
DDD诞生许久了,而且最近微服务的兴起,也带动DDD架构的火爆,今天我们就来谈谈DDD架构设计方面的。
软件核心的复杂性,并不是来源于庞大的软件体量或者复杂的业务流程,而是来自于项目长期迭代过程中不断冒出超出当初设计之外的不确定性。
很多人都在谈DDD,但是DDD会适合哪些系统架构呢?我们要不要用DDD呢?会有哪些概念呢?架构如何?等等,在本文都可以解决。
DDD简介
04年就提出来了,只是15年微服务火起来之后,才进入大家的视野。
DDD:Domain Driven Design,领域驱动设计,有很多关于这方面的书籍,主标题都是如此,区别的都是在副标题的不同。
我们在软件开发的时候,是不会经常会面临着,随着业务越来越多,系统越来越复杂,可扩展性也来越不强,开发效率越来越低等等,而DDD的思想,就是让这些复杂性保持年轻,项目越复杂,使用DDD的收益越大。
不关乎技术,产品经理也应当了解DDD的设计方法,让产品和技术都拥有者共同的语言。 使用DDD设计思想,让技术主动理解业务,业务如何运行,软件如何构建。
与传统MVC架构区别
MVC架构就挺好的,为什么要冒出来一个DDD,它有何优势呢?
当然,随着现在业务不管扩大,MVC架构下不可避免出现大泥球结构,严重影响了系统灵活性。项目初期还好,后面业务叠加,一旦涉及到某个核心功能模块修改,则产生毁灭般的打击,只能重构,但是重构其实是没有业务价值的。
比如电商项目,前期启动好拆分,把用户、订单、商品等等分别拆分成一个个微服务,这时候好拆分,但是如果一开始没有拆分,到了后期,就根本没办法拆分,因为各功能模块耦合太强了。 但是如果通过DDD 领域化的思想进行设计,拆分就是分分钟的事情。因为DDD在开始设计的时候,就把项目看成是领域和领域之间的组合,在单体下就是一个个组合,所以如果某个领域过大,可以立马拆分为微服务。
当然,我们刚刚一直在提领域,所以DDD是以领域划分为设计基础的
DDD特点
领域
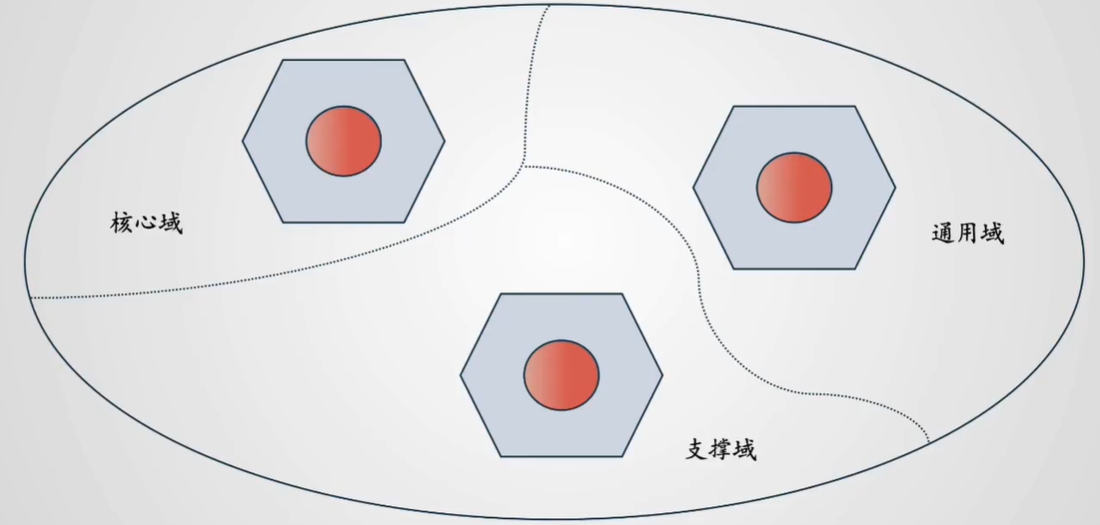
所以,我们划分成核心域、通用域和支撑域。这些概念,我们先知道就可以了。那么,问题来了,什么是领域呢?
我们一般说的领域,比如go语言领域,是一个领域,java也是一个领域。我们换个角度看看,领域是否可以理解为边界?比如go语言是一个领域,是不是为了把go和java划分开,这是一个边界,比如软件和硬件等等。
好,边界我们知道了,我们在开发的时候也是不断划分边界的。比如我们传统的MVC模型,就会有controller层,作为接收接口请求,然后在service层作为业务处理,然后在model层做数据模型计算等等。比如userController就是用户管理功能,orderController就是订单管理功能,这两个Controller就是两个逻辑分层,河水不犯井水,这些都是边界。而有了边界,我们就可以化成领域。
但实际中并非如此简单,比如我们在service层,有个userService,但是我们在orderService中,也会用到userService方面的信息。大概率我们在开发中都是直接在orderService中引用userService。所以我们在虽然有边界,但是并未坚守。也就是虽然有划分,但是并未形成领域。
所以领域并非那么简单,既需要再业务逻辑中划分边界,又能够在业务中整合成一个整体,既需要独立,又需要合作,有太多的细节需要处理。而DDD,就使用这些思想,指导我们如何划分。如何把业务落地。
所以,领域目前为止,是还没有一个可定义化的概念,只可意会不可言传。我们接着往下看。
通用语言为建设核心
在DDD中,不断的强调以通用语言为建设核心,那么,什么是通用语言呢?简单来说,就是产品经理、开发人员、测试人员等等各个工作职能,都是可以有一套沟通的语言,不然就会会错意,鸡同鸭讲。如下图,客户想要一个秋千,但是各个职能对于秋千的理解各不相同。
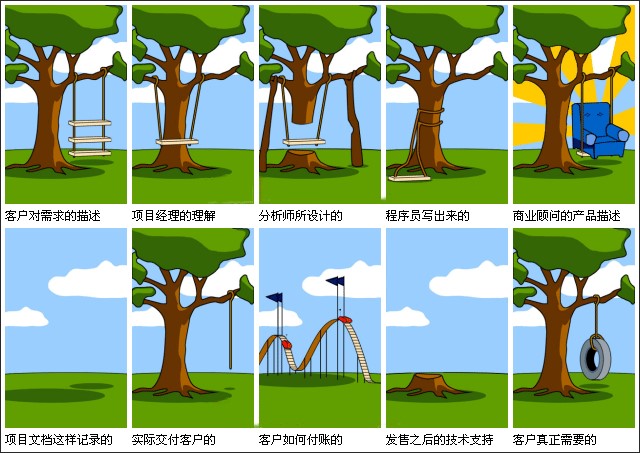
而DDD强调,在每个项目中,都强调一个通用的语言。
抽象概念
DDD有个特点是,以抽象概念为开发模式,其实很多书籍,或者其他文章介绍DDD,一开始都是上抽象概念,比如实体、聚合根、值对象等等,有的还好,有的一脸懵逼,比如聚合根是什么鬼?不过不急,后面慢慢介绍,这些东西先混个眼熟吧。
