
每个程序员,都有架构师的梦,那么互联网的架构,是如何演变的呢?
前言
时至今日,我们大型互联网架构已经发生翻天覆地的变化,已经具备高并发、高可用等特点,总体来说如下:
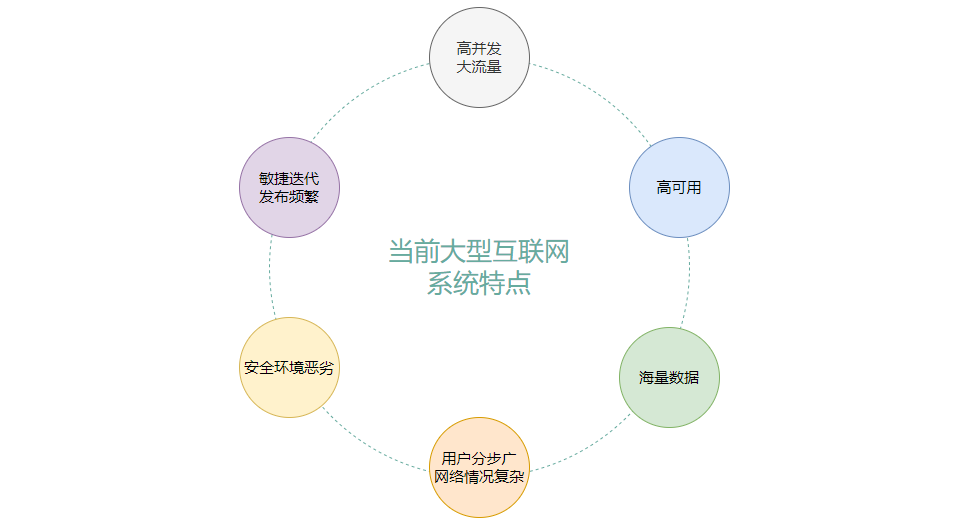
高并发和大流量
大型互联网需要面对高并发的访问用户,比如微博,在某个大V离婚的时候,需要扛住成百上千万粉丝的同时热点数据访问,在双11的时候,一分钟之内有上千万个访问量以及订单量。大规模的并发用户访问对系统的处理能力造成巨大的冲击,系统必须有足够强的处理能力才可以满足。短时间内的巨大流量,对系统的抗压能力形成考验。
高可用
大型互联网必须要7X24小时不间断的服务,比如微信,要是突然发不出消息,按照目前微信的体量,要是紧急事情,后果是极为严重的,为了保证系统的高可用,必须要进行特别的系统架构设计。
海量数据存储
互联网需要满足大量的用户使用,比如微信,每天单个用户的消息量都成百上千乃至上万条,目前微信有13亿多的用户,如此多的用户产生的数据量是巨大的,需要对这些数据进行重组和管理。特别是抖音、头条等等平台,还会采集用户数据,进行用户行为分析,从而增加用户粘度,对用户进行精准营销和服务,这就需要对数据进行分析、清洗,如此多的数据,如何进行管理和分类的呢?
