检查zookeeper网络问题、防火墙等等。
命令操作
为什么是命令?我们在学习的时候,开始都是通过命令来的,但是在工作中肯定是通过代码实现的。
进入kafka容器,容器中的命令路径在:/opt/kafka/bin/中,可以使用export PATH=$PATH:/opt/kafka/bin/放入全局PATH变量中。
主题topic
kafka-topics.sh --create --topic animal --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1
bash-5.1# kafka-topics.sh --create --topic animal --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1
Created topic animal.
我们来依次分析解释一下:
- -create --topic animal : 这个表示创建一个topic,topic的name就是animal
- --bootstrap-server localhost:9092 :指定用于引导客户端的kafka服务器的连接地址,后面意味着连接到本地主机的kafka服务
- --replication-factor 1 :指定每个分区的副本数,前面提过,一个topic的每一个分区都有副本,因为kafka具有复制机制,提高容错性和可用性,副本数应该小于等于kafka集群中可用的Broker数量,我们目前没有集群,所以为1.
- --partitions 1 :指定topic应该有多少个分区,分区是kafka的数据的逻辑单元,一个topic可以分为多个partitions,每个partitions内部消息都是有序的。通常,分区应该根据负载和并发需求进行调整。
那topic的信息存在哪里呢?
别急,我们看看下一条命令,就是查看当前kafka有多少个topic。
命令: kafka-topics.sh --list --zookeeper 124.223.47.250:2182
bash-5.1# kafka-topics.sh --list --zookeeper 124.223.47.250:2182
__consumer_offsets
animal
my-topic
看到没,需要指定zookeeper的路径,我们之前也说过,zk可以保存状态的信息,topic的信息,很明显就是保存在zk里面。
我们来看看zookeeper里面,有啥?
[zk: localhost:2181(CONNECTED) 4] ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
消息发送
kafka自带了producer命令客户端,可以从本地文件中读取内容,或者我们直接通过命令行直接输入内容,并将这些内容以消息的形式发给kafka集群,默认情况下,每一个行会被当做一个独立的消息,我们使用kafka的发送消息的客户端,指定发送到kafka服务器和topic。
命令:kafka-console-producer.sh --topic animal --bootstrap-server localhost:9092
解释就是,向bootstrap-server的客户端发送消息,发到topic为animal上面去。
bash-5.1# kafka-console-producer.sh --topic animal --bootstrap-server localhost:9092
>
命令行卡主,等待输入消息。
当然,接收消息需要另外起一个客户端。
