
集群搭建
还是使用docker,我们搭建三个broker,其实很简单,如下命令即可:
# 第一个节点,brokerid为0,port为9091
docker run -d \
--name kafka01 \
-p 9091:9092 \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ZOOKEEPER_CONNECT=124.223.47.250:2182 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9091 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://124.223.47.250:9091 \
-e KAFKA_HEAP_OPTS="-Xmx512M -Xms512M" \
wurstmeister/kafka:2.12-2.5.0
# 第二个节点,brokerid为1,port为9092
docker run -d \
--name kafka02 \
-p 9092:9092 \
-e KAFKA_BROKER_ID=1 \
-e KAFKA_ZOOKEEPER_CONNECT=124.223.47.250:2182 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://124.223.47.250:9092 \
-e KAFKA_HEAP_OPTS="-Xmx512M -Xms512M" \
wurstmeister/kafka:2.12-2.5.0
# 第三个节点,brokerid为2,port为9093
docker run -d \
--name kafka03 \
-p 9093:9092 \
-e KAFKA_BROKER_ID=2 \
-e KAFKA_ZOOKEEPER_CONNECT=124.223.47.250:2182 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9093 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://124.223.47.250:9093 \
-e KAFKA_HEAP_OPTS="-Xmx512M -Xms512M" \
wurstmeister/kafka:2.12-2.5.0
判断是否搭建成功,我们可以去zookeeper中查看:
root@3777bd553e3b:/bin# zkCli.sh
[zk: localhost:2181(CONNECTED) 1] ls /brokers
[ids, seqid, topics]
[zk: localhost:2181(CONNECTED) 0] ls /brokers/ids
[0, 1, 2]
很明显,三个brokers的id都起来了,说明zookeeper还帮我们维护了集群的状态。
副本
之前聊过分区,分区就是把一个主题划分一个或多个分区,来提高并发能力,但是如果某一个分区出现问题了,那数据也就丢失了,所以kafka引出了副本。kafka的副本指的是将同一份数据复制到多个地方,来提高可靠性和容错性,即使其中一个节点发生故障,也能够保证数据的可用性。在集群环境,不同的副本会被部署到不同的broker上
我们来举个例子,创建一个topic,然后使用两个分区,三个副本。
kafka-topics.sh --create --topic my-replicated-topic --bootstrap-server localhost:9092 --replication-factor 3 --partitions 2
创建完成后,我们来看看topic的情况:
# 查看topic情况
bash-5.1# kafka-topics.sh --describe --zookeeper 124.223.47.250:2182 --topic my-replicated-topic
Topic: my-replicated-topic PartitionCount: 2 ReplicationFactor: 3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: my-replicated-topic Partition: 1 Leader: 1 Replicas: 0,1,2 Isr: 0,1,2