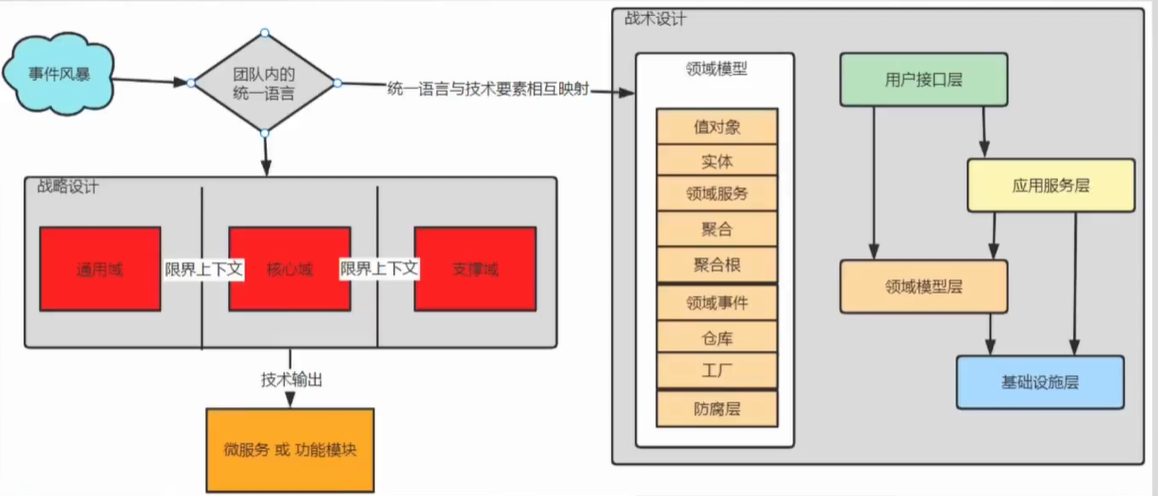
四层架构
DDD还有一个极为明显的特征,就是以四层架构为基本思想,下图就是MVC三层架构,和DDD四层架构的概览图。当然,也是先混个概念。
如果之前接触过,肯定见过这四层,接口层、应用层、领域层、基础层。
解决系统老化问题
系统如同人,随着年龄增大,随着阅历增多,随着压力变大,生理机能不行,身体变得臃肿,脑子也会不好使了。系统也是,随着需求、业务增加,系统相对臃肿。在之前MVC下,开发时间长的项目,一般都会有如下特点:
- 沟通难:新需求越来越难,迭代越来越久,系统越来越复杂,需求都不知道怎么提。
- 开发难:随着人员更迭,各人员的编码习惯、技能不一样,代码也难以看懂,又不敢轻易重构。
- 测试难:没办法单测,简单的小需求都需要跑大量回归测试,累死测试,只能堆时间。
- 创新难:外面新技术越来越多,这破系统没时间重构,没办法使用新技术,越拖越烂。
哎,如果有这种困惑,DDD有助于解决系统老化问题。
初识DDD
引子
我们直接来一个案例吧,就一个简简单单的需求:用户购买商品后,向商家进行支付。
按照我们目前的思路,我们写产品设计或者开发文档的时候,是不是分为如下几步就完成了。
1:从数据库查出用户和商户的账户信息
2:调用风控系统的微服务,进行风险评估
3:实现转入转出操作,计算双方的金额变化,保存到数据库中
4:发送交易情况给kafka,进行后续审计和风控
那么开发人员也是刷刷刷写完了。
func PaymentController() {
pay:=PayService{}
pay.pay()
}
type Result struct {
}
// PayServiceContracts 定义支付服务的接口
type PayServiceContracts interface {
pay(userId, merchantAccount string, amount float64) (*Result,error)
}
type PayService struct {
}
func (p PayService) pay(userId, merchantAccount string, amount float64) (*Result, error) {
// 1:获取数据相关
clientDO := accountDao.selectByUserId(userID)
merchantDO := accountDAO.selectByAccountNumber(merchantAccount)
// 2:业务参数校验
if amount > clientDO.getAvailable() {
return nil, errors.New("no money error")
}
// 3:调用风控微服务
riskCode, err := riskCheckService.checkPayment()
if err != nil {
return nil, err
}
// 4:检查合法性
if "0000" != riskCode {
return nil, errors.New("invalid operate error")
}
// 5:计算新值,更新字段
newSource := clientDO.getAvaliable().subtract(amount) // 客户端减钱
merchantDO.getAvailabel().add(amount) // 商户加钱
clientDo.setAvailble(newSource) // 客户设置新余额
merchantDo.setAvailble(newSource) // 商户设置新余额
// 6:更新到数据库
accountDAO.update(clientDO)
accountDao.update(merchantDo)
// 7:发送审计消息
message := userId + "," + "...."
kafkaTemplate.send(TOPIC_AUDIT_LOG, message)
return nil, nil
}
刷刷刷的1-7步写完,收工回家。 你是不是这么开发的?