用户分步广泛、网络情况复杂
互联网是为全球用户提供服务,用户分步范围广,各地的网络情况也参差不齐,更有甚者,每个地区都需要建立自己的数据中心来满足当地的法律法规,也是需要对系统架构进行相关的设计。
安全环境恶劣
网络也有不少的犯罪分子,互联网又是开放的,敌人在暗,如何免受攻击,也是值得探讨的问题。
迭代快,发布频繁
现在都讲究敏捷开发,快速迭代,当今互联网为了快速的适应市场,满足用户需求,发布频率是非常高的,传统互联网产品,比如银行、操作系统等等都是以年为单位发布,但现在的产品大部分都是每周发布,快速迭代来更新产品特征。
大型互联网架构演化过程
刚刚我们也提及了互联网的特点,那些特点的保证并非一蹴而就的,都是随着用户量的增加,访问压力增大,去驱动技术不断迭代,框架不断更新,增强系统的技术处理能力,系统架构的优化过程,如下图所示:
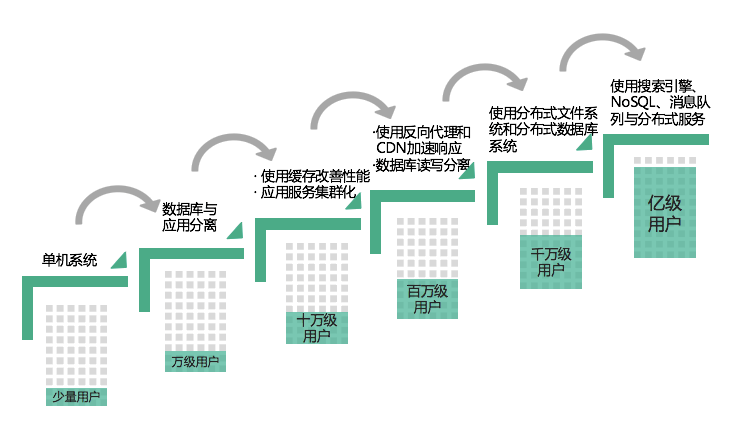
- 最早用户量很少的时候,一个单体架构就可以满足整体需求,业务、数据库等等全部放在一台服务器上即可。
- 随着互联网的兴起,用户越来越多,此时数据库访问压力增大,把数据库与应用服务器进行分离,也可以满足万级用户的使用需求。
- 用户量再次上来,达到十万级别,需要引进缓存来改性性能了,而应用服务器为了高可用也需要进行集群化管理,此时docker、k8s技术兴起。
- 用户爆发式增长,来到了百万级别的用户,单台数据库也扛不住了,需要进行多主多从,读写分离也保障数据库的可用性,使用反向代理、CDN加速来缓解分散应用服务器的压力。
- 互联网红利继续发展,到达千万级别,此时用户数据也越来越多,就需要使用分布式文件系统和分布式数据库系统架构来满足用户的访问压力。