- 我们创建了两个分区,所以就会有Partition:0和Partition:1
- 我们又实用了三个副本,所以就会有Replicas: 2,0,1。
- Leader,负责kafka的写和读的操作,都发生在leader上。leader负责把数据同步给follower。当leader挂了,经过主从选举,从多个follower中选举产生一个新的leader
- isr:可以同步和已同步的节点会被存在isr集合中,如果isr中的节点性能较差,会被踢出isr集合,后续leader挂了选举,从isr中选举。
我们来画个图表示一下:
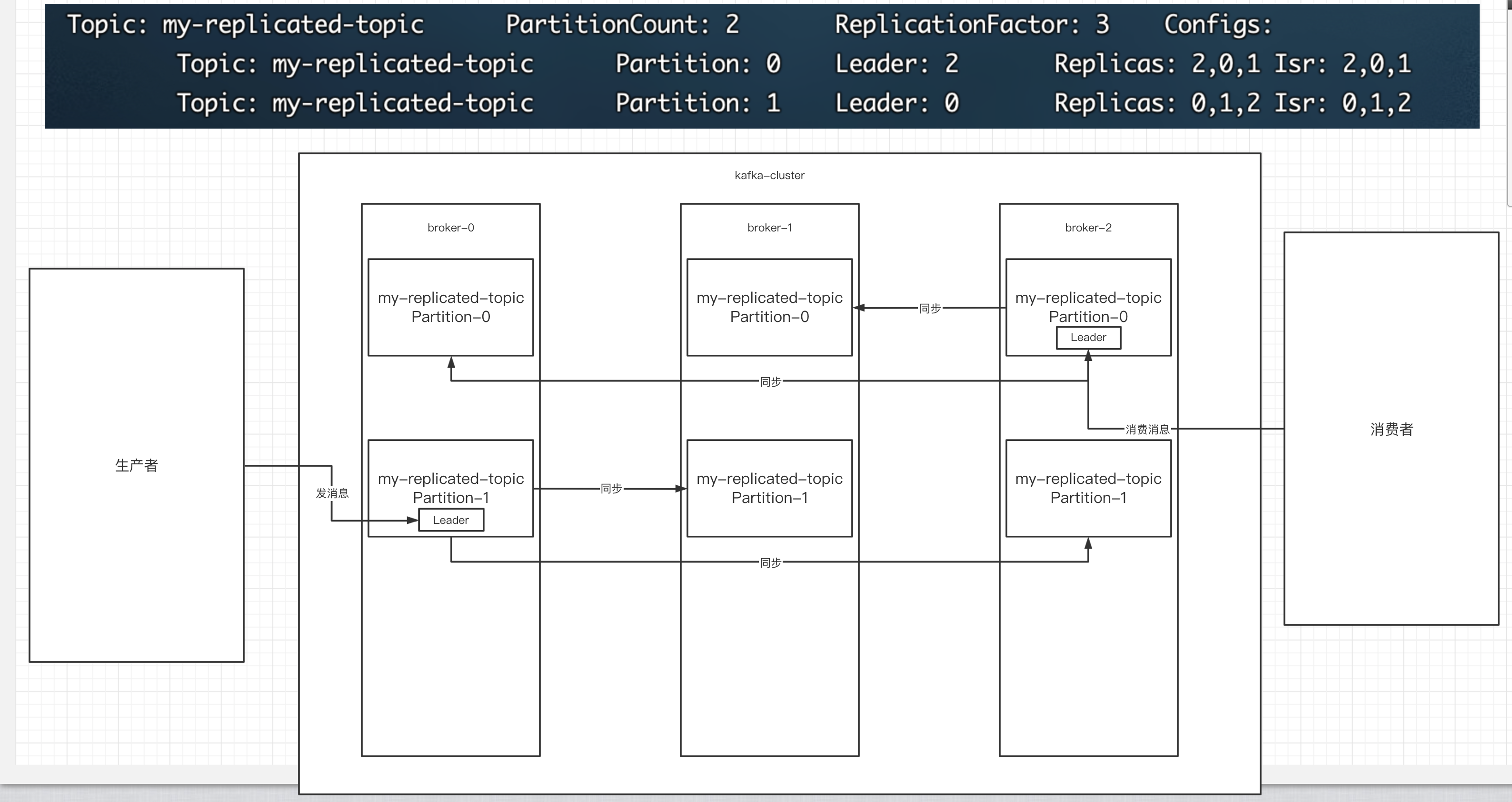
- 我们创建了三个副本,所以就会有三个broker。
- 我们又创建了两个分区,所以这三个broker上面,都会有两个分区,partition-0和partition-1
- 经过选举,从这三个broker上,选择一个为leader,如broker-2上面,就是partition-0的leader。
- 生产者把消息发送到leader上面,消费者从leader上面读取消息。
- 其余非leader的副本上搭载的分区,只能做同步的操作。
这个图,非常重要:
一句话就是: 集群中有多个broker,创建主题时可以指明主题有多个分区(把消息拆分到不同的分区中存储),可以为分区创建多个副本,不同的副本存放在不同的broker里。
之前我们聊过,在logs下面会存在topic分区之后的产物,还有表示消费者消费偏移量的50个记录,但是如果是多副本的(集群模式)下的话,消费者偏移量记录,只会存在一个副本中,因为只保留一份就可以了,但是每个副本都会记录topic下的分区信息。
bash-5.1# ls
cleaner-offset-checkpoint meta.properties my-replicated-topic-1 replication-offset-checkpoint
log-start-offset-checkpoint my-replicated-topic-0 recovery-point-offset-checkpoint
bash-5.1# pwd
/kafka/kafka-logs-cdf24840ddd5
如上图,每个副本都会记录my-replicated-topic-0,my-replicated-topic-1 因为partition在每个副本中都存在。
集群生产和消费消息
较比之前不同,生成和消费现在是要往集群里面发。
生产消息
kafka-console-producer.sh --broker-list 124.223.47.250:9091,124.223.47.250:9092,124.223.47.250:9093 --topic my-replicated-topic消费消息
kafka-console-consumer.sh --bootstrap-server 124.223.47.250:9091,124.223.47.250:9092,124.223.47.250:9093 --from-beginning --topic my-replicated-topic
这都是比较简单的,没什么好强调的,比较麻烦的点在于,消费的时候,如果是消费组,那如何处理?
kafka-console-consumer.sh --bootstrap-server 124.223.47.250:9091,124.223.47.250:9092,124.223.47.250:9093 --from-beginning --consumer-property group.id=testGroup1 --topic my-replicated-topic
分区消费组详解
如下,有两个副本,broker0和1,其中创建了四个分区partition0/1/2/3,有两个消费者组GroupA和B,分别有6个消费者,GroupA中有C1,2,GroupB中有C3,C4,C5,C6。说明一个topic有四个分区。
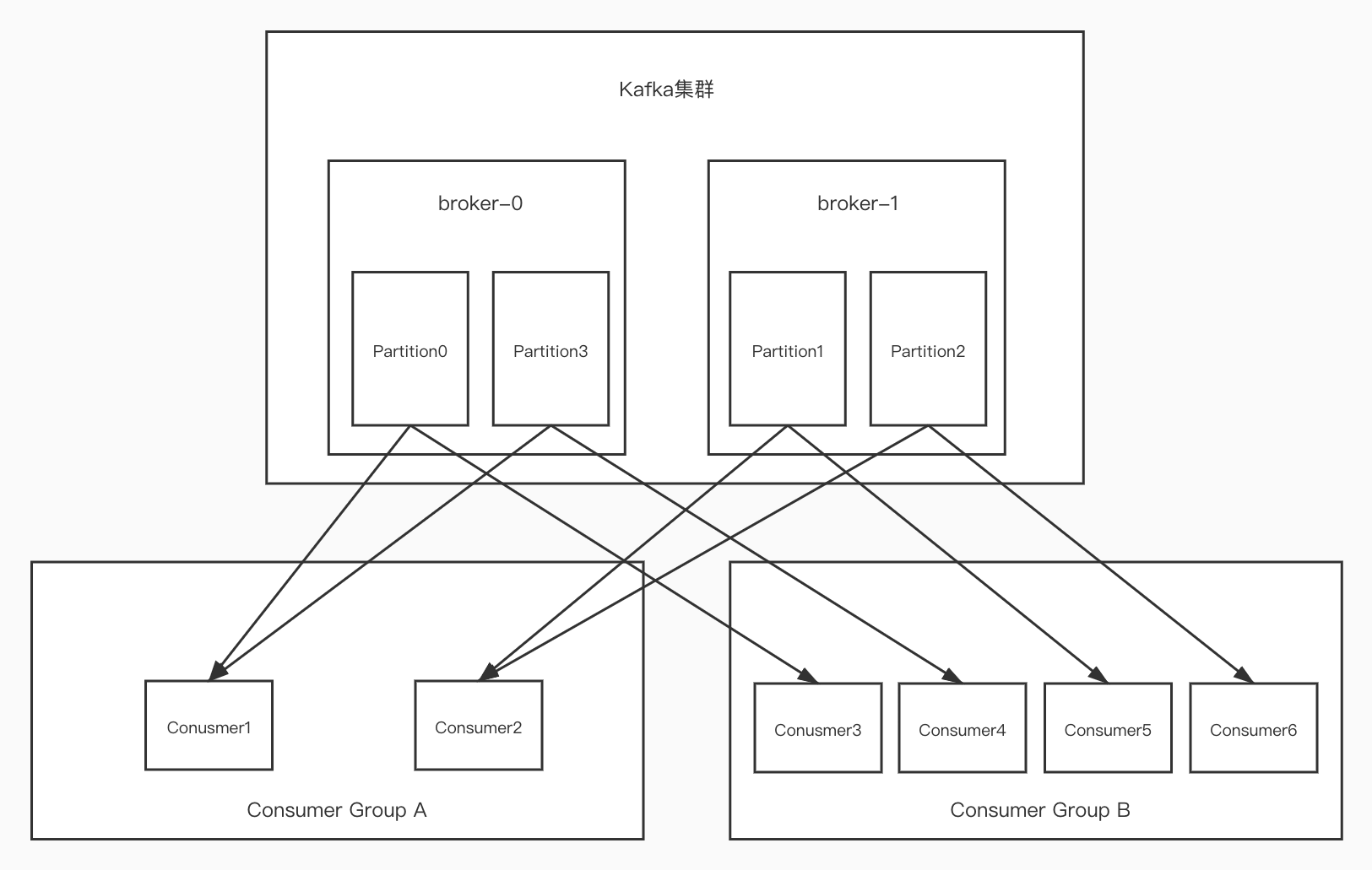