消息接收
同样,kafka自带了consumer,从新起一个窗口,命令为:kafka-console-consumer.sh --topic animal --bootstrap-server localhost:9092 --from-beginning
解释就是:从--bootstrap-server的主题为--topic animal中读取消息,从哪开始读取呢?从--from-beginning 表示从头开始消费。
当,还有一种形式,就是不带--from-beginning,表示从最后一条消息的偏移量+1开始消费。

原理篇
按照我们上面的讲解,我们再来个流程: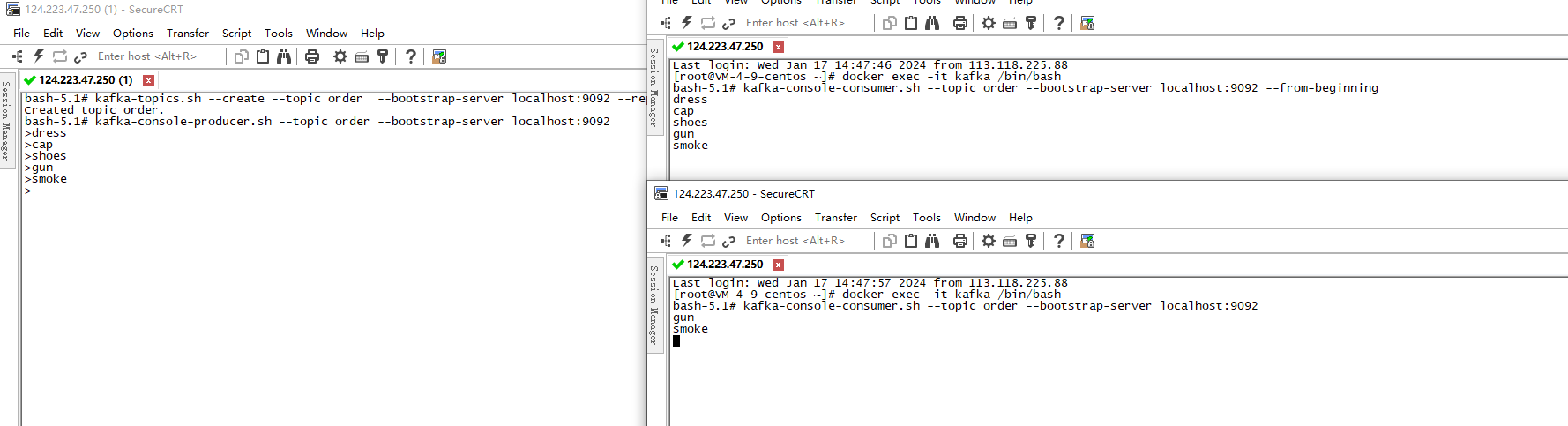
- 新建了一个topic,名为order,并依次发一些消息:dress->cap->shoes
- 在发到shoes后,加入消费者1,并指定from-beginning,如左上图,加入后收到了dress->cap->shoes。
- 同样时间,加入消费者2,但并未指定from,也就是从最后一条消息的偏移量+1开始消费,目前还未消费。如左下图。
- 生产者继续生成消息为:gun->smoke. 两个消费者都收到了消息。
这里就有一些东西,需要考虑了。
比如消息如何存储的?消息如何保证顺序的?消息偏移量是什么?为什么可以指明偏移量进行消费呢?
消息存储和消费
明显可以看出,消费者1可以从头开始消费,那就说明消息肯定是落地在某个位置了,不然如何消费?

我们追踪一下,在kafka中有一个logs文件目录,跟下去,可以看到有50个分区的Consumer的offsets,这其实就是每个消费者去维护自己消费端具体位置,具体的我们后续讲解,再注意看,有一个topic样的,比如我们刚刚建立的order-0,my-topic-0等等,这些跟进去看看。
bash-5.1# ls
00000000000000000000.index 00000000000000000000.log 00000000000000000000.timeindex leader-epoch-checkpoint
- .index:索引相关,这些文件包含了 Segment 文件中消息的索引信息。索引使得 Kafka 能够通过消息的 offset 快速定位到消息的物理位置,提高读取效率。
- .timeindex 时间索引相关,这些文件包含了 Segment 文件中消息的时间索引。时间索引允许 Kafka 在给定时间范围内进行消息的检索,以支持时间相关的查询操作。
- .log 这些,才是真正保存kafka消息的文件,
也就是生产者将消息发Broker,Broker会将消息保存在本地的日志文件中。
我们来画个图:
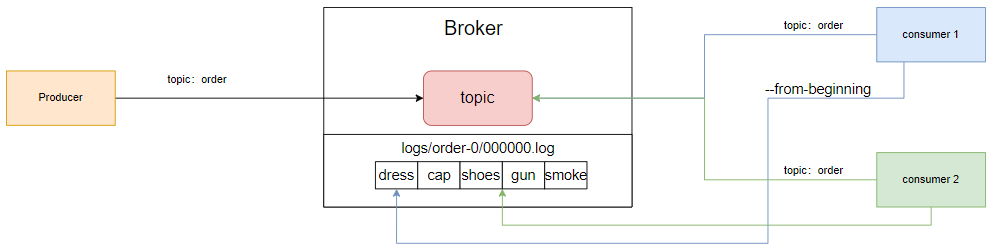
- producer,根据topic,将消息发送给Broker,Broker会将消息保存在logs中,然后根据topic进行分类保存。
- consumer1和2,根据topic去broker中获取消息。
- 当然,消息是有序的,通过offset偏移量来描述消息的顺序。
- 消费者消费消息,也是通过offset来消费的那条消息的位置。很明显,consumer1和2是不一样的。
单播消息
如上图,我们一个producer往topic为order中生产一条消息,两个消费者同时进行监听,这两个消费者,几乎同时收到了这条消息。
这种明显是有问题的,比如说在集群的环境下,如果A和B两个节点都是消费端,我们注册的时候使用发送短信的机制,这样注册后生产消息,A和B都收到了,岂不是发送两条?
