
在如今的高并发、大数据时代,事事都谈分布式,口口不离高性能。当然,咱们redis也是不例外。
单节点部署redis,终归逃不开以下四个问题:
- 数据丢失问题,服务已宕机,数据丢失
- 并发能力问题,单个redis并发虽然可以,但是基于秒杀、双11等等大并发下,还是捉襟见肘。
- 故障恢复问题,当出现宕机,则服务不可用。
- 存储能力问题,单台服务器的存储终归是有限制的。
基于数据安全和故障问题,通常是有redis持久化和哨兵模式保证。
Redis的分布式部署通常包括以下两个主要模式:主从复制和集群模式。
Redis持久化
目前redis做持久化有两个方案,RDB和AOF。
RDB(数据快照文件)
全称:redis database backup file,也叫做redis数据快照,redis默认的持久化方式,简单来说就是把内存中的所有数据记录到磁盘中。当redis实例故障重启后,从磁盘读取快照文件,恢复数据。快照文件,就成为rdb文件,可以指定保存目录。
rdb在指定时间间隔,将内存中的数据集快照写入磁盘,实际操作就是fork一个子进程。我们可以设置手动触发(save)还是自动触发(规则满足、flushall命令、退出redis都会自动触发)。
所有的配置,都在对于的redis.conf文件中配置,以下列举常用的配置:
# save <seconds> <changes> [<seconds> <changes> ...]
# 几秒内多少个变化即保存
# 为空表示禁用 save ""
save 3600 1 300 100 60 10000
# 文件是否压缩 建议no,因为压缩会消耗cpu,不压缩消耗磁盘,磁盘不值钱
rdbcompression yes
# The filename where to dump the DB
dbfilename dump.rdb
# Note that you must specify a directory here, not a file name.
dir /var/lib/redis
原理
上面也大概说了下,同步其实就是fork一个子进程,子进程共享主进程的内存数据,完成fork后读取内存的数据写入RDB文件。具体是如何呢? 先介绍两个概念:
- 物理内存:可以理解为内存条
- 页表:在Linux系统,进程没办法直接操作物理内存,而是给每个进程分配一个虚拟内存,操作系统会维护一个物理内存和虚拟内存的映射关系表,这个表,就叫做页表
如下图: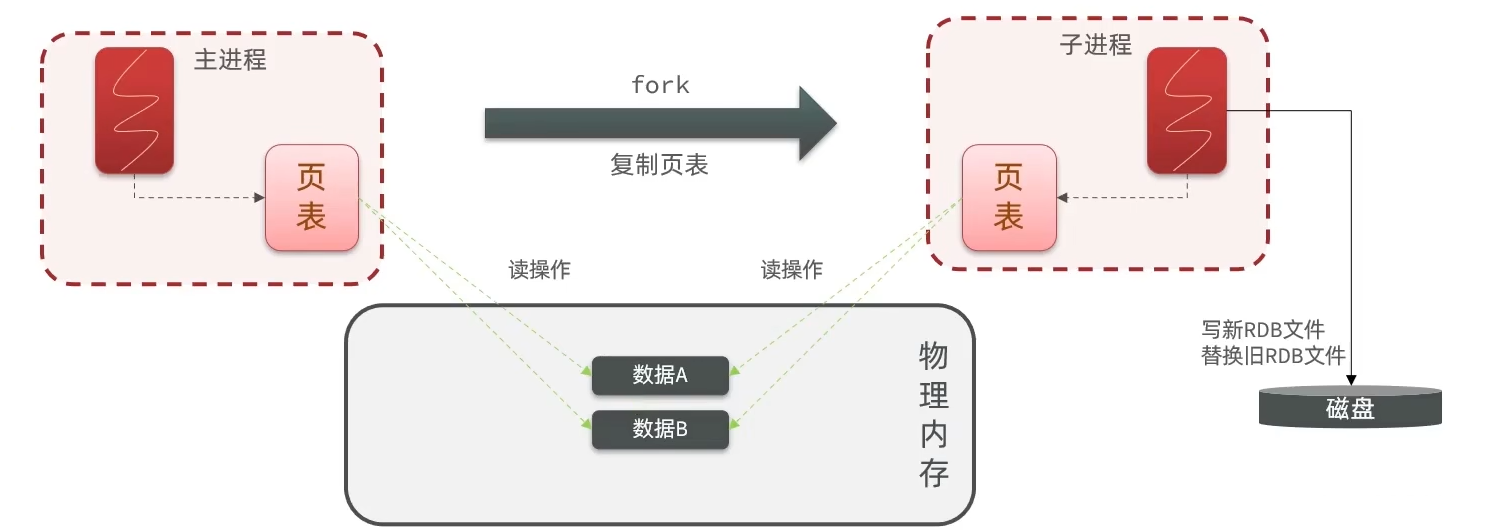
- 主进程操作虚拟内存,而虚拟内存基于页表的映射关系,到物理内存。实现对物理内存的读写。
- fork的时候有短暂的阻塞,fork的时候,并非是对物理内存做拷贝,而是把映射关系,页表复制给子进程。这样复制的速度就非常快,阻塞的时间减少。
- 子进程在操作页表的时候,也就可以直接操作与主进程相同的物理内存区域了。实现了主进程的共享。
- 所以子进程就直接读取自己内存的数据(也是主进程的),然后再把他写入RDB文件,替换掉之前的RDB文件。
但是有个问题,子进程在重写rdb的时候,主进程此时又接收了新的文件,读写可能还会造成脏数据,该怎么办?