- 对于一个Partition来说,只能被一个消费者里面的某一个消费者消费,比如Partition0,只能被GroupA中的Consumer1或者Consumer2来消费。一旦被Consumer1消费,那么Consumer2是消费不到的,图中表示由Consumer1来消费。这是单播消息
- 对于GroupB来说,有四个消费者,它可以消费四个分区,比如Consumer3只能消费Partition0-3中间的其中一个。假如GroupB中再增加一个Consumer7,正常来说它是收不到消息,但是有个作用就是如果消费者里面有消费者宕机了,Consumer7是可以顶上去的,它可以作为备胎。
- 假设消费组中间,有个消费者挂掉了,比如GroupB中的Consumer5挂掉了,此时还可以消费Partition1中的消息吗?对于kafka来说,有个rebalance机制,它可以指定组内另外一个Consumer来消费,比如Consumer3来,但是不能给Consumer6来消费。因为一个Partition只能被一个group中的一个Consumer消费,但是一个Consumer可以消费多个Partition,嗯,是有点绕。
总结:在多个broker多个Partition中,一个Partition只能被一个消费组里面的一个消费者消费,因为要保证消费顺序,因为消息是有顺序的,消费的时候也应该是按顺序消费,如果可以被同一个消费组里面多个消费者消费的话,那就意味着顺序会乱。
kafka只在Partition的范围内保证消息消费的局部顺序,不能在同一个topic的多个Partition中保证总的消息消费顺序,比如上图,1号消息发送到Partition0,2号消息发到Partition3,3号消息发到Partition1,这能保证消费的顺序是1,2,3吗?不能,但是可以保证1和2的顺序。
消费组中消费者的数量不能比一个topic中的Partition数量多,否则多出来的消费者消费不到消息。
leader和Followers复制
Leader 通过复制日志(Log)来实现数据的复制。Kafka 中的每个分区都有一个 Leader 副本,这个 Leader 负责处理所有的读和写操作。消息首先被追加到 Leader 副本的本地日志中,然后异步地复制到 ISR(In-Sync Replicas,同步副本)中的其他副本。
Kafka 中的日志是由多个分段(Segment)组成的,每个分段包含一定范围内的消息。当一个分段满了,Kafka 就会创建一个新的分段。Leader 副本的日志是由多个分段按顺序组成的,而 ISR 中的副本则包含它们自己的日志分段。
在 Kafka 中,Leader 与 Followers 之间的数据复制是通过 Followers 主动向 Leader 发送 Fetch 请求来完成的。Fetch 请求的作用是获取 Leader 中未同步的消息,以确保 Followers 与 Leader 保持同步。
步骤是:
- Followers 发送 Fetch 请求: Followers 定期向 Leader 发送 Fetch 请求,请求未同步的消息。这个请求包含 Followers 目前已经复制的消息的偏移量(Offset)。
- Leader 响应 Fetch 请求: Leader 收到 Fetch 请求后,会响应 Followers,并将未同步的消息发送给 Followers。Leader 根据 Followers 发送的已复制消息的偏移量确定需要发送的消息范围。
- Followers 追加消息: Followers 收到 Leader 的响应后,将未同步的消息追加到自己的日志中。
- Leader 更新 High Watermark: Leader 会更新 High Watermark,表示所有 ISR 中的副本都已成功接收到这些消息。
Controller
如上图,如果在broker中的leader宕机了,应该如何选出新的leader?那么controller来了。
在kafka中,Controler是一个特殊的角色,负责集群中的一些重要管理任务,比如分区的副本分配、leader选举,broker的上下检测等等,是协调整个kafka集群的状态。
那集群中,谁来充当controller呢?
每个broker启动的时候,会想zk创建一个临时序号节点,获得的序号最小的节点,也就是最先创建的节点,就是集群的controller,它负责集群中的所有分区和副本状态:
当某个分区的leader副本出现故障的时候,由controller为该分区选举新的leader副本。