- 超级庞大系统,通过ES、NoSQL、MQ和分布式服务等复杂的技术方案,可以满足亿级别的用户来访问。
单机系统
最早的时候,可能用户量比较少,只是有限的几个用户,或者是某个公司内部软件,只是几百、几千人的访问量。亦或者是测试服务器、用户验证技术以及业务模式是否可行的阶段,系统不需要太复杂,只需要具备访问的几个主要能力。应用程序开发完成之后,部署在服务器上,访问自己的DB、文件系统,就可以简单的构成一个单机系统,可以满足少量的用户使用,谈不上什么并发能力。
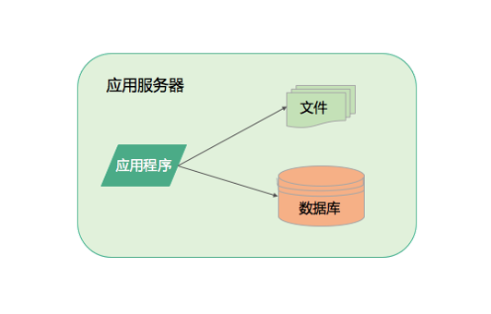
存储系统分离
随着用户量上来,或者是被证明这个系统是可行的,有价值的,就需要针对一次升级,就是数据库的升级,与应用进行分离,防止数据丢失,或者减少数据库的压力。google的搜索引擎最开始就是单体架构,只是部署在斯坦福实验室里面,给实验室的同学和老师使用。后续老师和同学都觉得比之前的搜索引擎好用,比如yahoo,就把这个消息扩散出去,整个斯坦福大学的老师和学生都过来访问这个服务器了。
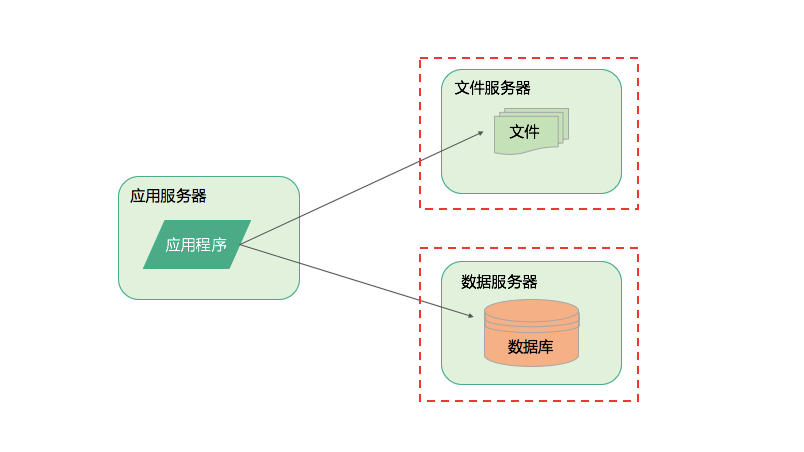
当然,进行第一次分离的时候,应用程序、数据库、文件系统分别部署在不同的一台服务器上面,但随着用户量继续增大,可能从1台变成了多台,那么响应的处理能力就提升了多倍,这种分离几乎不需要技术成本,只是把数据库文件系统进行远程部署和访问就可以了。
缓存
当然,后续肯定是变成了数据库的多主多从,读写分离的架构了。这样就可以大大改善性能。应用服务器也是从单台变为多台,通过负载均衡服务器进行转发。随着用户量上来后,缓存也进来了。
- 数据库的数据是存在磁盘上面的,访问的时候需要频繁进行io操作,而缓存的数据是存储在内存中,可以快速的进行读写。