为了避免,fork底层才用过了copy-on-write技术,上图我们的内存是没有拷贝的。也就是说:
- 当主进程执行读操作的时候,访问共享内存。
- 当主进程写操作的时候,拷贝一份数据,执行写操作。
如下图:
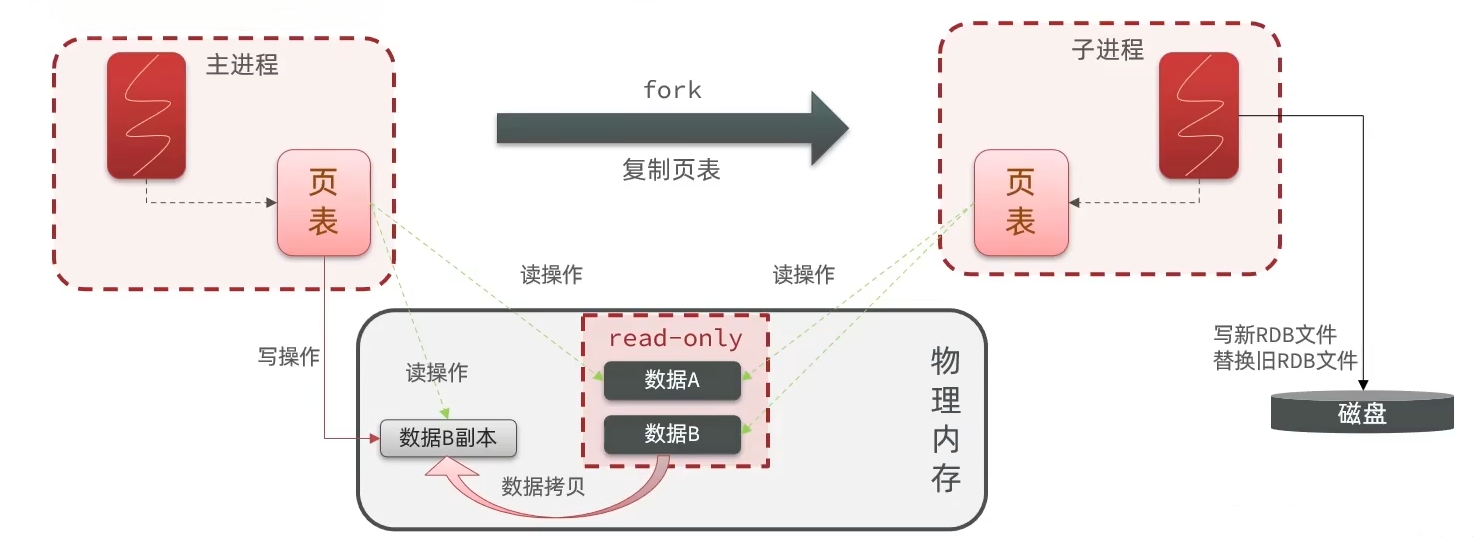
- 一旦开启fork,fork进程会把共享内存块标记为 read-only,只读模式。
- 当主进程接收到写操作到数据B的时候,会先拷贝一份数据B副本,然后在副本上做操作(以后读写操作都在副本上)。
- 修改副本的内容在特定的情况下会同步到内存中。
恢复RDB文件
只需要将rdb文件放在配置的目录下,然后把名字修改成一致,redis启动的时候就自动恢复了。所以有时候在真实环境下,会通过这个形式进行备份。
124.223.47.250_6379:0>config get dir
1) "dir"
2) "/var/lib/redis"
优缺点
优点
- 整个redis数据库只包含一个文件dump.rdb,方便持久化
- 容灾好,方便备份,恢复方便
- 性能最大化,fork子进程完成操作,主进程继续处理命令
- 数据集大的时候,比AOF启动效率高
- 所有断电的情况下,启动redis的时候去判断主机和从机就是谁的rdb文件更大更新,就采用谁的。
缺点
- 数据安全性低,rdb间隔时间进行持久化,如果在之间redis出故障,会发生数据丢失。
- 通过fork子进程协助完成数据持久化,如果大数据集大时,子进程长时间占用cpu。
- 在极端情况下,子进程一直在写新文件的同时,主进程不断有新的数据进来,那就不断的去拷贝数据,这对内存的占用也是非常严重的。
AOF(追加文件)
Append File,处理的每一个写命令都记录在AOF文件中,可以看做是命令日志文件。(类似mysql的binlog按statement格式进行记录,把所有DML操作记录。)
AOF默认是关闭的,需要修改redis.conf配置来开启:
# 默认为no,开启为yes
appendonly no
# aof文件的名称
appendfilename "appendonly.aof"
# 记录的频率,通过一下配置
# appendfsync always # 表示每执行一次写命令,立即记录到AOF文件中,主进程写磁盘
appendfsync everysec # 写命令执行完先放入AOF缓冲区(内存),然后每个1s将缓冲区数据写到AOF文件,默认方案。最多丢失1s中数据。
# appendfsync no # 躺平了,只写内存,什么时候落到磁盘由操作系统决定,安全差性能好。
案例
如命令:set name milo set sex 1 set name yang
aof文件如下:
SELECT
$1
0
*3
$3
set
$4
name
$4
milo
*3
$3
set
$3
sex
$1
1
*3
$3
set
$4
name
$4
yang
以上可看,因为是记录命令,所以aof文件会比rdb文件大很多。而且aof会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。
但可以执行bgrewriteaof命令,可以让aof文件执行重写功能,用最少的命令达到相同效果。
124.223.47.250_6379:0>BGREWRITEAOF
"Background append only file rewriting started"
当然,redis也有对应的配置来触发阈值自动重写aof文件。
# aof文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# aof文件体积最小多大以上才出发重写
auto-aof-rewrite-min-size 64mb
优缺点
优点
- 数据安全
- 通过append模式写文件,即使中途服务器宕机也不会破坏已经存在的内容,可以通过redis-check-aof工具解决数据一致性的问题
- 如果不小心执行了flushall等等,如果开启了AOF不要慌,把这个记录删掉,重启redis即可。
- 定时重写文件,压缩文件
缺点