选举的规则就是从iSr集合中最左边获得。如下图:
比如broker-2中为Partition0的leader,此时isr为:2,0,1,如果leader挂了后,就选举了0,因为0在最左,isr根据性能等等来判断谁在左。
当集群中有broker新增或减少的时候,controller会同步信息给其他broker,更新元数据信息。
比如broker2挂掉了,就需要通过controller通知broker0和1。或者是新增了一个broker3,也会通知所有的broker。
当集群中有分区新增或减少的时候,controller会同步信息给其他broker。
比如新增加了Partition,就会同步其他的broker。
rebalance
还是拿这个图来吧:
比如Consumer6宕机了,那Partition2是不是在GroupB中没有人消费了,是不是应该移交给另外一个消费者?这就触发了rebalance机制,那移交给谁呢?这是第一个问题。
Consumer6宕机后,此时新增了一个Consumer7,又会触发rebalance,又会进行重新分配,那怎么分配呢?这是第二问题。
rebalance是消费者没有指明分区消费,当消费者里消费者和分区的关系发生变化的时候,就会触发rebalance机制。这个机制会重新调整消费者消费哪个分区,一般有三种策略:
- range:通过公式来计算消费者消费哪个分区
- 轮询:大家轮着消费, 这是最简单的策略,将分区按顺序轮流分配给消费者。例如,有两个消费者,两个分区,第一个消费者负责第一个分区,第二个消费者负责第二个分区。
- sticky:在触发rebalance后,消费者消费的原分区不变的基础上进行调整。 这种策略尽可能地保持分区和消费者之间的关联性,即尽量避免将一个分区在不同消费者之间频繁切换。这有助于减少不必要的分区迁移。
HW和LEO
HW俗称高水位,highwatermark的缩写。
在 Kafka 中,HW(High Watermark,高水位)是指每个分区中已经被成功复制到所有 ISR(In-Sync Replicas,同步副本)的消息的偏移量。High Watermark 是一个重要的概念,它表示了分区的最高提交位点,即已经被所有 ISR 成功接收的消息的位置。
还有一些其他的术语:
- LEO:指的是分区日志中最后一条消息的偏移量,LEO表示当前分区中最新的消息
- Lag:表示消费者当前偏移量与HW之间的差距,消费者lag越小,表示越接近实时。 如下图:
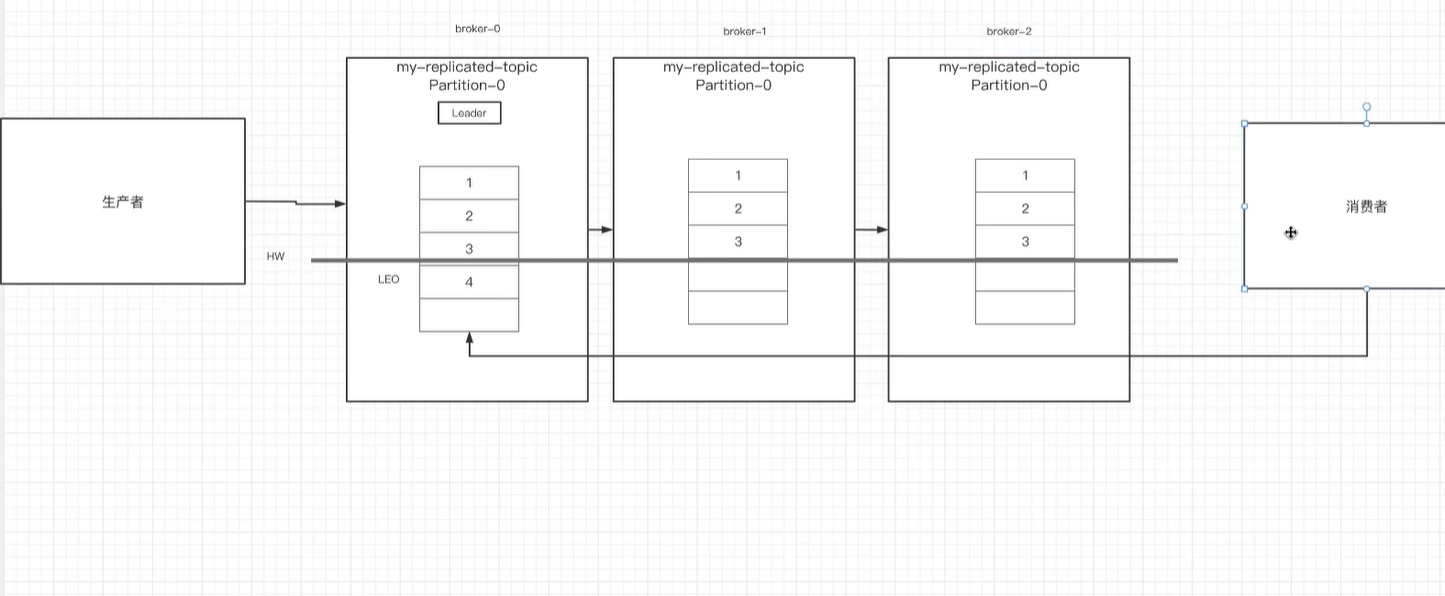
此时有三个broker,其中leader中最后接收到的消息为4,但是并未和其他两个同步,其他同步最新的是3.
这样HW就是3,LEO就是4,lag就是1. 消费者是无法消费到4的,需要等4同步到剩下两个broker的时候才可以。
这样的好处就是防止消息丢失。保障消息的可靠性。
zookeeper关系
2.8以下,kafka强依赖zookeeper,3.0版本之后,kafka剔除了zookeeper,我们谈谈2.8以下zookeeper和kafka的作用吧。
其实看到现在,你应该是有些许概念的,kafka中zookeeper的职责和任务,如下:
broker管理 ZooKeeper 负责跟踪和管理 Kafka 集群中的各个 Broker 节点。它维护了关于每个 Broker 的元数据,包括其主机名、端口等信息。
topic和分区管理
ZooKeeper 维护了 Kafka 集群中所有 Topic 和分区的元数据。这包括了 Topic 的配置信息、分区的 Leader 信息、ISR(In-Sync Replicas)信息等。
Leader选举
在 Kafka 集群中,每个分区都有一个 Leader 负责处理读写请求。ZooKeeper 参与 Leader 的选举过程,确保每个分区的 Leader 在集群中的正确选择。
费者组协调:
ZooKeeper 用于协调消费者组的成员和管理它们的偏移量。消费者组中的消费者通过 ZooKeeper 发现和协调彼此的消费状态。
实战配置
我们的配置,基于go语言的github.com/IBM/sarama包,因为 github.com/Shopify/sarama 这个包已经移植了。
生产者ACK配置