为了解决这个问题,kafka就引出了:消费者。
我们可以通过命令:--consumer-property.sh --group=groupName 在设置消费者的时候将其划分到一个消费组里面,这样就只有一个消费者可以消费了。如:
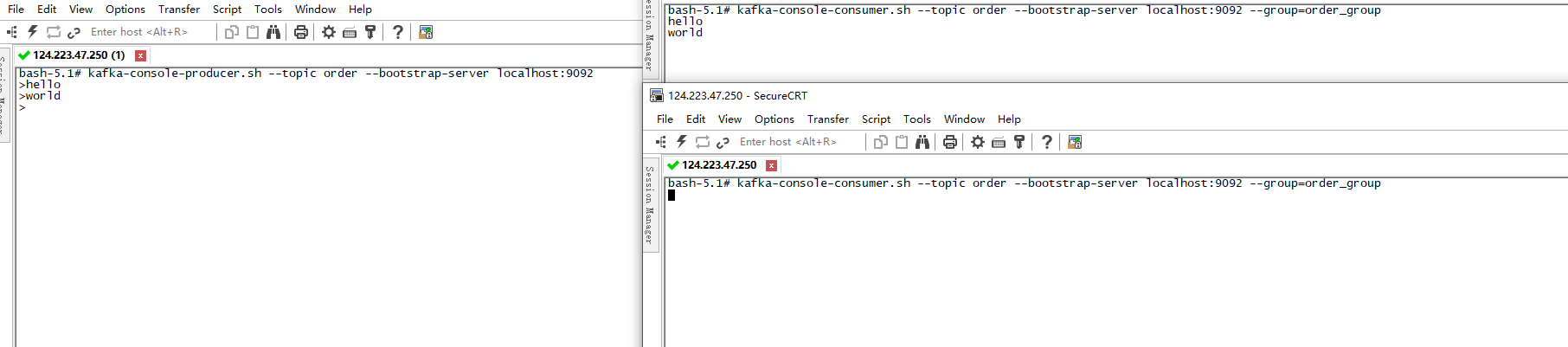
当然咯,此时消费者里面有一个消费者挂掉了,那么机会由其他正常运行的消费者继续进行消费,也算是增加了消费者的高可用。
两个消费者在同一个组,只有一个能接到消息,两个在不同组或者未指定组则都能收到
多播消息
还是注册的场景,除了发短信,可能还有审计方面的也需要监听注册的信息,那如果消息被发短信的消费了,那审计的如何进行消费呢?好了,多播消息来了。
当多个消费组同时订阅一个Topic时,那么不同的消费组中只有一个消费者能收到消息。实际上也是多个消费组中的多个消费者收到了同一个消息
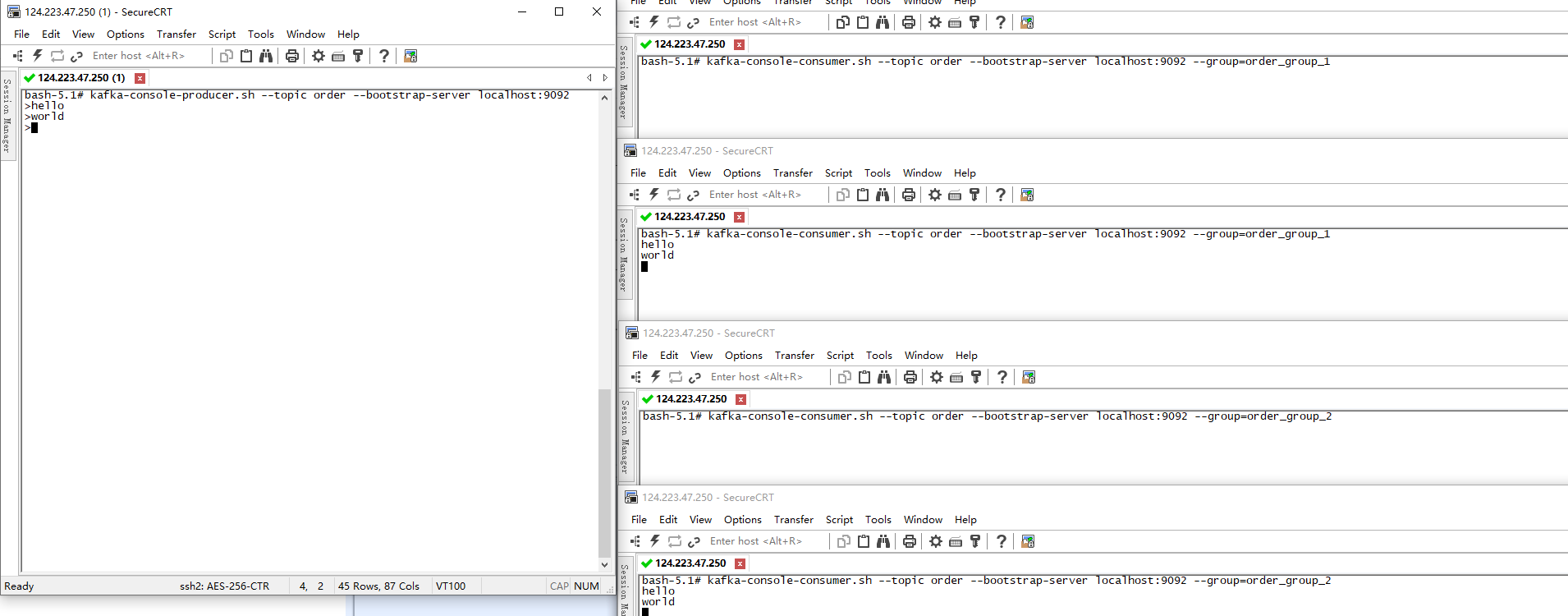
- 左窗口为生产者
- 右窗口上面1/2窗口为消费者,同时在同一个组
- 右窗口下面1/2窗口为消费者,同时在另外一个组
明显可以看出,同一个组,只有一个消费者可以消费到消息,多个消费组中可以有多个消费者消费到消息。
当然,我们也可以查看当前kafka下面有哪些消费组:kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
bash-5.1# kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
order_group_2
order_group_1
order_group
我们也可以查看这些组下面的具体信息:kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group order_group_1
bash-5.1# kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group order_group_1
Consumer group 'order_group_1' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
order_group_1 order 0 13 13 0 - - -
- TOPIC:当前group监听的主题
- PARTITION:又看到分区了,看来不细讲不行了