- 比RDB文件大很多,且恢复速度慢,需要一条条执行下去。
- 数据集大的时候,启动效率低
- 运行效率没有rdb高,毕竟需要超过io去写文件。
持久化之最佳实践
以上,RDB和AOF都介绍完成,当然在实际开发中不会依赖某一个,而是结合使用。如 主节点开启 AOF,各个从节点开启 RDB。
| RDB | AOF | |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照 | 记录每一个执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷磁盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源,但AOF重写时会占用大量CPU和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高的最佳选择 |
redis主从同步
一直在说,单节点的并发能力是有上限的,提高redis的并发,必须搭建主从同步,实现读写分离。如以下架构:
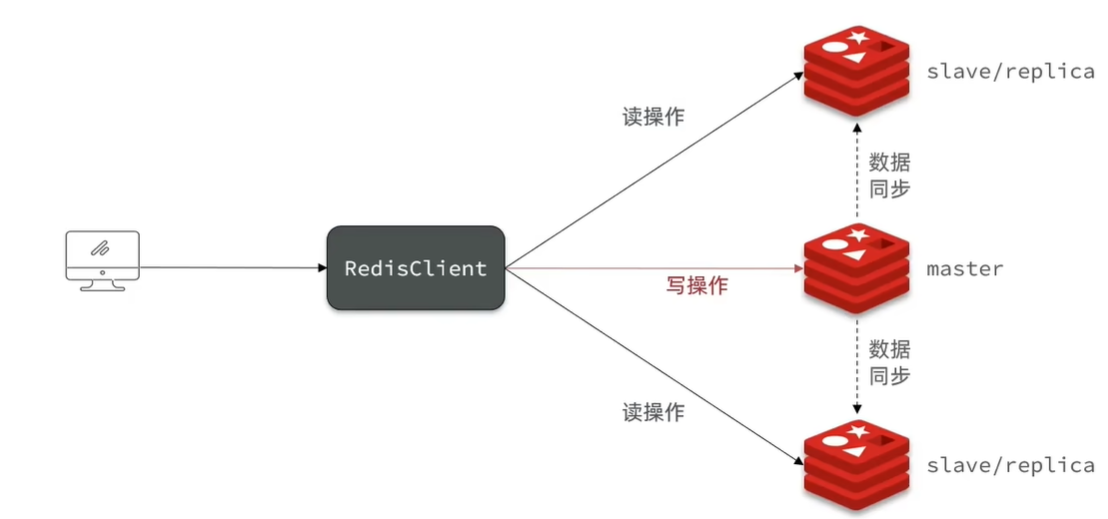
在redis5.0之前从节点叫做slave,之后叫做replica,反正这两个都是从节点。
前期准备
安装redis,其中6379端口作为master,然后基于redis.conf复制redis01.conf和redis02.conf,端口为63791和63792作为从节点。
对文件进行修改:
pidfile /var/run/redis_63791.pid # 指定新的PID文件路径
port 63791 # 指定新的端口号
logfile /var/log/redis/redis_63791.log # 指定新的日志文件路径
dbfilename dump_63791.rdb # 指定新的转储文件路径
接着分别针对这两个文件运行 redis-server redis_01.conf 链接上去即可。

搭建主从模式
搭建其实很简单,就一行命令,简单来说就是信徒根据口号拜造物主,甭管造物主认不认。
命令就是 slaveof id port 如下:

- 从节点上运行slaveof启动链接。
- 从节点没有写入和更新的权限,默认只读。
- 不想连接了,使用
slaveof no one把自己变为主库,有写的权限 - 使用
info replication查看对应信息 - 首次连接会把所有主库信息全量同步
原理
mysql的主从复制我们知道,是通过binlog来实现的,那么redis呢?有没有类似的呢?是有的,而且比mysql还要强大,它还可以支持首次全量同步。
他,通过rdb文件来同步数据。
全量同步
首先抛出来,master如何判断当前slave是不是第一次来同步数据?这里有两个重要的概念:
- Replication ID:简称replid,是数据集的标记,id一致则说明是同一个数据集的,是一家人。每个master有唯一的replid,slave则会继承master节点的replid,如上图我们的master_replid。
- offset:偏移量,随着repl_baklog中的数据增多而逐渐增大。slave完成同步的时候也会记录当前同步的offset,如果slave的offset小于master的offset,说明slave数据落后于master,所以需要更新。
好了,介绍完了概念了,那来说说master如何判断slave节点是不是第一次来做数据同步?以及如何做全量同步的呢? 看下图:
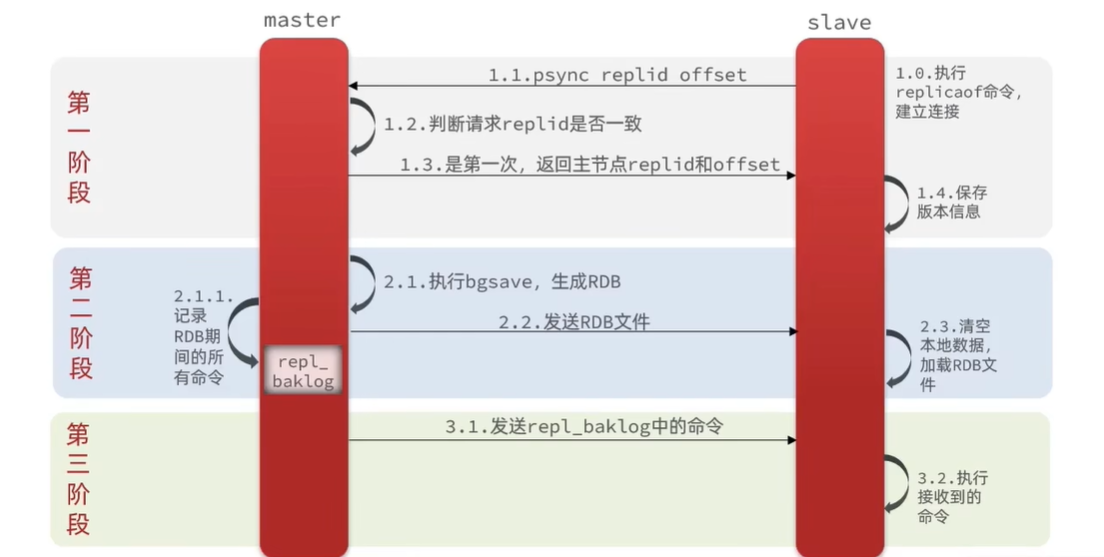
- 1.1 slave通过replicaof命令,以及携带repliid和offset来建立连接,请求同步增量数据。
- 1.2 master判断repliid如果不一致,则拒绝增量给全量数据,因为我不知道你之前是不是其他人的slave。
- 1.3 master返回的replid和offset给slave。
- 1.4 slave赶紧保存新boss的信息。
- 2.1 master要生成rdb文件呀,所以执行bgsave。且记录在生成rdb期间所有的新增数据放入repl_baklog中 2.1.1。