这里设计到一个同步和异步的概念,也就是你发送完消息,是否需要等待返回信息才能执行下一步,还是直接丢到协程、线程中去发送消息,不阻塞主线程,一般来说ACK配置都是针对于同步的,也就是阻塞kafka服务给你的回调,是否发送成功还是失败。在生产者获得回调的ack之前,会一直阻塞,那么ACK什么时候返回,有哪些配置呢?如下:
- acks=0: 生产者在成功写入消息到 socket 就会认为消息已发送成功,不等待任何来自服务器的响应。这是最快的方式,但也是最不可靠的,因为生产者不会知道是否有错误发生。
- acks=1: 生产者在将消息写入主题的分区 leader 后,会等待来自 leader 的确认。这提供了一定程度的可靠性,但仍然可能丢失消息,因为 leader 确认后可能会发生错误,而生产者无法得知。
- acks=all(或 acks=-1): 生产者在所有同步副本接收到消息并确认后,才认为消息发送成功。这是最可靠的设置,但也是最慢的,因为需要等待所有副本的确认。
go语言代码如:
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll // 设置为 all,即 acks=all
//config.Producer.RequiredAcks = sarama.NoResponse // 设置ack为0
//config.Producer.RequiredAcks = sarama.WaitForLocal // 设置ack为1
这种看业务需求来定,如果是强关联的,建议设置为all,然后在error中去重试、告警、存日志等等。
partition, offset, err := producer.SendMessage(message)
if err != nil {
// todo something
}
生产者发送缓冲区
无论是同步还是异步,生产者发送消息的时候,难道是来一条发送一条吗?比如我需要连续发送10w条消息,那岂不是要跟kafka建立10w次会话?这也太浪费性能了吧,所以有一个缓冲区的概念。
Kafka 生产者(Producer)在发送消息时通常会使用缓冲区来提高性能。缓冲区用于暂存待发送的消息,一旦缓冲区达到一定大小或者一定时间间隔,就会触发批量发送,将消息批量提交到 Kafka Broker。这种机制可以减少网络开销,提高吞吐量。
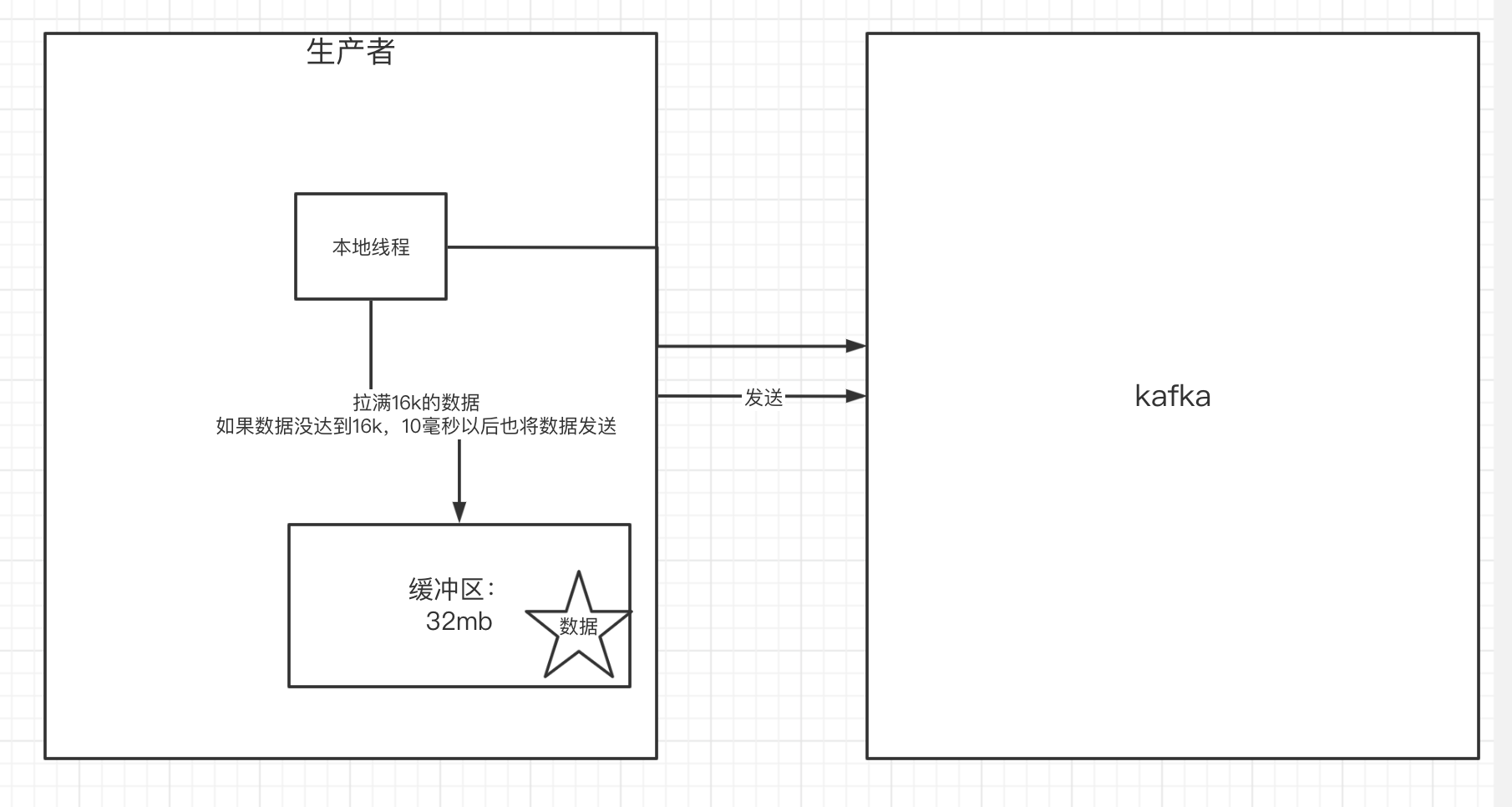
kafka有个默认的缓冲区为32m,但是并非是把数据放满32m了才发送数据,而是有一个有一个本地的线程,每次从缓冲区里面拉16k的数据,拉满16k的消息后,就会去发送数据,如果数据没到达16k,则10ms之后也会把数据发送。
go语言配置代码如:
// 设置异步发送的参数
config.Producer.Flush.Bytes = 32 * 1024 * 1024 // 设置本地缓冲区的大小为 32MB
config.Producer.Flush.Messages = 16 * 1024 // 设置每次拉取的数据大小为 16KB
config.Producer.Flush.Frequency = 10 * time.Millisecond // 设置缓冲区触发发送的时间间隔为 10ms
producer, err := sarama.NewSyncProducer([]string{"your-kafka-broker:9092"}, config)
生产者指定分区
我们之前也说过,可以指定分区进行生产消息,消费者也可以指定分区进行消费消息,如果没有指定,生产者会采用轮询、hash、随机的方式来选择目标分区。如果有的话,则指定发送到分区。
message := &sarama.ProducerMessage{
Topic: "your-topic",
Value: sarama.StringEncoder("Hello, Kafka!"),
// 指定消息发送到分区 0
Partition: 0,
}
消费指定分区
正常来说,一个消费者可以同时监听多个topic,但是基于单一职责原则,一般不建议,且我在sarama里面也没找到具体的使用方法,我们就不讨论了。
消费指定分区,我们之前demo就是:
partition := int32(0)
// 指定监听某个分区
partitionConsumer, err := consumer.ConsumePartition(topic, partition, sarama.OffsetOldest)
但如果要监听消费全部分区呢?