但是,会留下很多坑,也是系统老化的起源,如上面代码的一些坏味道的实现:
- 问题1:可维护性差,大量的第三方代码影响核心代码,比如风控、kafka引用,如果风控系统做了改变,使用了success作为成功,而不是0000,那需要修改核心代码。这本身和转账业务是没有任何关系的。
- 可扩展性差,业务逻辑和存储,相互依赖,无法复用。比如后面另外有一个转账流程,也想复用,那么在不修改代码的情况下,没有复用性。除了1-7的步骤有参考,其余没有参考价值
- 可测试性差,庞大事务脚本与基础设施强耦合,无法进行单测。如果我们要测这么一段逻辑,所有的服务都需要部署好,比如DB、比如微服务、比如kafka。
所以,如上代码,虽然写起来很爽,但是经过几次迭代后,这块业务代码就是一个可怕的黑洞。如果换一个人接收,需要加一个缓存进去,这块代码,你敢动吗?你会不会骂娘?
那么如何解决呢? 咱们抛开DDD,正常有点开发经验的,都知道 高内聚、低耦合吧。也知道三大设计原则吧:
- 单一职责原则: 一个类只负责单一职责,另一种理解也是一个类应该只有一个引起他变化的原因。也就是我们上面的pay方法,只有我们的业务流程发生变化,才会改动,什么风控、校验、kafka改变,都不应该动这快业务。
- 开发封闭原则:也就是对扩展开放,对修改封闭。
- 依赖反转原则:程序之间应该只依赖于抽象接口,而不要依赖于具体实现。这是由于基于接口,可以更好的修改。上述代码虽然也是面向了接口,实现了PayServiceContracts的接口,但是这种扩展,没有任何意义。因为无论怎样付款,付款的流程都是一样的,最基本就是商户入账,客户出账。所以这个流程是没有可扩展的空间。
接下来,我们就进入DDD的改造阶段。实打实的改出来。
DDD改造
我们通过DDD改造之后的代码,然后由各位看官自行评估,看看DDD是否可行。
第一刀,改造数据库
抽象数据存储层
首先,我们把Account实体,把账号下面的转入、转出操作,放入里面。
type Account struct {
id string
accountNumber int64
available float64
}
// 转入操作
func (a *Account) withdraw(money float64) {
a.available = a.available + money
}
// 转出操作
func (a *Account) deposit(money float64) error {
if a.available < money {
return errors.New("insufficient money error")
}
a.available = a.available - money
return nil
}
这种设计,就是充血模型。如何理解? 看下面
贫血模型:贫血失忆症,我们定义实体,实际是承载业务的,但最后属性很多,业务反而不明显。
比如Account,就是承载转账、充值、支付业务等等,而设计这些实体,我们在开发中习惯将各种各样的属性,都放在一个实体里面,久而久之,就会发现我这个实体承载的哪些业务,是看不出来的,要一个个到server上面去翻。也就是我这个实体是为了业务设计,反而我的实体上面是看不到业务了。这就失忆,违反了我们的初衷了。
充血模型:也就是将实体属性,和引起属性变化的方法写在一起。
比如Account里面,把钱的属性,和引起钱的变化(转入、转出)写在一块,这样就知道Account承载了什么业务,也就是账户的转入、转出的操作。也就可以看到他承载的业务了。
那数据库操作如何呢?我要查询,我要更新Account相关的,怎办呢?
DDD思想,要求我们通过一层仓库层来干这些脏活累活,当然,高内聚低耦合的原则,要先定一个接口,如:
type AccountRepositoryContracts interface {
findByID(id string) *Account