- 2.2 生成的rdb文件发送给slave
- 2.3 slave接收发过来的全量rdb,先清空本地数据,把ex-gf的东西都丢掉,用来加载本次的rdb文件。此次大部分数据都同步完成。
- 3.1 如果master在打包rdb时候还有新的数数据产生,并且存在了repl_baklog中,则继续发给slave。
- 3.2 执行接收到的命令
增量更新
增量同步就想对简单了,也就是验证slave的repliid是一样的,就说明你来过了。

- 1.1 还是一样slave通过replicaof命令,以及携带repliid和offset来建立连接,请求同步增量数据。
- 1.2/1.3 master判断repliid是我的味道,那就不是第一次了,回复 continue,来吧兄弟。
- 2.1 master根据offset的数据,去repl_baklog中去查找,然后把offset之后到最新的所有命令拿到。
- 2.2 发送给slave
- 2.3 slave拿到最新的rdb命令后,执行即可。
repl_baklog(复制回放缓冲区)了:是一种用于维护主从复制数据的缓冲区。它用于存储主节点的写命令,以便从节点可以通过网络复制这些写命令,并将它们应用到从节点上的数据集,以保持主从节点的数据同步。 他是有大小的,假设offset的大小操作了这个数,也就是在repl_baklog中已经找不到了,无法基于log做增量同步,master就会发送全量的数据给slave。 这个问题可以说正常情况下无法避免,只能优化。
优化点:
- 如果你网络很快,磁盘空间有限,在master可以配置
repl-diskless-sync yes启用无磁盘复制直接通过网络发送,避免全量同步时的磁盘io。 - redis单节点的内存占用不要太大,减少rdb导致的过多磁盘IO。
- 尽可能的避免全量同步,如提高repl_backlog的大小(repl-backlog-size)、在发现slave宕机了尽快实现故障恢复等等。
- 限制一个master上的slave节点数量,如果是在太多slave,则可以采用主-从-从链式结构,比如以上例子,再来一个redis03,可以指定redis01作为主节点,而并非是6370.
但是,还是有问题,虽然slave宕机了,它恢复后可以继续找master节点同步数据,那么 master节点宕机了怎么办?业务瘫痪了。那么接着看:
哨兵(sentinel)机制
如上,我们增加了哨兵机制,也就是它时时刻刻的在监听集群状态,如果master节点一旦宕机,则会选举一个新的节点作为master,不会让业务瘫痪。
如果对mycat熟悉的话,可以把哨兵理解为mycat。它可以:
- 监控:sentinel会不断检查你的master和slave是否按预期工作
- 自动故障恢复:如果master故障,sentinel会将一个slave提示为master,当故障恢复后也会以新的master为主。
- 通知:sentinel充当redis客户端的服务发现来源,当几圈发生故障转移时,会将最新信息推送给redis客户端,也就是我们客户端是直接连接哨兵了。
哨兵原理
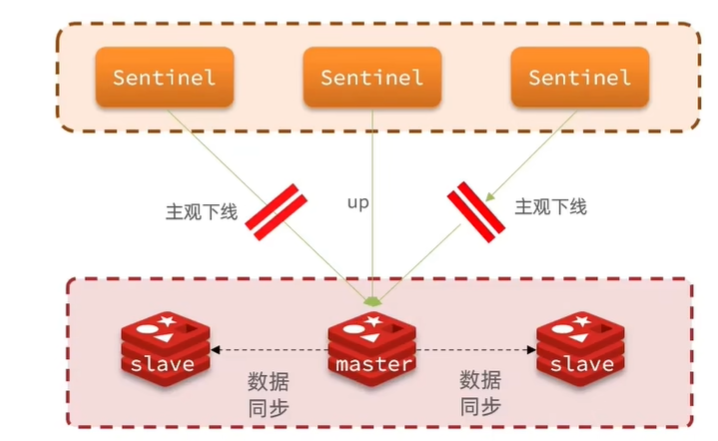
监控
sentinel基于心跳机制监测服务状态,每隔1s向集群的每隔实例发送ping命令:
- 主观下线:如果某个sentinel节点发现某个实例未在规定时间响应,则认为该实例主观下线。
- 客观下线:若草果指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过sentinel实例数量一半。也就是投票机制。
选举新master
那么把当前master下线了,那如何选举新的master呢?依据是:
- 判断slave节点和master节点断开时间长短,因为越长你的数据越旧。如果超过指定值(down-after-milliseconds*10)则排除该slave节点。
- 再判断slave节点的slave-priority值,越小优先级越高,如果是0则不参与选举。
- 如果slave-priority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高。 这个是最关键的。