- 数据库中的数据一般是原子性质的存在,而缓存中的数据一般是结果性质存在,拿到就直接使用,减少计算的时间,也减少了cpu的压力。
缓存也分为本地缓存和分布式缓存。
集群
应用服务器集群
存储系统分离、加入缓存后,现在瓶颈来到了应用服务器这边了,单台应用服务器已经扛不住大QPS,一台一个服务器连接大量的用户访问,就需要对应用服务器进行升级,,此时就应该把多个应用服务器捆绑起来作为一个集群,通过负载均衡调度器中的算法,来分流访问应用服务器。
数据库集群
不过随着不断添加更多的应用服务器,为更多的用户提供访问能力后,瓶颈又来到了数据库这边,单个数据库已经扛不住了,因为大量的数据都需要落地存储,虽然缓存可以缓解一部分压力,但是有一部分读操作以及落地写操作,需要大量访问数据库。此时就需要着手搭建数据库集群,采用主从模式,来进行服务器的读写分离。主从数据一致,主数据库复杂数据的写操作,从数据库负责读取操作,或者是搭建多主多从进行分离,提供更加强大的模式。
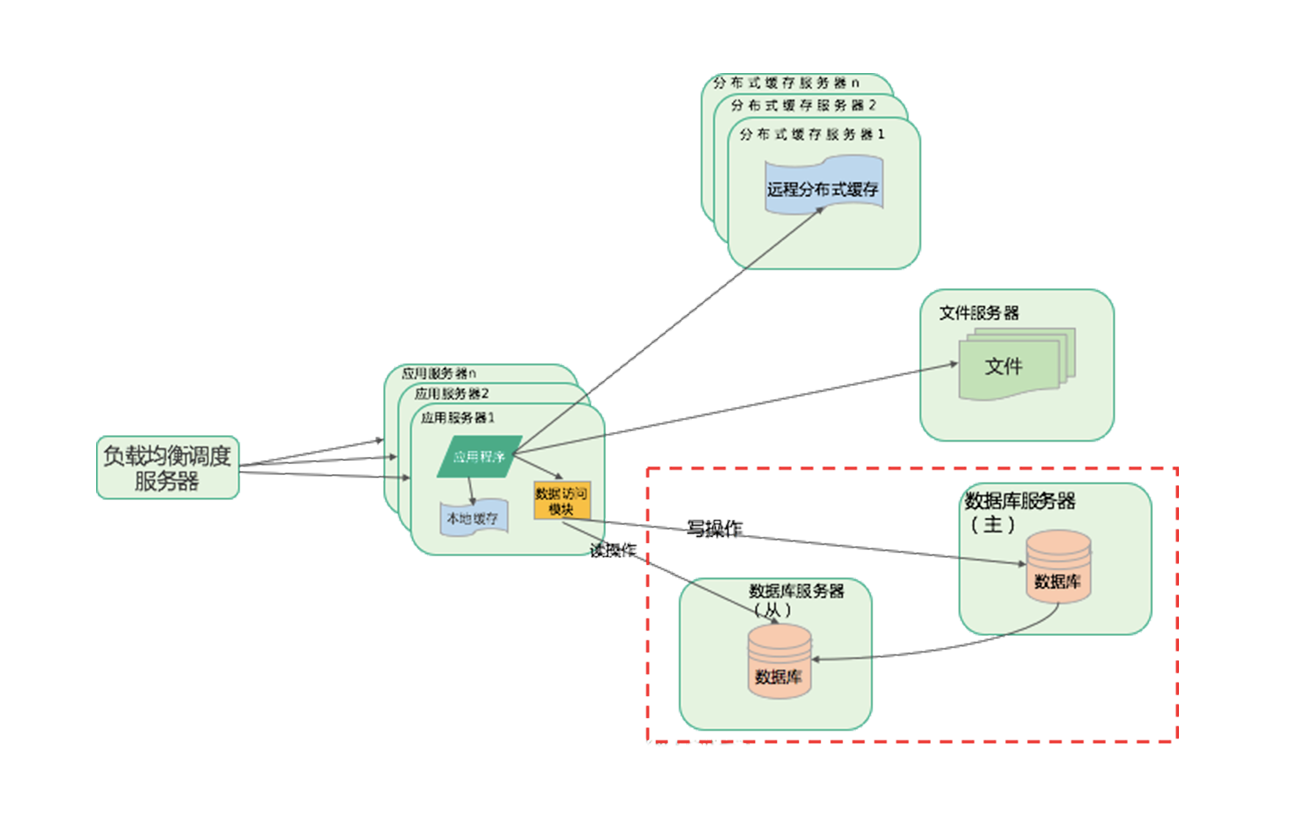
反向代理和CDN
如果想要更进一步的处理能力,需要使用到反向代理服务器和CDN进行加速。
CDN通俗来讲,就是用户最近的一个服务器,当访问互联网数据的时候,并非直接到达互联网的数据中心,而是先通过应用服务商进行数据转发。那么数据转发的时候,如果已经有我们想要的数据了,就不需要访问互联网数据中心。这种服务,CDN服务,它部署在运营商机房里面,离用户最近的一个服务器。
所以用户数据是先到达CDN服务器,如果有对应的数据,就直接从CDN返回,如果没有就去访问网站的数据中心,得到数据后再次访问到CDN供其他用户访问或者下一次访问,所以CDN本质上来说,还是一个缓存机制。
那么反向代理又是什么呢?