findByAccountNumber(accountNumber int64) *Account
save(account Account)
}
type AccountRepository struct {
accountDao AccountDao
accountBuilder AccountBuilder
}
func (a *AccountRepository) findById(id string) *Account {
return a.accountDao.selectById(id)
}
func (a *AccountRepository) findByAccountNumber(accountNumber string) *Account {
return a.accountDao.selectByAccountNumber(accountNumber)
}
func (a *AccountRepository) save(account Account) {
accountDO:=a.accountBuilder.fromAccount(account) // 工厂模式,组装accountDO
accountBuilder.toAccount(accountDO)
}
也就是我们通过AccountRepository层,和数据库打交道,也就是数据库如何处理,如何查数据,如何存储数据,和我们的业务是无关的。这些细节,全部封装在这一层。这样的好处,就是后续我们要修改存储方式,比如之前是mysql,换成redis存储,对于业务来说不用关心,我另外起一个结构体,实现AccountRepositoryContracts接口,把Dao缓存redis即可。对于应用来说不用关心了,直接调用接口即可查询。
这一层设计,在DDD中有个概念进行固化,就叫做 仓库。 DDD认为实体的所有管理,都应当交由仓库来管理,在仓库下做一些具体的实现。
在我们传统的开发下,一般都是由数据库开始,先把所有表设计出来,UML图出来后,设计差不多了,UML对应实体,实体组装业务,那整个架构也就完事了,是一种自底向上的设计思路。但是,这样的问题在于,我们的逻辑和数据并非一一对应,数据库的表达能力是有限的,比如我们设计实体的时候,想当然的会有一些对应关系,比如一对一、一对多、多对一等等的关系。但是落实到数据库中,这种表达就有限的,比如A:B是一个多对多关系,在实体、逻辑层面实现是好实现的,比如:
type A struct {
b []B
}
type B struct {
a []A
}
但是,这种多对多,落地到数据库中,就很别扭了,我们只能引入第三张表C,来作为A和B的对应关系,而且维护起来相当麻烦。这跟我们的逻辑,是不一致的。甚至有一些比如继承、多态等等,在数据库中根本就表达不出来。
所以逻辑设计和数据库表之间是有差距的,但是通过组装实体之后,就可以设计了,这也是为什么要使用accountBuilder.fromAccount(account)来组装的原因。我们实体是直接面向的业务。
DDD认为,业务优先的思想,所有的设计都是面向业务的,至于技术实现是延后的。
所以,通过仓库层和工厂的整体设计后,未来需要和数据交互,就不需要关系实体了,直接关注Account的实体即可。下面具体的实现,由实现类和一些主键去负责了。如果不用mysql了,缓存redis、mogodb或者其他的,我都不关心了。这就摆脱了数据库的限制了。
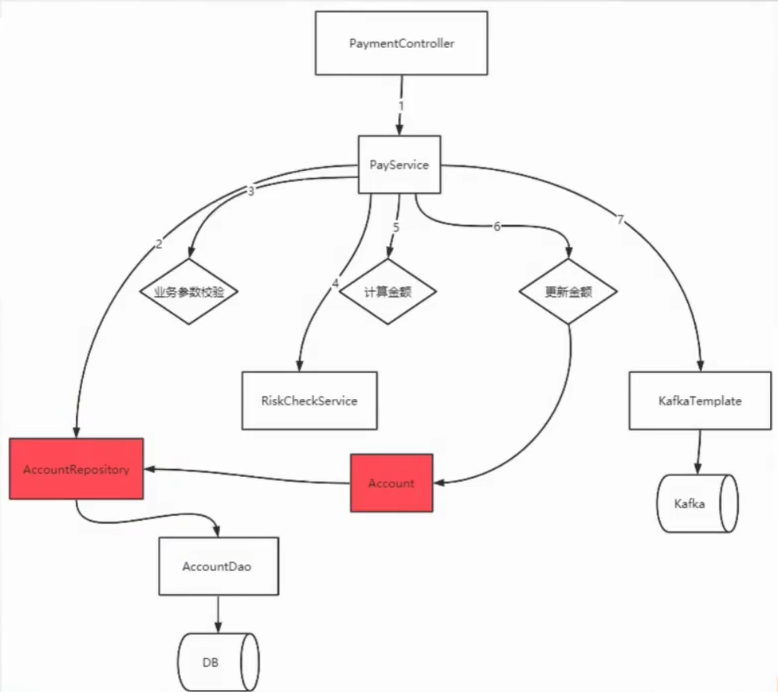
抽象第三方服务
比如风控微服务,这也是一个雷,要记住,第三方服务都是雷。
但是我们也可以抽象出接口,提供实现类,然后实现实现类,具体在接口中,是通过什么进行交互,上层不管。
type BusiSafeContracts interface {
checkBusi() *Result
}