- 如果到这里了,那选哪个都无所谓了,那就判断slave节点的运行id大小,越小优先级越高。
如何做故障转移
既然选出来了新的master了,首先先恭喜slave上位了,先给他发邮件,正式的承认它,再告诉所有人。如下:
- sentinel给当选的slave发送
slaveof no one,让该节点成为master节点。 - sentinel给所有其他所有的slave发送
slaveof new_master_ip new_master_port,让这些slave成为新master节点,开始从新的master同步数据。 - 至于那个出故障的老master,则会标记为slave,哪怕你故障解决了,也是slave。
搭建哨兵集群
环境搭建
还是统一台机器上,不同端口操作。我们创建三个哨兵,则需要创建三个文件夹,s1,s2,s3。
[root@VM-4-9-centos redis_sentinel]# mkdir s1 s2 s3
[root@VM-4-9-centos redis_sentinel]# pwd
/home/test/redis_sentinel
[root@VM-4-9-centos redis_sentinel]# ll
total 12
drwxr-xr-x 2 root root 4096 Oct 12 22:52 s1
drwxr-xr-x 2 root root 4096 Oct 12 22:52 s2
drwxr-xr-x 2 root root 4096 Oct 12 22:52 s3
接着在s1目录创建sentinel.conf,添加如下内容:
port 27001
sentinel announce-ip 127.0.0.1
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
dir "/tmp/s1"
- port: 当前sentinel实例端口
- sentinel monitor mymaste :指定主节点信息 2表示选举master时的quorum值
接着把s1的sentinel.conf拷贝到s2、s3下,并且修改端口为27002/27003 ,且在/tmp下分别创建s1/s2/s3 拷贝完成后,可以通过命令来一次性修改:
sed -i -e 's/27001/27002/g' -e 's/s1/s2/g' s2/sentinel.conf
sed -i -e 's/27001/27003/g' -e 's/s1/s3/g' s3/sentinel.conf
启动
三个分别启动了:
redis-sentinel s1/sentinel.conf
redis-sentinel s2/sentinel.conf
redis-sentinel s3/sentinel.conf
如果没问题,启动完成后其实就已经在监控了master信息了,至于为什么没监控slave节点,因为没必要,因为master中自己去监控slave了。
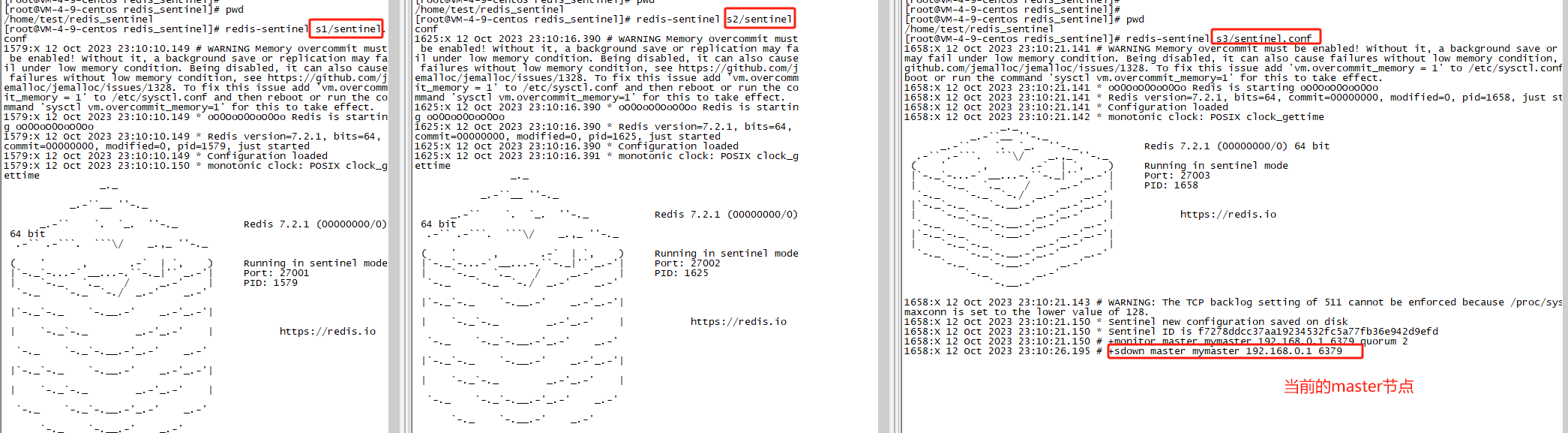
测试主节点宕机
那就是把我们6379断掉
客户端连接
那我们的客户端,是连接redis还是sentine呢? 那肯定是连接sentine了。此时我们需要借助第三方工具 :FZambia/sentinel ,来帮我们通过哨兵找到对应的master节点了。
func initSentinel() *redis.Pool {
sntnl := &sentinel.Sentinel{
Addrs: []string{"124.223.47.250:27001", "124.223.47.250:27002", "124.223.47.250:27003"},
MasterName: "mymaster",
Dial: func(addr string) (redis.Conn, error) {
timeout := 500 * time.Millisecond
c, err := redis.DialTimeout("tcp", addr, timeout, timeout, timeout)