用户请求达到网站的数据中心之后,并非直接请求应用服务器,依然先查找一次缓存,就是反向代理服务器。
通俗点说,就是先在反向代理服务器中查询是否有用户请求的数据,有就直接从反向代理服务器中返回,没有再去请求应用服务器,然后再存储在反向代理服务器中。
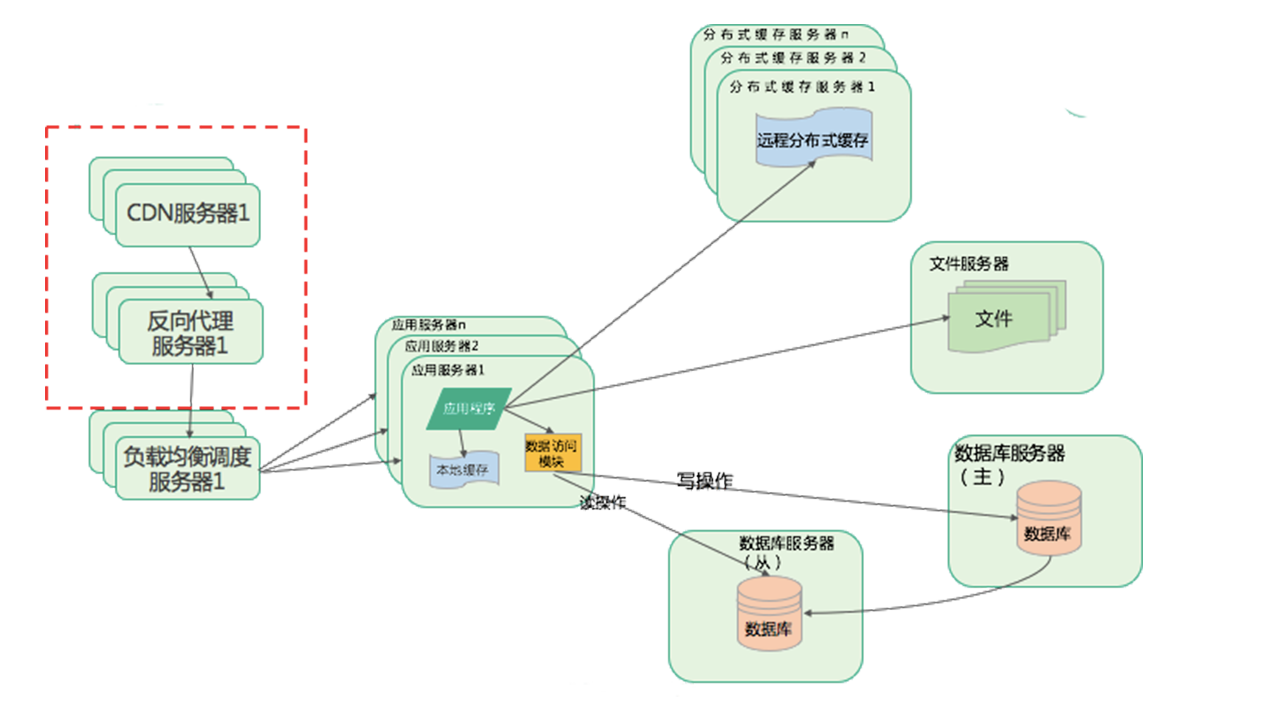
如上图,先经过CDN查询数据,没有进入反向代理服务器,再没有就通过负载均衡服务器调度到对应的应用服务器。
分布式DB和文件系统
有了CDN和反向代理后,可以缓存了大量的用户数据,但是随着用户量的增加,还是有很多用户请求会到达数据中心,这时候文件系统和数据库系统依然会成为瓶颈点,继续如何优化呢?