type BusiSafeService struct {
riskChkService RiskChkService
}
func (b *BusiSafeService) checkBusi() *Result {
riskCode := b.riskChkService.checkPayment()
if "0000" == reskCode.getCode() {
return &Result{}.SUSSESS
}
return nil
}
这样,就是与第三方交互的过程,封装在这里。未来出现任何问题,可以在此方法中进行修改。对业务层面只是跟接口打交道,与具体实现无关。
而,这种方式,在DDD中也是有概念,进行固化下来的。叫做:防腐层。构建防腐层,隔离外部服务,众人皆醉我独醒
也就是哪怕你外围的系统,第三方做的很垃圾,但是对我当前系统来说,是没有任何影响的。
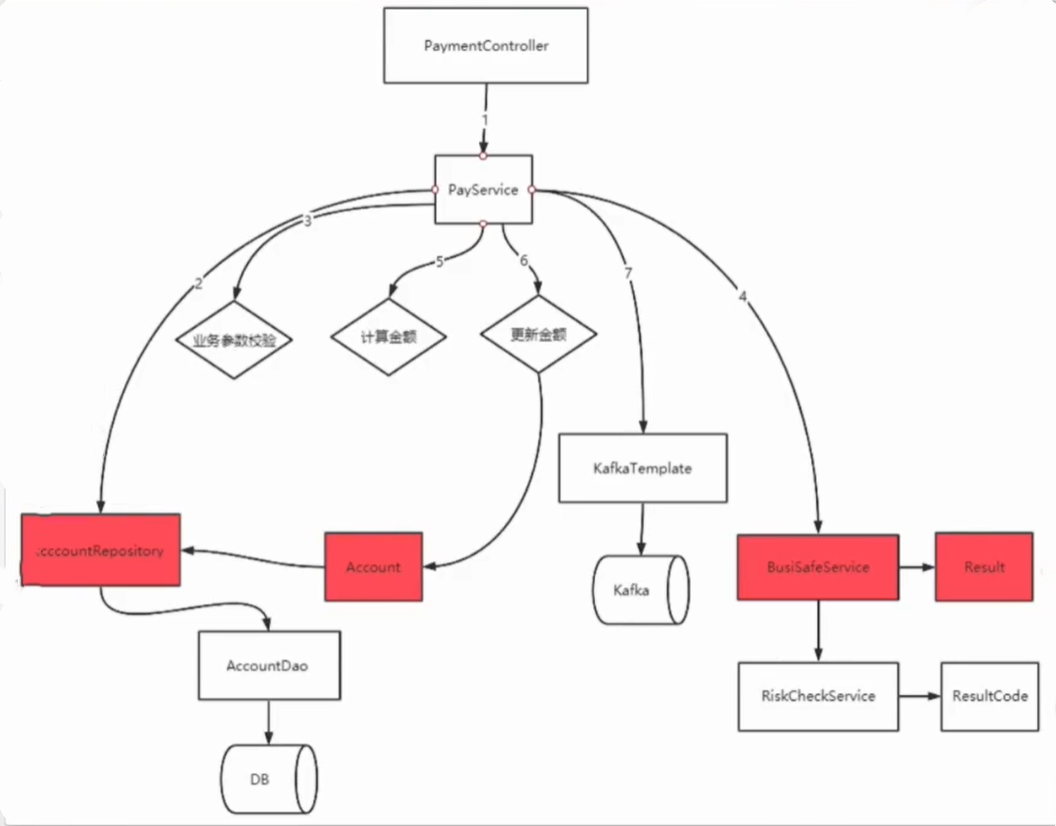
此时,我们第三方服务也修改完成。
抽象中间件
终于到了中间件环节了,kafka这玩意看着就不舒服,万一挂了怎么办?我们继续使用防腐层手段,来改完kafka审计相关。
type AuditMessage struct {
UserID string
ClientAccount string
merchantAccount string
money float64
date date.Date
}
type AuditMessageProducerContracts interface {
send(message AuditMessage) SendResult
}
type AuditMessageProducer struct {
kafkaTemplate map[string]string
}
func (a *AuditMessageProducer) send(message AuditMessage) SendResult {
messageBody := message.getBody()
return a.send(messageBody)
}
这样,我们使用kafka来发送,或者使用rbmq来发送,再或者直接调用接口等等,都无所谓,直接在send中进行处理即可,上层直接调用接口来发送。不管下层的具体实现。
这样,就摆脱了第三方服务的依赖。
而且,我们我们发送的接口中,封装了一个AuditMessage的实体。这样的好处就是可以表示当前转账的数据,全部封装在这个值对象中。它的形式上是一个结构体,但是实际上可以理解参数。后续如果下游需要的数据越来越多,属性也会越来越多,我们只需要修改这个值对象,不需要增加单一参数了。而且也可以给下游说明,我能够提供了全部在这里,你自己看吧,防止扯皮。
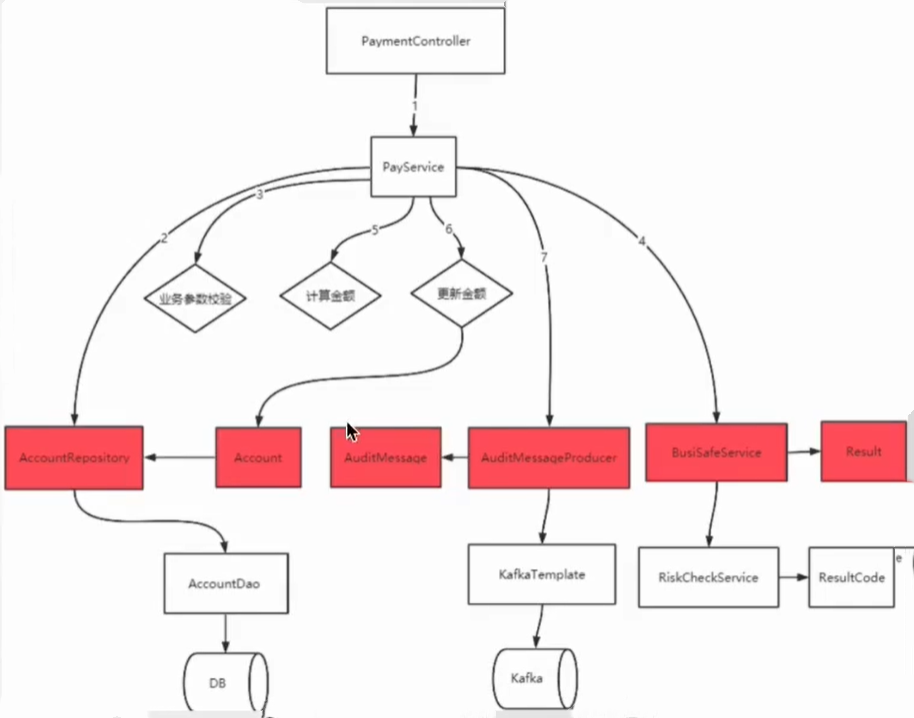
这种封装第三方服务的,包括封装mq、redis、ES等等中间件,我们还是叫做 防腐层。
下一步,我们就大头的,转账业务了。
使用领域服务
转账业务,最简单的就是商家进、买家出,但也是容易发生很多变化的,比如红包、优惠券、减免等等促销活动,都会针对金额计算有变动,而且也没那么简单了。
如何来隔离这些变化呢?我们看伪代码:
type AccountTransferContracts interface {
transfer(sourceAccount Account, targetAccount Account, money Money)
}
type AccountTransferService struct {
}
func (a *AccountTransferService) transfer(sourceAccount Account, targetAccount Account, money Money) {
sourceAccount.deposit(money.money)