if err != nil {
fmt.Println("newSentinelPool sntnl.Dial() error [", err, "]")
return nil, err
}
return c, nil
},
}
return &redis.Pool{
MaxIdle: 3,
MaxActive: 64,
Wait: true,
IdleTimeout: 240 * time.Second,
Dial: func() (redis.Conn, error) {
masterAddr, err := sntnl.MasterAddr()
if err != nil {
fmt.Println("newSentinelPool Dial() masterAddr error [", err, "]")
return nil, err
}
fmt.Println("MasterAddr [", masterAddr, "]")
c, err := redis.Dial("tcp", masterAddr)
if err != nil {
fmt.Println("connect master addr error [", err, "]")
return nil, err
}
return c, nil
},
}
}
哨兵已然解决了在高并发下读的均衡性,但是如果高并发写呢?还是解决不了。这就得分片集群了。
分片集群
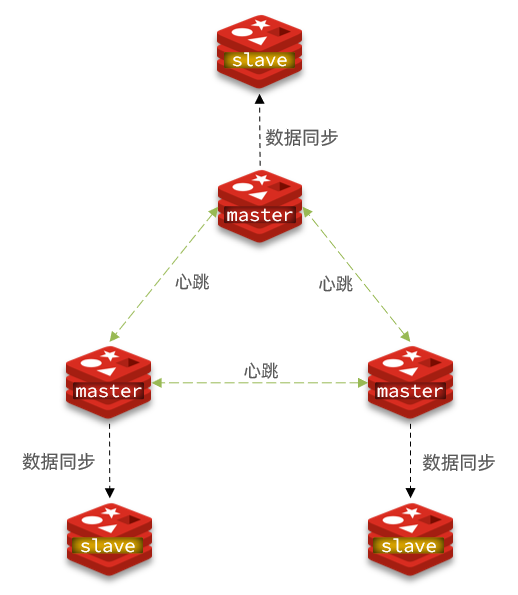
分片集群的特征以及可以解决的问题:
- 集群中有多个master,每个master保存不同数据,解决了高并发写的问题。
- 每个master都可以有多个slave节点,解决了读写分离。
- master之间通过ping监测彼此健康状态,不需要哨兵模式了。
- 客户端请求可以访问集群任意节点,最终都会被转发到正确的节点上去。
环境准备
服务器准备
首先先清除掉之前所有的redis服务,我们重新开始。
同样是在同一个服务器起来,配置如三个master,这三个master分别有一个slave实例。
| IP | PORT | 角色 |
|---|---|---|
| 124.223.27.250 | 7001 | master |
| 124.223.27.250 | 7002 | master |
| 124.223.27.250 | 7003 | master |
| 124.223.27.250 | 8001 | slave |
| 124.223.27.250 | 8002 | slave |
| 124.223.27.250 | 8003 | slave |
在 /tmp 创建目录:
mkdir 6379 7001 7002 7003 8001 8002 8003在/tmp下新建一个redis.conf文件(因为会有集群相关,不要污染我们之前的文件):
port 6379 # 开启集群功能 cluster-enabled yes # 集群的配置文件名称,不需要我们创建,由redis自己维护 cluster-config-file /tmp/6379/nodes.conf # 节点心跳失败的超时时间 cluster-node-timeout 5000 # 持久化文件存放目录 dir /tmp/6379 # 绑定地址 bind 0.0.0.0 # 让redis后台运行 daemonize yes # 注册的实例ip replica-announce-ip 124.223.47.250 # 保护模式 protected-mode no # 数据库数量 databases 1 # 日志 logfile /tmp/6379/run.log拷贝到每个目录下:
# 进入/tmp目录 cd /tmp # 执行拷贝 echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf修改每个目录下的redis.conf,将其中的6379修改为与所在目录一致:
# 进入/tmp目录 cd /tmp # 修改配置文件 printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf
启动