我们可以这样做,先获取到当前topic下所有的Partition,然后再for循环分别监听:
partitions,_:=consumer.Partitions(topic)
for _, partition := range partitions {
partitionConsumer, err := consumer.ConsumePartition(topic, partition, sarama.OffsetOldest)
}
分组消费
func main() {
config := sarama.NewConfig()
groupID := "your-consumer-group"
topics := []string{"your-topic"}
// 创建消费者组
consumerGroup, err := sarama.NewConsumerGroup([]string{"your-kafka-broker:9092"}, groupID, config)
if err != nil {
log.Fatal(err)
}
defer consumerGroup.Close()
// 处理每个分区上的消息
handler := ConsumerGroupHandler{}
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
wg := &sync.WaitGroup{}
// 启动消费者组协程
go func() {
defer wg.Done()
for {
if err := consumerGroup.Consume(ctx, topics, handler); err != nil {
log.Fatal(err)
}
// Check for context cancellation to exit the loop
if ctx.Err() != nil {
return
}
}
}()
// 等待信号中断
signals := make(chan os.Signal, 1)
signal.Notify(signals, os.Interrupt)
<-signals
// 发送取消信号
cancel()
// 等待消费者组协程结束
wg.Wait()
}
// ConsumerGroupHandler 实现 sarama.ConsumerGroupHandler 接口
type ConsumerGroupHandler struct{}
// Setup 在消费者组启动时调用
func (h ConsumerGroupHandler) Setup(session sarama.ConsumerGroupSession) error {
return nil
}
// Cleanup 在消费者组退出时调用
func (h ConsumerGroupHandler) Cleanup(session sarama.ConsumerGroupSession) error {
return nil
}
// ConsumeClaim 处理每个分区上的消息
func (h ConsumerGroupHandler) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
log.Printf("Received message from topic %s, partition %d, offset %d: %s\n", msg.Topic, msg.Partition, msg.Offset, string(msg.Value))
// 在这里处理消息的逻辑
session.MarkMessage(msg, "")
}
return nil
}
消费offset自动提交和手动提交
在kafka消费的时候,有两种提交方式,一种是自动提交,一种是手动提交。
可以这么理解,消息存在broker中的topic下的队列里面,当Consumer去消费消息的时候,如果是自己poll消费后,直接提交offset的,就是自动提交,如果是消息poll后,把消息传到了客户端处理消息后,再提交offset,就是手动提交。
我们可以通过参数来设置:
自动提交
config := sarama.NewConfig() config.Consumer.Offsets.AutoCommit.Enable = true config.Consumer.Offsets.AutoCommit.Interval = 1 * time.Second // 设置提交的时间间隔消费者在消费消息的同时,会自动提交当前成功处理的最新 Offset。这是默认行为,但有一些潜在的风险。如果在消息处理后发生错误,导致消息未能正确处理,那么已经提交的 Offset 将会导致消息丢失或重复消费。
手动提交
type ConsumerGroupHandler struct{} func (h ConsumerGroupHandler) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error { for msg := range claim.Messages() { log.Printf("Received message: %s\n", string(msg.Value)) // 在这里处理消息的逻辑 // 手动提交 Offset session.MarkMessage(msg, "") } return nil }消费者可以选择在成功处理消息后手动提交 Offset。这样可以更精确地控制 Offset 的提交时机,以确保消息正确处理后再提交 Offset。
消费者poll消息的过程