sourceAccount.withdraw(money.money)
}
形式上,也是抽象出来AccountTransferContracts接口,然后在transfer中进行处理,然后注意的是,它传的形参,都是结构体,而不是字段的属性值,也是DDD的建议。那如何隔离变化呢?DDD强调是在实现当中,跨多个实体的业务动作,交由每个实体自己去完成,如也就是上面的sourceAccount.deposit(money.money),扣多少钱,当前transfer不计算,而是交由deposit方法,自己去完成。只是把两个实体的动作(money)传入。同理,商户增加多少余额,你们自己去算。这样的好处是:保持每个实体的独立性,未来一旦有任何变化,只需要去自己的实体中查看。
这种模式,更加符合轻量变化的一种思想。将属性变化的过程,全部丢到实体里面去,未来要梳理变化过程,只需要看实体即可。
嗯,没错,DDD也有一个概念将这种思想固化,就是 领域服务,封装实体业务,保持实体纯粹性,出淤泥而不染。 多个实体构建的业务场景,交给领域层来实现,但是领域层只是薄薄的一层,只负责组装业务场景,不负责具体实现,具体实现由实体自己来做。
好了,此致,我们所有的结构都已经按照DDD设计理念改造完成,我们再看看代码。
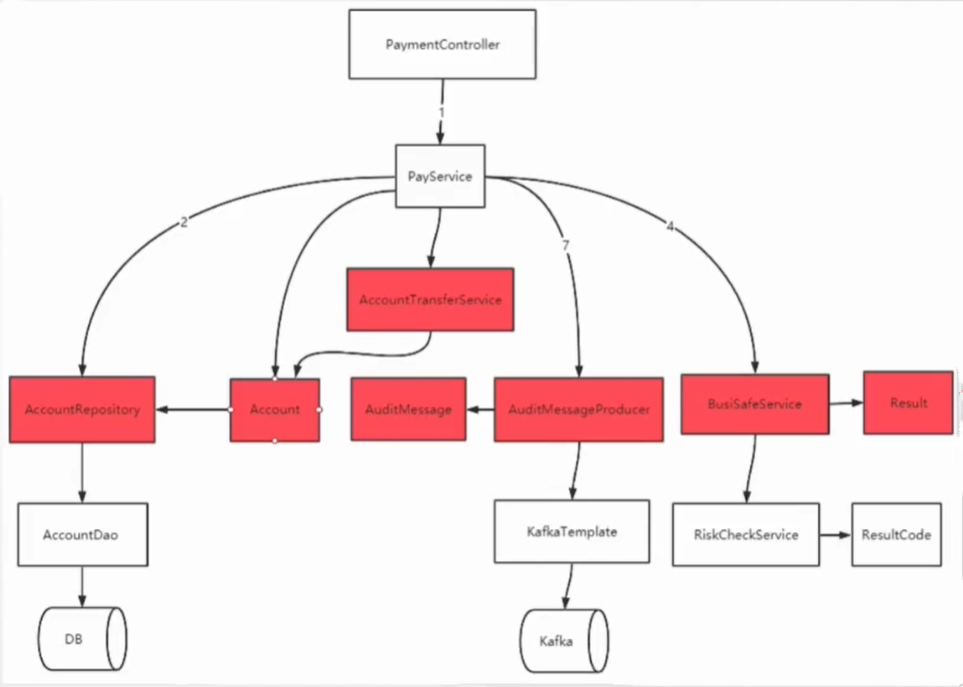
结果展示
我们按照DDD理念,花里花哨的改造了这么多,最后的效果如何呢?我们看看主业务:
type PayServiceContracts interface {
pay(client Account, merchant Account, amount Money) (*Result, error)
}
type DDDPayService struct {
accountRepository AccountRepositoryContracts
auditMessageProducer AuditMessageProducerContracts
busiSafeService BusiSafeContracts
accountTransferService AccountTransferContracts
}
func (d *DDDPayService) pay(client Account, merchant Account, money Money) (*Result, error) {
clientAccount := d.accountRepository.findByID(client.id)
merAccount := d.accountRepository.findByID(merchant.id)
// 交易检查
preCheck := d.busiSafeService.checkBusi(client, merAccount, money)
if preCheck != Result.SUCCESS {
return nil, errors.New("REJECT")
}
// 转账业务
d.accountTransferService.transfer(client, merchant, money)
// 保存数据
d.accountRepository.save(client)
d.accountRepository.save(merchant)
// 发送审计消息
message := AuditMessage{...}
d.auditMessageProducer.send(message)
return nil, nil
}
看到没,这样就服务层就特别的清晰,每一个结构都不会有任何的细节,只管调用。好处是:
- 需求更容易梳理,业务逻辑纯净清晰,没有业务逻辑与实现细节之间的复杂转化。