- CURRENT-OFFSET:也就是当前的偏移量。
- LOG-END-OFFSET:这个就是当前已经消费的偏移量
- LAG:还有多少消息还没有被消费
这样看没有对比,我们把group_1这个组的消费者全部下线,然后生产一条消息后,再次执行具体信息:
bash-5.1# kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group order_group_1
Consumer group 'order_group_1' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
order_group_1 order 0 13 14 1 - - -
此时就很明显了吧,当前的offset就是当前消费组消费到的消息的index,总共有14条,目前还有一条没有被消费。
partition 分区
想必看到现在,对主题应该有一定的概念了吧。
主题并不是一个物理上的划分,而是一个逻辑的概念,kafka通过topic将消息进行分类,不同的topic会被订阅不同topic的消费者消费。
但有一个问题,消息是会落地保存在硬盘中的,比如订单分发使用kafka,或者日志分发等等,加入一个topic的消息非常非常的多,多到需要几T的硬盘来存,文件一旦就会出现问多问题,比如迁移、更新、查询等等,效率都会受到影响。
kafka为了解决这个问题,就引入了分区的概念。
Topic是一个逻辑概念,消息都是按照Topic来进行逻辑区分,而Partition是物理概念,Kafka中Topic都是以Partition分区来存放的,每个 Partition 从物理层面来讲都是一个单独的 log 文件
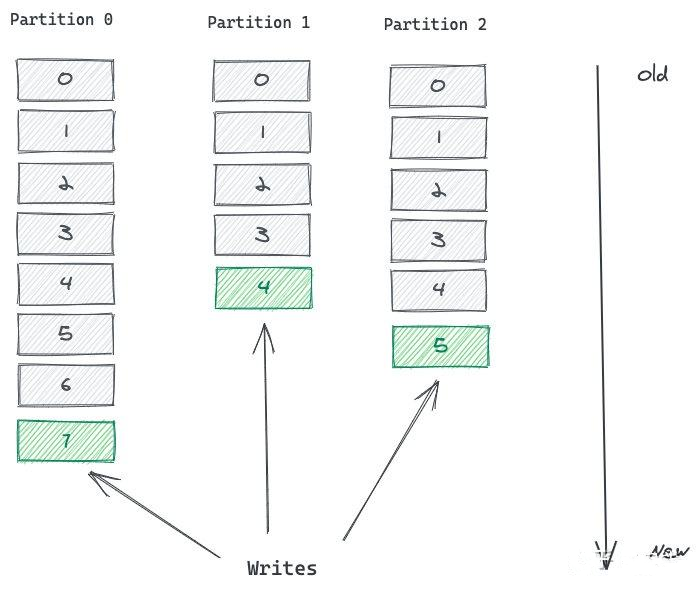
比如上图,同一个topic可以创建很多个partition,每次写的时候,都可以往不同的partition中写,但是读的时候,kafka会找到对应的partition去读取。好比我们Windows的电脑硬盘,整块硬盘就是一个topic,但是可以分为C/D/E盘的分区一样。
这样的好处如下:
并行处理
- 分区允许消息的并行处理,每个分区都可以独立的收发消息,使得kafka能够在集群中的多个节点并行执行读写操作,提高吞吐量。
- 消费者组的每个消费者可以独立的处理一个分区的消息,从而实现更好的水平扩展。
负载均衡
- 一个主题划分多个分区,实现消息的负载均衡,消费被分步到不同的分区中,不同的分区可以分配不同的broker,均匀的分散了负载