在 Kafka 中,消费者通过进行轮询(poll)操作来拉取消息。轮询是一个阻塞操作,它用于从 Kafka 服务器获取新的消息记录。消费者会定期发起轮询请求,检查主题的分区是否有新的消息可供消费。
func ConsumeMessages1(topic string) {
config := sarama.NewConfig()
config.Consumer.Return.Errors = true
consumer, err := sarama.NewConsumer([]string{"124.223.47.250:9092"}, config)
if err != nil {
log.Fatal("Error creating consumer:", err)
}
defer consumer.Close()
partition := int32(0)
// 指定监听某个分区
partitionConsumer, err := consumer.ConsumePartition(topic, partition, sarama.OffsetOldest)
if err != nil {
log.Fatal("Error creating partition consumer:", err)
}
defer partitionConsumer.Close()
signals := make(chan os.Signal, 1)
signal.Notify(signals, os.Interrupt)
var wg sync.WaitGroup
ConsumerLoop:
for {
select {
case msg := <-partitionConsumer.Messages():
log.Printf("Consumed message from partition %d at offset %d: %s\n", msg.Partition, msg.Offset, string(msg.Value))
case err := <-partitionConsumer.Errors():
log.Println("Error:", err)
case <-signals:
break ConsumerLoop
}
}
wg.Wait()
}
consumerGroup.Consume 会定期进行轮询,从 Kafka 获取新的消息。在 ConsumerGroupHandler 的 ConsumeClaim 方法中处理每个分区上的消息。如果没有新的消息,轮询会一直阻塞,直到有新的消息到达或者超时。
优化
如何防止消息丢失
这问题的核心,就是发送的消息,必须要消费到,要做到5个9,就是99.999%。
消息分为生产者、kafka、消费者。我们要分别讨论:
生产者
我们要做到同步发送,且ack设置为1或者是all,可以防止消息丢失。同步也就是返回ack之后才会做业务,不然就重试。
kafka服务
确保消息在发送到系统后被持久化存储,意味着写入到硬盘中。而且多增加几个broker,采用多副本机制,确保消息被复制到多个节点,即使一个节点故障也能从其他节点获取。
消费者
把offset的自动提交改为手动提交,确保业务处理完成后,才修改offset的值,就是相当于确认机制。
其余的,还需要设立监控机制,定期检查系统的状态,设置报警机制,即使发现潜在的问题,可以包括生产、消费、存储空间等等。也要做好容错机制,当系统某个节点故障时,即使转移等等。
如何防止消息的重复消费
比如生产者开启了重试的机制,且发送一条消息M到kafka,kafka已经收到,但是回ACK的时候由于抖动,导致生产者没有收到ACK,此时生产者重试机制启动,又会发送M到kafka,此时kafka里面就会有两个M了,等消费者去消费的时候,就会消费到两个M。如何防止?
如果从生产方解决的话,就是关闭重试机制,但是关闭后,可靠性得不到保障了,因噎废食,我们还是从消费方解决吧。
首先消费方都应该做幂等性操作。
确保处理操作是幂等的,即无论处理多少次,最终的结果都是一样的,这样即使消息被重复处理,也不会影响系统状态,设置幂等性操作是一种通用的设计原则,适用于各种分布式系统。
唯一标识
为每条消息加一个唯一标识符,且消费后把唯一标识符记录下来,每次消费前去唯一标识符表里面查看,当前消息是否被处理了。
使用联合主键
比如把id和时间或者uuid等等作为联合主键,第一次M过来的时候和第二次M过来的时候的数据,联合主键肯定是一样的,这样第二次就不能保存了。
消息TTL
设置消息的TTL,确保消息在一定时间内被消费,避免长时间未被处理的消息重复消费的问题
kafka做到顺序消费
我们知道,在发送消息的时候,可以通过设置指定发送的分区,所以,如果一个分区如果被多个消费者消费,那么很难保证顺序消费的。
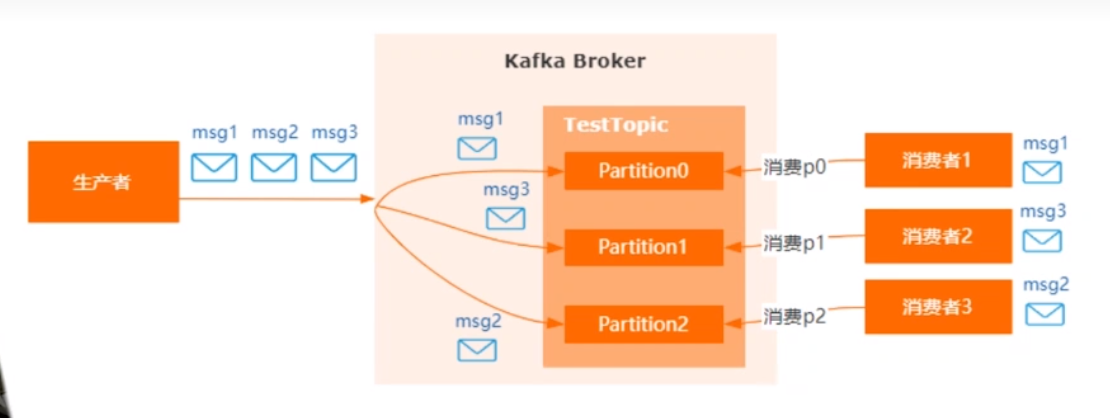
做到顺序消费,还是得从生产者和消费者两边确定:
生产者
使用同步的方式发送,并且设定消息发送到指定的分区中,然后把ack设置成非0的,确保每条消息都发送成功,都是同步方式发送,确保每条消息发送都是有顺序的。
消费者
确保只有一个消费者/消费组去消费消息,不会出现多个消费者并发处理消息的情况,所以做到顺序的话可能会牺牲掉一部分性能
我们还可以在消息中添加序号,然后消费的时候把序号记录,并且下一次消费的时候拿出来对比,看看序号是否是连续性等等。
当然,kafka顺序消费的话,可能使用场景不多,因为会牺牲掉部分性能
如何解决消息积压问题
有这么一个场景,比如生产者高并发,一下子发送了好几千万条消息,但是消费者节点不太好,处理消息的能力不太够,所以在kafka中可能会堆积消息,等待被消费,当然,这些消息都是存在kafka本地的。如下图:
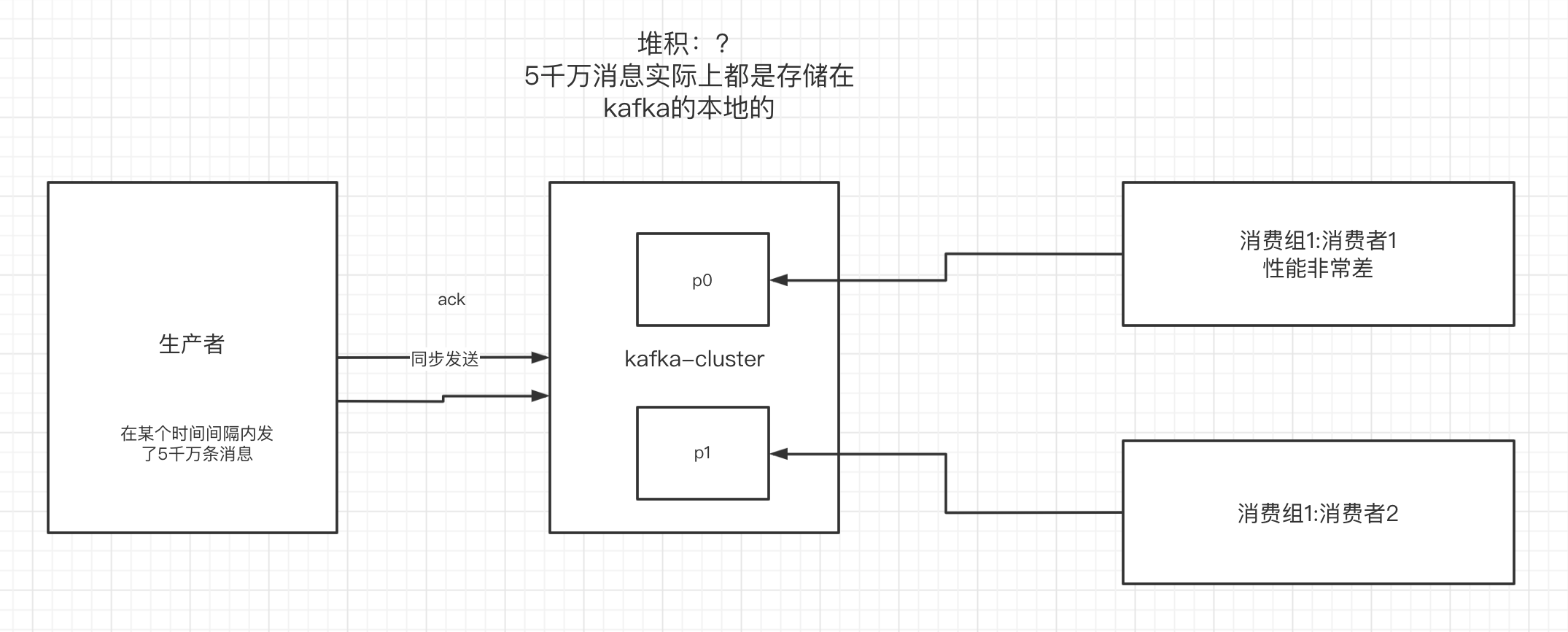