- 更容易单测,业务与基础设施隔离,没有基础设施,可以编写单测,比如我想测试转账业务,就只需要构造数据调用transfer即可,看看对应的钱是否正确。
- 更容易开发:领域内服务自治,不用担心其他模块的影响,各个业务没有直接关联。
- 技术容易更新:业务和数据边界区分很清楚,比如我把kafka改成RBMQ,业务完全不用动。
我们改完后,再来看看各个主键之间的依赖关系:
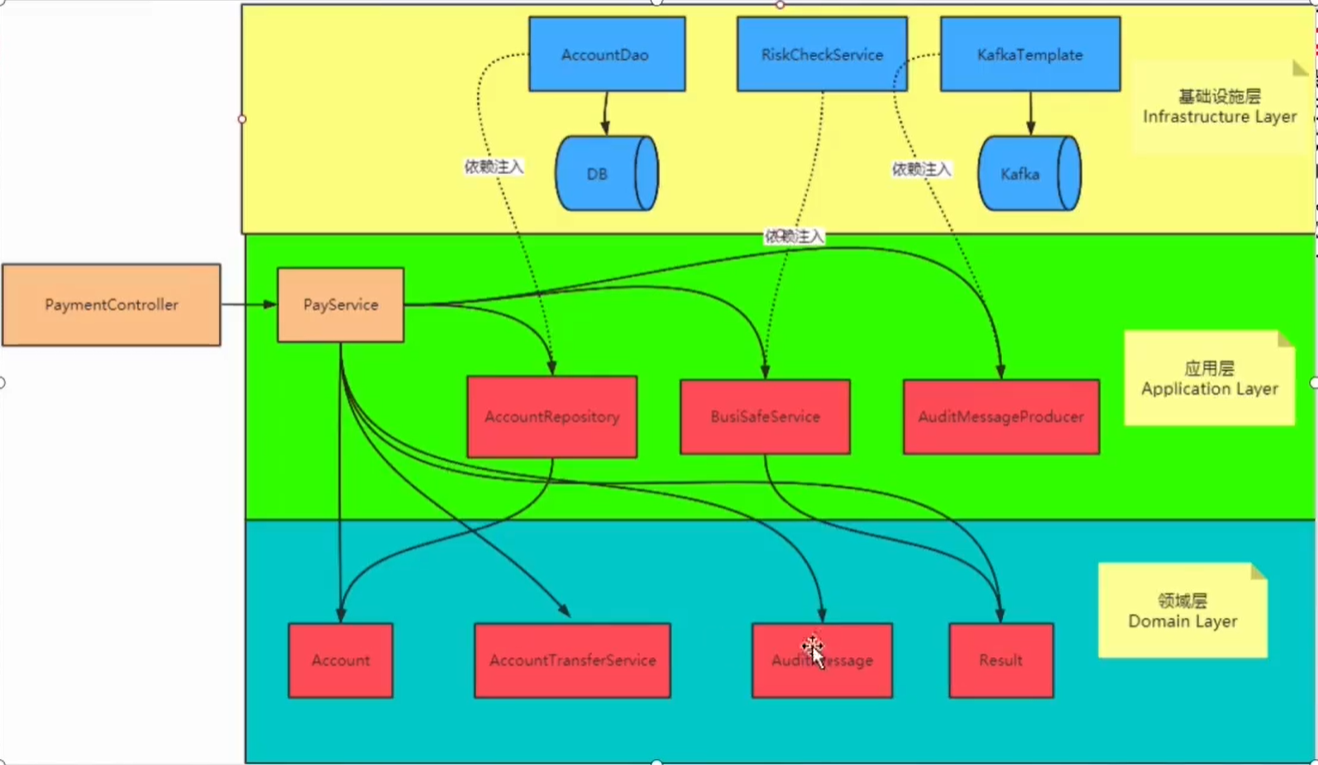
- 领域层:我们的实体,以及抽出的各个接口,都不需要任何的外部依赖了。因为所有业务都是针对实体以及接口来的,而接口有没有外部逻辑都可以声明业务。所以,领域层,是没有任何的外部依赖。
- 与数据库交互,第三方服务交互等等,都交给了服务的实现类去做了,也就是我们的基础设施层去干了。
- 具体的核心转账业务,就交给了应用层来做,它可以说是承上启下的一层。
所以整体看依赖关系的话,领域层不需要任何的依赖,应用层需要依赖领域层的具体实现,基础设施层需要依赖注入提供基础的业务能力。
DDD四层架构
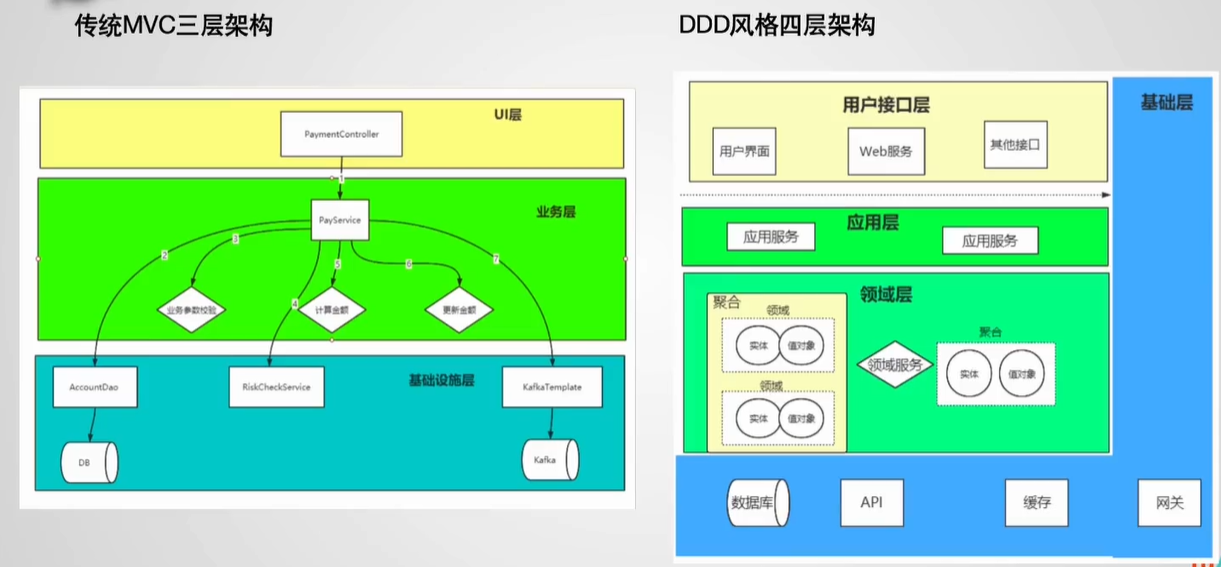
我们再回过头看看这个图片,就是DDD的四层架构,再来总结下,应该就非常清晰了:
- 领域层(Domain Layer):放之四海而皆准的理想,系统的核心,纯粹的业务表达能力,不需要任何外部依赖。
- 应用层(Application Layer):理想与现实,协调领域对象,组织形成业务场景,只依赖于领域层。
- 用户层(User Interface):护城河,负责于用户进行交互,接收用户请求,返回用户响应,只依赖于应用程。
- 基础层(Infrastructure Layer):业务于数据分离,为领域层提供持久化机制,为其它层提供通用技术能力。
这就是四层架构,虽然它颠覆了MVC的三层架构,变为了四层,但总体来说每一层的设计,每一个概念都并非随意提出来的,而是很多人类似的开发经验进行提炼、总结、沉淀出来的,而形成的一个个概念。这些概念如:实体、领域服务、防腐层、仓库、工厂、值对象等等,但是还有很多概念没有提及。后面会说。
但是(一般但是后面才是正文),DDD的结构体爆炸了,为了DDD的四层架构,我们抽出了很多很多的类(结构体)等等。这就是类爆炸,小小的转账服务,之前两三个结构体,现在整出来这么多的结构体,这不是爆炸是啥?
如何解决这个问题呢?往下看:
聚合
DDD为了解决类爆炸,就提出了聚合的概念。
聚合:将一系列相关的实体和值对象,代表同一种业务逻辑,将他们封装成一个整体,这个整体就叫做聚合。书上的概念是:聚合是用来确保这些领域对象在实现共同的业务逻辑时,能保证数据的一致性。
如何判断对象之间是否是聚合关系?
一个简单的原则,就是如果整体不存在,那么部分也就消失了,比如以下为订单的结构体,订单中的收货地址,如果订单的不存在了,那么收货地址就没有任何意义了。
type Order struct {
client Account
merchant Account
products []Product
address Address
}
所以,这就是一个聚合,可以叫做订单聚合。
聚合根
DDD把每个聚合内部有一个外部访问聚合的唯一入口,称为聚合根。
我的理解是:领域内部有一个唯一的对外开放的访问接口。每个聚合中应确定唯一的聚合根实体。比如上面我们的订单聚合中有很多的实体,Account、Product、Address等等,但是你要访问这些结构体,都需要通过Order这个结构体(实体)来访问,所以这个Order就是聚合根。
这样的好处是可以减少实体与实体之间的依赖关系。通过聚合和聚合根的设计,极大的简化整个系统内的对象关系。可以有效的解决类爆炸的问题。
但是又有另外一个问题,比如我想统计所有卖出去的商品数量,我还需要先根据聚合根Order,然后查出Product的总数,这样太绕了。那怎么办?
这里其实涉及到DDD对于业务的理解了。那什么是业务呢?