此时引入了分布式数据库和分布式文件服务器。如下图:
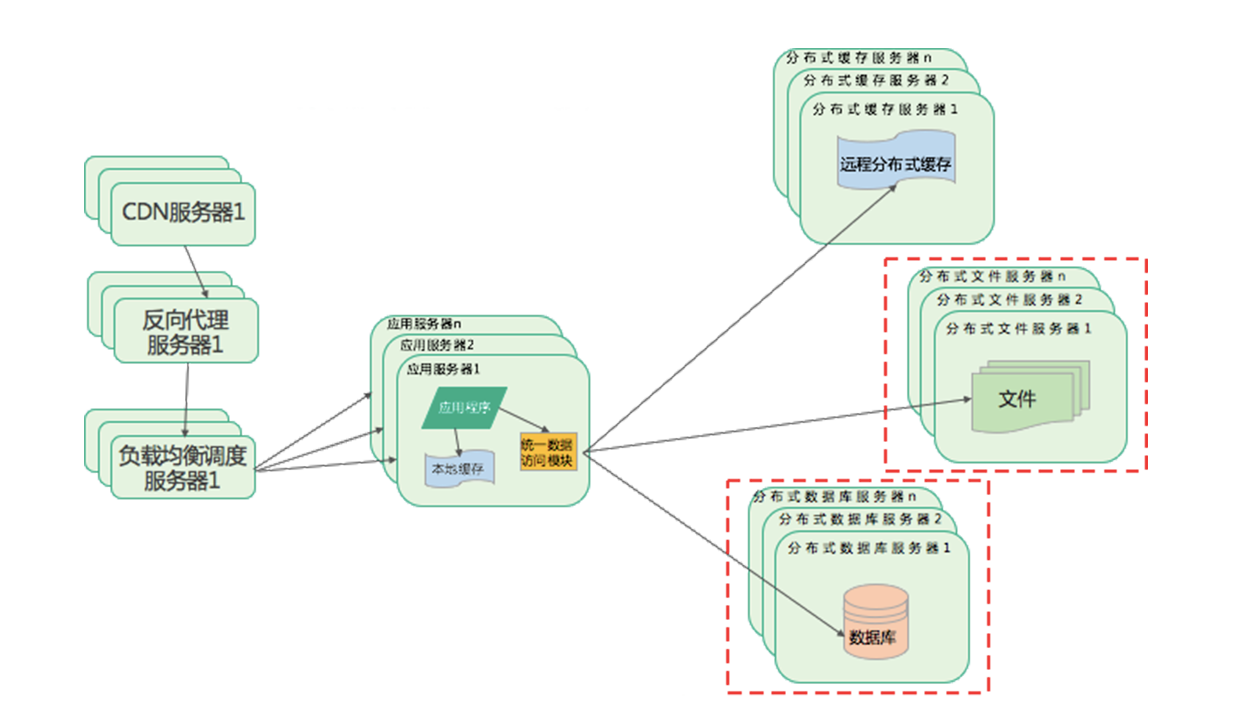
比如微信朋友圈、qq空间,每天都有大量的文件需要进行存储和管理。就需要一个分布式文件服务器进行管理。
主从数据也扛不住,就上分布式数据库进行水平伸缩,通过数据分片的方式,将一张表的数据分布到多个物理服务器上面,减少单一服务器的访问压力,进一步提升系统的处理能力。
消息队列和分布式服务
最终,也就是现在的架构形态,就是采用各种消息队列进行业务解耦,每个业务都部署在不同的应用服务器上面,引用大量的主键来加强巩固整体架构的并发访问与快速响应的能力,比如使用ES进行搜索,使用NoSQL进行缓存,使用微服务进行拆分业务等等。将各种可复用的业务分离开来,部署在不同的服务器集群上面。
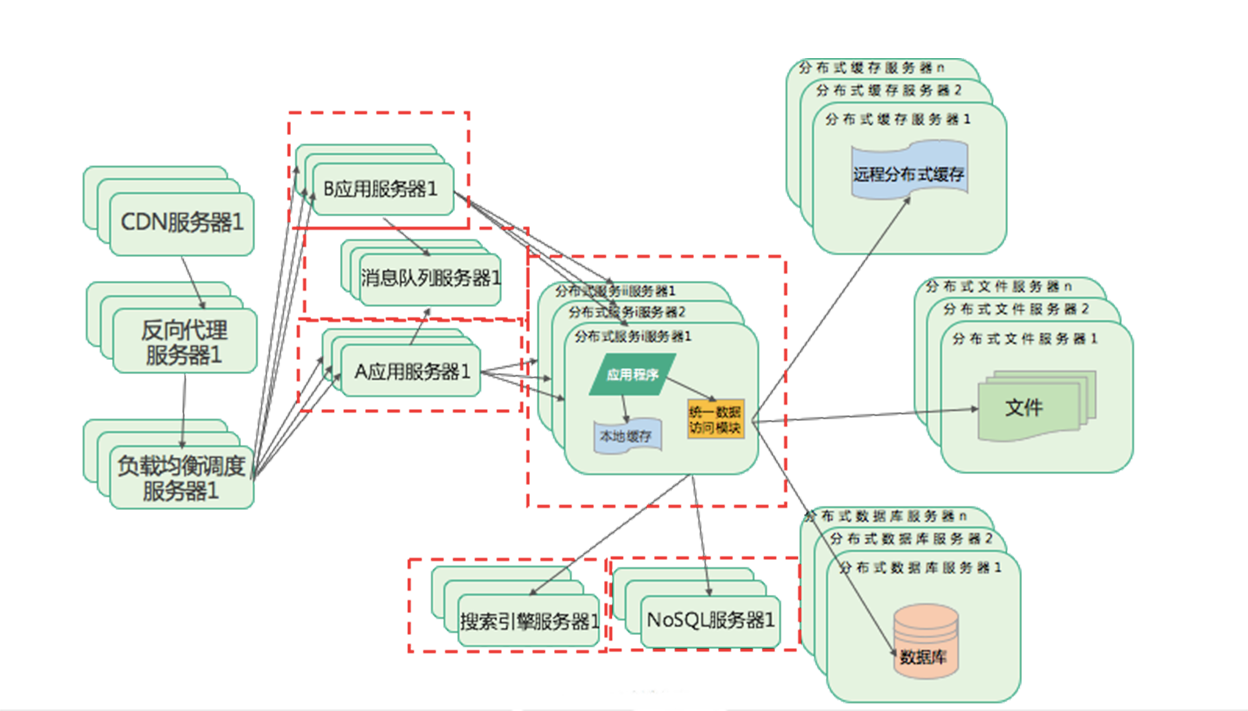
因为随着用户量增加,伴随着业务复杂度的增加,比如微信最开始也就是一个IM即时聊天的功能,后续增加了朋友圈、周边人到现在的整个庞大的微信体系,甚至搭建小程序成为一个系统平台,整体的复杂度是成指数倍的增加,使用分布式消息队列和分布式服务,也是解决业务增加时系统的复杂度问题,使用消息进行通信,并非直接服务调用的方式,各个业务进行拆分、解耦,使得各个独立的服务变得简单,来尽可能不由于某个业务奔溃导致整体系统不能访问。