消费者性能太差了,消费速度远远赶不上生产的速度,导致kafka中有大量的数据没有被消费,随着数据的堆积越来越多,消费者寻址性能会越来越差,最后导致整个kafka对外提供服务的性能越来越差,最后可能造成服务雪崩。所以我们解决堆积的问题,还是得从如下入手:
- 可以使用多协程来进行消费消息,充分利用机器的性能进行消费消息。
- 调整消息处理逻辑:优化消费端的处理逻辑,确保消费者能够更快速的处理每条消息,比如优化算法、并发处理、异步处理等等。
- 创建多个消费组,多个消费组,部署到其他机器上面,水平扩展,提高消息处理速度。
- 硬件升级,比如增加内存、磁盘,CPU升级等等。
- 监控和报警:设置监控机制,实时监测消息系统的状态,比如消息队列长度、消费者处理速度等等,发生积压问题及时报警,以便快速响应和处理。
- 限流和流量控制:这是生产方的优化,生产下实现限流,防止瞬时流量激增导致积压,比如通过令牌桶等等来控制。
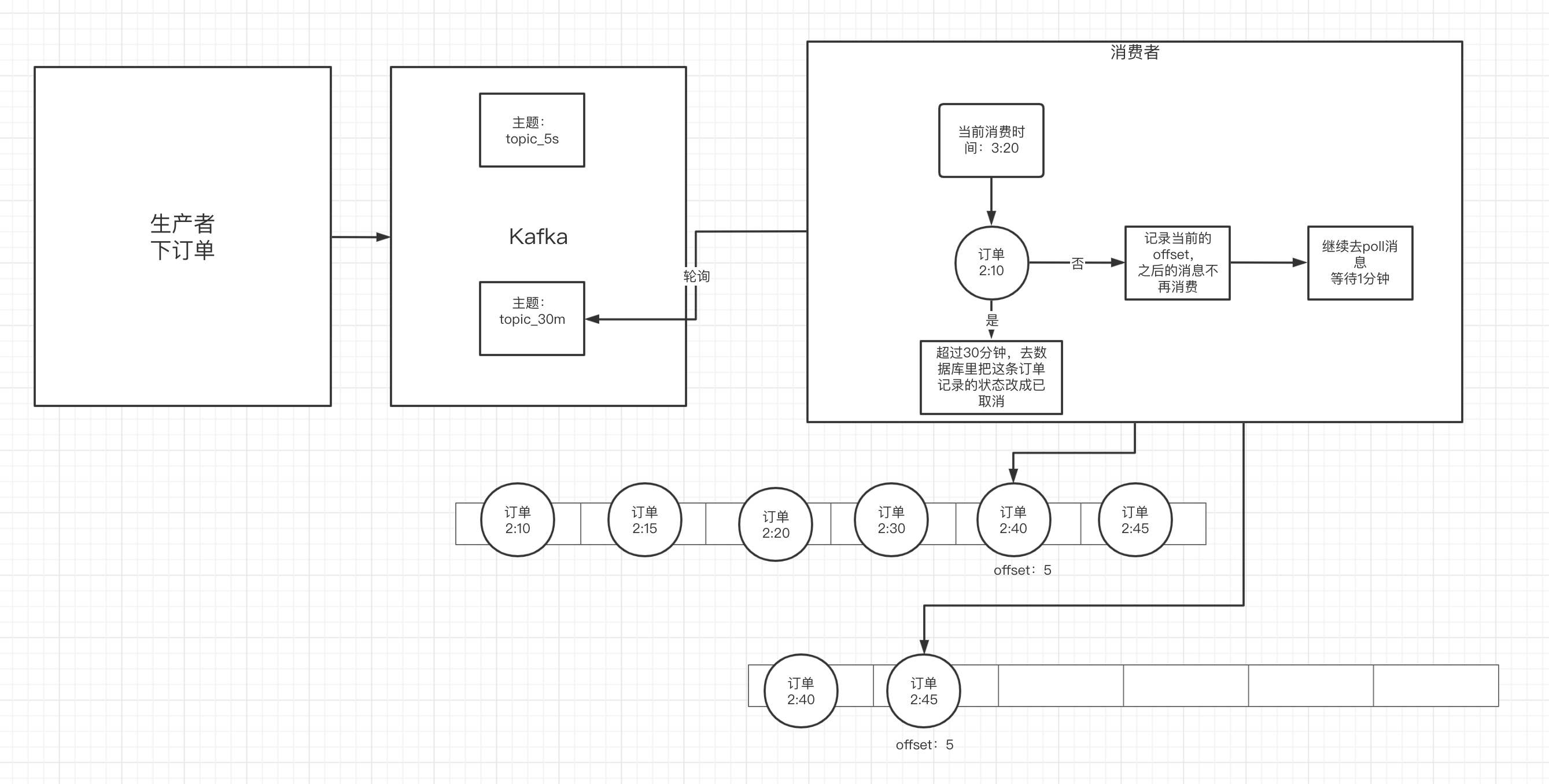
延迟队列
比如超过半个小时未付款,订单自动失效这个场景,总不能起一个定时任务,每分钟去轮询库吧。
其实使用kafka,比较麻烦,如果是rbmq的话,有对应的插件,或者通过死信会更好一点,但是kafka也是可以处理的。
可以这么处理,我们先根据业务,建立多个topic来处理不同的业务,比如建立topic_5s表示延迟5s、topic_1min表示延迟1分钟,topic_30min表示延迟30分钟。 然后有多个消费者分别对应不同的topic,当然消息里面需要带上当前发送消息的时间。
消费的,先把消息解析下,看下发送的时间和当前系统的时间对比,比如延迟30分钟,就看看是否超过30分钟了,如果大于等于30分钟,就接着做业务逻辑。如果小于三十分钟,此时就记录下offset,然后下一次消费的时候就从当先这个offset中进行消费,此时可以让线程进行休眠,休眠的时长应该是根据延迟的时长来,比如30分钟,就可以休眠1分钟,如果是5s,估计就只能休眠1s。
这样周而复始、轮询,实现简单,不过方案略扯淡。
kafka-eagle监控平台
Kafka Eagle(KafkaEagle)是一个开源的 Kafka 监控和管理工具。它提供了一套 Web 界面,用于监控和管理 Apache Kafka 集群。以下是 Kafka Eagle 的一些主要特点和功能:
实时监控
提供实时的 Kafka 集群监控,包括各个 Broker 的状态、Topic 的状态、分区的状态等信息。用户可以通过 Web 界面实时查看 Kafka 集群的运行情况。
性能指标
显示 Kafka 集群的性能指标,如吞吐量、延迟等。可以帮助用户了解集群的性能状况。
消费者监控
支持监控 Kafka 消费者的状态,包括消费者组的健康状况、消费速率、消费进度等信息。
Topic 和分区管理
提供方便的界面来管理 Kafka 的 Topic 和分区,包括创建、删除、修改 Topic 以及调整分区等操作。
告警和通知
支持设置告警规则,当集群或 Topic 出现异常时,可以通过邮件、短信等方式进行通知。
历史数据查询
提供历史数据查询功能,用户可以查询过去一段时间内的集群运行情况。
权限管理
支持基于角色的权限管理,可以定义不同用户的权限,确保安全性。
跨集群监控
支持监控多个 Kafka 集群,方便用户同时管理多个集群。
Web 界面
使用 Web 界面,使得用户可以通过浏览器轻松访问和操作 Kafka Eagle。
搭建
安装jdk,并配置好环境变量
解压kafka-eagle压缩包
tar -zxvf kafka-eagle-3.0.tar.gz配置eagle环境变量
export KE_HOME=/usr/local/kafka-eagle-3.0/efak-web-3.0.1 export PATH=$PATH:$KE_HOME/bin修改eagle配置文件,一般在安装目录的conf/system-config.properties文件
cluster1.zk.list=124.223.47.250:2182 #配置自己的zk目录
######################################
# kafka mysql jdbc driver address
######################################
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username= #配置username
efak.password= #配置password
- 启动、进入bin下面
./ke.sh start看到如下就表示成功安装搭建了,然后使用你的ip:8084/ke就可以通过账号admin访问了。
[2024-01-19 22:46:05] INFO: [Job done!]
Welcome to
______ ______ ___ __ __
/ ____/ / ____/ / | / //_/
/ __/ / /_ / /| | / ,<
/ /___ / __/ / ___ | / /| |
/_____/ /_/ /_/ |_|/_/ |_|
( Eagle For Apache Kafka® )
Version v3.0.1 -- Copyright 2016-2022
*******************************************************************
* EFAK Service has started success.
* Welcome, Now you can visit 'http://127.0.0.1:8048'
* Account:admin ,Password:123456