业务(business):通常我们的定义是,对数据的CURD,都是业务,但是在DDD中更加强调的是:对引起实体状态的这部分操作,需要做更加详细的设计,从而保证你的业务逻辑在变化的过程中保持稳定,而对于查询、删除,对于业务的状态没有太多的变化,所以这些操作,就没有必要按照DDD的条条框框去设计。
所以对于查询Product的总数这些,可以按照我们平常的设计,设计出Product的实体,单独查询。
限界上下文
以上,我们有了领域划分后,就需要保证领域之间的边界,这个边界就是限界上下文(Bounded Cotext)。
领域上下文是领域模型的知识语境,也是业务能力的纵向切分。
DDD强调,在划分业务的时候,不能按照MVC的模式,先设计数据库,而是先把领域拆分,实体设计,界限上下文设计出来后,然后在领域之中去设计表字段。这样逻辑边界、业务边界都很清晰。
设计思想线路
我们先由一张图,从MVC架构到DDD架构,最后到微服务架构之间的区别。
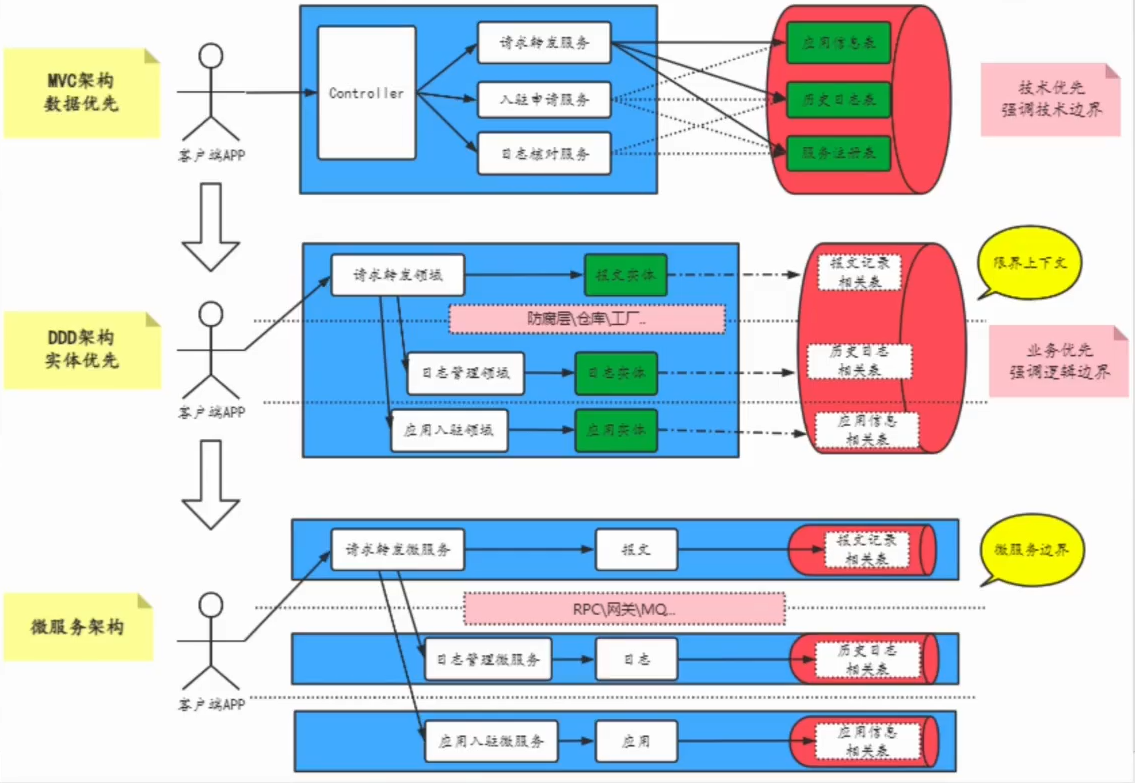
MVC架构-数据优先
典型的设计方式,就是优先设计数据库中的表结构,画UML图,通过UML来表现业务流程。然后通过表结构再往上层去映射实体,然后再去通过服务层去构建业务逻辑。
这样技术层面的边界很清晰,各层次分明,从Controller接入请求,转到服务层调度业务,最后到数据层读取/存储数据,与数据交互。
这样会有一个问题,就是设计出来的表结构,未来会相互之间调用,一对多或者多对多关联调用,导致很混乱,这也是不可避免的,这样才是构成业务,逻辑编辑很模糊。未来要拆分成微服务,几乎不可能了,一个服务层,包含了很多领域的方法。
DDD架构-实体优先
DDD架构,优先设计的是实体,只需要把业务属性的实体设计清晰,就可以通过实体构建当前领域内的业务逻辑,数据库无需优先设计,通过仓库、工厂模式来做改动。也就是说通过实体,就形成了业务领域,领域和领域之间,通过防腐层、限界上下文的概念进行隔离,它们天然就具备了逻辑编辑,未来调整边界整合方式,就可以进行架构的调整。
比如在单体服务下,通过包(package)和包之间进行调用,如果要改成微服务的话,只需要把包拆分成服务,即可。这样改动代价极其小,甚至只需要随着某次业务迭代就可以上线。
所以,DDD优先划分的是业务逻辑,业务边界。
微服务架构
首先,微服务的创始人 martin fowler这哥们其实就提出了,单体架构优先, monolithFirst ,如下图:
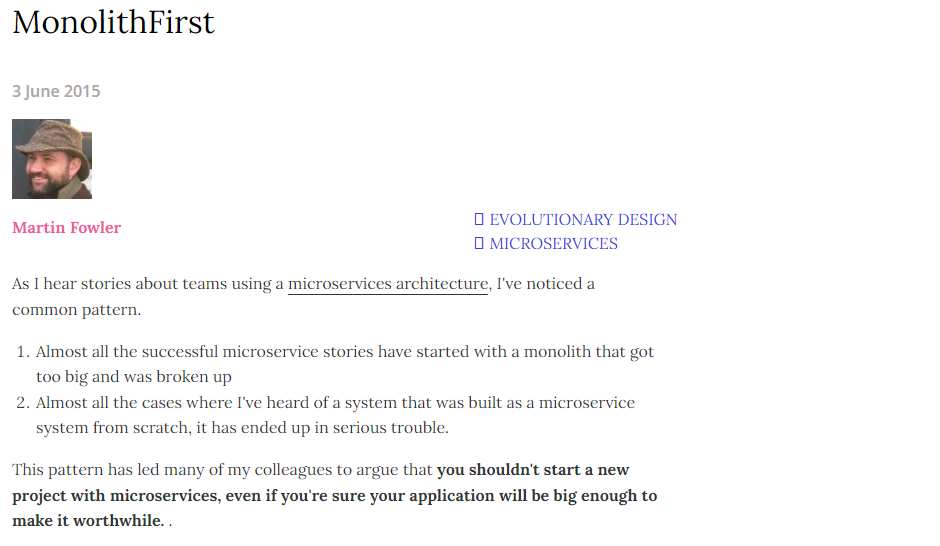
它给出的理由是:
- 几乎所有成功的微服务都是从一个太大的单体架构拆分多个微服务架构
- 几乎从头开始构建微服务架构的系统,最终都会陷入各种各样的严重的麻烦。
所以他和他的同事认为,即使确定你的应用程序足够大,也不应该开始使用微服务作为新项目的开始。
当然,这是他15年提出来的。
个人观点:如果在单体服务下,没有把各个业务梳理清楚,你的微服务拆分是不合理的,有很大的风险,而好的微服务模式,应该是先在单体架构先,把各个业务调整完成,验证你的业务逻辑是清晰的,然后按照DDD的思想,去设计完成后,再抽成微服务独立出去,通过业务的探索,而不是你个人的经验。