给防火墙增加对应端口
# 进入/tmp目录
cd /tmp
# 一键启动所有服务
[root@VM-4-9-centos tmp]# printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf
redis-server 7001/redis.conf
redis-server 7002/redis.conf
redis-server 7003/redis.conf
redis-server 8001/redis.conf
redis-server 8002/redis.conf
redis-server 8003/redis.conf
[root@VM-4-9-centos tmp]# ps -ef | grep redis
root 5124 1 0 11:04 ? 00:00:00 redis-server 0.0.0.0:7001 [cluster]
root 5126 1 0 11:04 ? 00:00:00 redis-server 0.0.0.0:7002 [cluster]
root 5132 1 0 11:04 ? 00:00:00 redis-server 0.0.0.0:7003 [cluster]
root 5138 1 0 11:04 ? 00:00:00 redis-server 0.0.0.0:8001 [cluster]
root 5140 1 0 11:04 ? 00:00:00 redis-server 0.0.0.0:8002 [cluster]
root 5146 1 0 11:04 ? 00:00:00 redis-server 0.0.0.0:8003 [cluster]
root 5369 32084 0 11:05 pts/3 00:00:00 grep --color=auto redis
如果要关闭所有:ps -ef | grep redis | awk '{print $2}' | xargs kill
目前已经全部启动了,但是每个都是独立的,并非集群状态
创建集群
redis-cli --cluster create --cluster-replicas 1 124.223.47.250:7001 124.223.47.250:7002 124.223.47.250:7003 124.223.47.250:8001 124.223.47.250:8002 124.223.47.250:8003
命令说明:
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令create:代表是创建集群--replicas 1或者--cluster-replicas 1:指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1)得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
[root@VM-4-9-centos ~]# redis-cli --cluster create --cluster-replicas 1 124.223.47.250:7001 124.223.47.250:7002 124.223.47.250:7003 124.223.47.250:8001 124.223.47.250:8002 124.223.47.250:8003
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 124.223.47.250:8002 to 124.223.47.250:7001
Adding replica 124.223.47.250:8003 to 124.223.47.250:7002
Adding replica 124.223.47.250:8001 to 124.223.47.250:7003
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: c482ebb2fdcd189aa588c0d8512603a15a6e5597 124.223.47.250:7001