总结
首先,大型互联网系统的挑战主要包括:高并发和大流量请求的挑战,高可用的挑战,海量数据的挑战,网络情况复杂、安全性差的挑战,以及需求快速变更、发布频繁的挑战。为了应对这样的挑战,需要提升系统的处理能力。处理能力提升有两种手段,一种是垂直伸缩,一种是水平伸缩。垂直伸缩有自身的局限性,所以在互联网企业中主要使用的手段是水平伸缩。
水平伸缩的原理就是不断地增加服务器以提高系统的处理能力。而如何添加新服务器,使新的服务器和原有的服务器构成一个完整的整体对外提供服务,就是互联网架构的主要技术挑战和技术内容。
在应对挑战的过程中,互联网架构主要的应对方法,就是从单机系统到分布式系统。即通过服务器拆分的方式,系统架构从单机系统一个服务器变成很多个服务器。这是整个发展思路以及发展过程。
其中最主要的发展阶段包括:
- 使用分布式的缓存,提高系统的访问特性,减少数据存储的压力;
- 使用负载均衡,提供更多的应用服务器提高系统计算处理能力;
- 使用分布式存储,提供更多的服务器,分摊数据的读写压力;
- 使用微服务与异步架构,使系统变得更加低耦合,使应用业务变得更加可复用,提升业务处理能力,从而支撑起一个大型网站系统架构。