- 防止热点分区的产生
水平扩展
- 当消息量增加的时候,可以通过增加分区的数量来扩展kafka集群的性能
顺序性和局部性
- 每个分区的消息是有序的,这有助于保持一组相关消息的顺序性
- 消费者可以选择订阅某个特定的分区,以实现对数据的局部性访问,避免了消费者需要处理所有的消息的情况
容错性
- 每个分区都有多个副本,后面会讲,副本分步在不同的broker上,当一个broker失效,其他副本可以继续提供服务,确保消息的可用性
创建分区
分区是和主题相关的,所以我们创建主题的时候,指定分区的个数即可。
kafka-topics.sh --create --topic order-part --bootstrap-server localhost:9092 --partitions 3 --replication-factor 1
- --partitions 3:指定主题的分区数为 3。
- --replication-factor 1:指定主题的每个分区的副本数为 1。这里设置为 1,表示在 Kafka 集群中只有一个副本,仅用于演示。在生产环境中,通常会设置多个副本以确保数据的可靠性。
我们来看看topic下的具体信息:
bash-5.1# kafka-topics.sh --describe --zookeeper 124.223.47.250:2182 --topic order-part
Topic: order-part PartitionCount: 3 ReplicationFactor: 1 Configs:
Topic: order-part Partition: 0 Leader: 1001 Replicas: 1001 Isr: 1001
Topic: order-part Partition: 1 Leader: 1001 Replicas: 1001 Isr: 1001
Topic: order-part Partition: 2 Leader: 1001 Replicas: 1001 Isr: 1001
我们继续看看logs下的信息: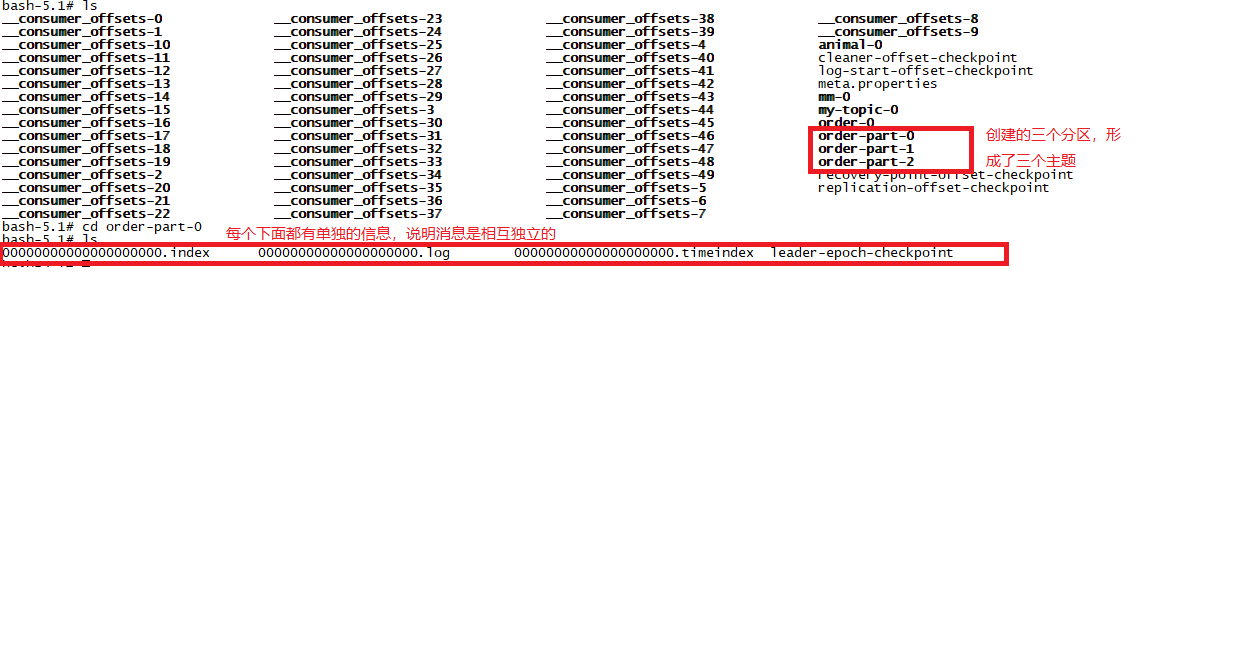 那么,分区的话,生产的消息落在哪个分区呢?
那么,分区的话,生产的消息落在哪个分区呢?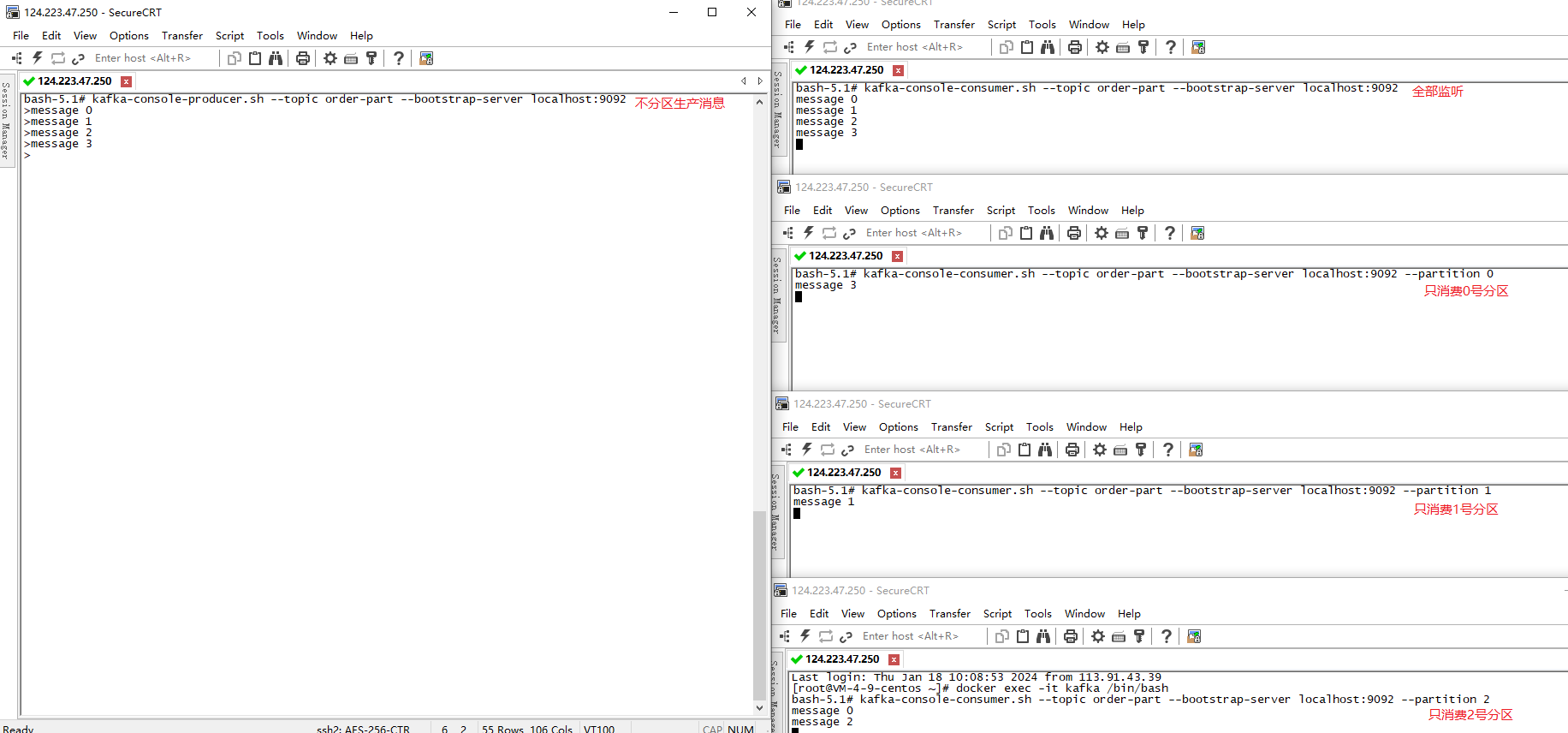
由此可见,如果我们不指定分区控制策略,默认的是采用轮询的方式进行分区,这也满足了大多数场景,确保消息被均匀的分步到各个分区中。当然,你也可以自定义分区器来满足特定的需求,这个就不讨论了。