slots:[0-5460] (5461 slots) master
M: 30ea7feeb337d44c88754f70d93c65946fe314dd 124.223.47.250:7002
slots:[5461-10922] (5462 slots) master
M: a35a0d24a47bb01b8c86996932863f8daaae430d 124.223.47.250:7003
slots:[10923-16383] (5461 slots) master
S: 515d384cd82e9cecba734b4658d5e24af75f9598 124.223.47.250:8001
replicates c482ebb2fdcd189aa588c0d8512603a15a6e5597
S: 9a8243a75306f2df6ad43265d6b1130562fa05e8 124.223.47.250:8002
replicates 30ea7feeb337d44c88754f70d93c65946fe314dd
S: abd58e60936775ac9501c5a58ba2580072866b5f 124.223.47.250:8003
replicates a35a0d24a47bb01b8c86996932863f8daaae430d
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
他会询问你,这样分配是否可以,如果可以输入yes。然后就自动建立连接。
集群建立好之后,可以通过 redis-cli -p 7001 cluster nodes 查看状态。
散列插槽
我们刚刚起来的时候,有个Slots,也就是每个master节点映射到0-16383共16384个插槽上面。如:
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
那么插槽的作用是什么呢?
比如我要存在一个数据到集群中,那么这个数据应该存在那个master中呢?随便存,那到时候去哪取呢? ok 这个插槽就是解决集群中存和取的问题。
数据key并非是与节点绑定,而是与插槽绑定,redis会根据key的有效部分计算插槽值,分两种情况:
- key中包含{}且{}中至少包含1个字符,{}中的部分就是有效部分
- key中不包含{},整个key都是有效部分。
比如,key是num,那么就根据num计算,如果是{milo}num,则根据milo计算。计算方式及时CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值,这有点类似mycat中的字符串hash的感觉了。
也就是插槽的作用,就是把key经过散列后,分步到各个节点上,set和get皆如此。
那为什么数据要跟插槽绑定而不是master节点呢?
因为我们master节点有可能会宕机,这样数据就丢失了。而跟插槽绑定,master宕机后,会选举新的master,然后把之前的插槽转义到新的master上,包括像扩容的时候也可以转移。
如果我想把同一类型的数据固定在同一个redis实例呢?
比如用户信息、商品信息,想把所有用户信息都放在redis实例。
那么可以把用户的有效部分是一样的 比如使用{userinfo}:xx:xx作为key。而{userinfo}就是前缀。
故障转移
当集群中有一个master宕机了会发生什么?
1:首先是该实例与其他实例失去连接。
2:该实例疑似宕机了。
3:最后确认下线,然后自动提升一个slave为新的master。
这种是自动故障转移的流程。
手动宕机,数据迁移
有时候master机器老化,不适合做主节点,需要手动降级为slave。
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令,实现无感知的数据迁移。
客户端连接
与哨兵不同,我们直接配置所有节点的配如:7001/7002/7003/8001/8002/8003,因为任意一个节点都可以获取所有的信息,底层自己做的查询。