consumer offsets分区
上图,我们在logs下面,可以看kafka内部自己创建了__consumer_offsets-0-50,这代表什么呢?用来干什么的呢?
我们设想一个场景,目前topic中有100条消息,有一个消费者G1,两个消费者A和B,其中A消费了50条,然后宕机了,轮到B来顶上来,B是如何知道当前消费组具体消费到哪里了呢?
嗯,kafka为了解决消费者、消费组的消费进度偏移量,也就自己创建了50个分区,用来存放topic消费的偏移量,每个消费者都会自己维护着消费的主题的偏移量,也就是说每个消费者会把消费的主题的偏移量自主上报给kafka中的默认主题,kafka为了提升主题的并发下,默认设置了50个分区。
- 提交到哪个分区:通过hash函数:hash(consumerGroupId) % __consumer_offsets主题的分区数
- 提交到该主题中的内容是:key是consumerGroupId + topic + 分区号,value就是当前offset的值
还有就是,文件保存的消息并非永久的,默认保存7天,7天后消息自动删除.
使用go客户端连接
- 生产者
func ProduceMessages(topic string, value string) {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll // 发送完数据需要leader和follow都确认
config.Producer.Partitioner = sarama.NewRandomPartitioner // 新选出一个partition
config.Producer.Return.Successes = true // 成功交付的消息将在success channel返回
producer, err := sarama.NewSyncProducer([]string{"124.223.47.250:9092"}, config)
if err != nil {
log.Fatal("Error creating producer:", err)
}
defer producer.Close()
message := &sarama.ProducerMessage{
Topic: topic,
Value: sarama.StringEncoder(value),
}
partition, offset, err := producer.SendMessage(message)
if err != nil {
log.Println("Failed to send message:", err)
} else {
log.Printf("Produced message to partition %d at offset %d\n", partition, offset)
}
}
- 消费者
func ConsumeMessages(topic string) {
config := sarama.NewConfig()
config.Consumer.Return.Errors = true
consumer, err := sarama.NewConsumer([]string{"124.223.47.250:9092"}, config)
if err != nil {
log.Fatal("Error creating consumer:", err)
}
defer consumer.Close()
partition := int32(0)
// 指定监听某个分区
partitionConsumer, err := consumer.ConsumePartition(topic, partition, sarama.OffsetOldest)
if err != nil {
log.Fatal("Error creating partition consumer:", err)
}
defer partitionConsumer.Close()
signals := make(chan os.Signal, 1)
signal.Notify(signals, os.Interrupt)
var wg sync.WaitGroup
ConsumerLoop:
for {
select {
case msg := <-partitionConsumer.Messages():
log.Printf("Consumed message from partition %d at offset %d: %s\n", msg.Partition, msg.Offset, string(msg.Value))
case err := <-partitionConsumer.Errors():
log.Println("Error:", err)
case <-signals:
break ConsumerLoop
}
}
wg.Wait()
}

