
介绍常见数据结构底层实现原理以及使用时候的坑。
数组
首先,Go 语言的数组是一种值类型,虽然数组的元素可以被修改,但是数组本身的赋值和函数传参都是以整体复制的方式处理的。
数组是由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。数组的长度是数组类型的组成部分。因为数组的长度是数组类型的一个部分,不同长度或不同类型的数据组成的数组都是不同的类型,因此在 Go 语言中很少直接使用数组(不同长度的数组因为类型不同无法直接赋值)大部分情况下,都是使用切片。因为切片是可以动态增长和收缩的序列,切片的功能也更加灵活,但是要理解切片的工作原理还是要先理解数组。
定义
一般数组有如下定义:
var a [3]int // 1:定义长度为 3 的 int 型数组, 元素全部为 0
var b = [...]int{1, 2, 3} // 2:定义长度为 3 的 int 型数组, 元素为 1, 2, 3
var c = [...]int{2: 3, 1: 2} // 3:定义长度为 3 的 int 型数组, 元素为 0, 2, 3
var d = [...]int{1, 2, 4: 5, 6} // 4:定义长度为 6 的 int 型数组, 元素为 1, 2, 0, 0, 5, 6
- 1:为基本的定义,数组长度明确指定,但此时数组中每个元素都是类型的零值初始化,如果是字符串就是空。
- 2:顺带着把值初始化了,数组的长度是根据初始化元素的数目,自动计算。
- 3:通过索引的方式进行初始化值,可以看出初始化的顺序并非讲究,没有说要从0开始,但是数组的长度是最大的索引为准,没有明确的初始化元素,依然是零值初始化。
- 4:混合了第二种和第三种方式,前面采用两个元素顺序初始化,第三个元素4:5表示index4上面为5,那么index为1/2就是零值。建议不要这种方式,会被竖中指的。
刚刚也说了,是有固定长度组成的连续内存空间,所以内存结构也是比较简单,比如下面是[4]int{2,3,5,7} 数组值对应的内存结构:
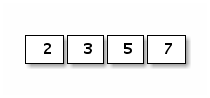
Go 语言中数组是值语义。一个数组变量即表示整个数组,它并不是隐式的指向第一个元素的指针(比如 C 语言的数组),而是一个完整的值。当一个数组变量被赋值或者被传递的时候,实际上会复制整个数组。如果数组较大的话,数组的赋值也会有较大的开销。为了避免复制数组带来的开销,可以传递一个指向数组的指针,但是数组指针并不是数组。
var a = [...]int{1, 2, 3} // a 是一个数组
var b = &a // b 是指向数组的指针
fmt.Println(a[0], a[1]) // 1 2 打印数组的前 2 个元素
fmt.Println(b[0], b[1]) // 1 2 通过数组指针访问数组元素的方式和数组类似
b[0] = -1
for i, v := range b { // 通过数组指针迭代数组的元素
fmt.Println(i, v) // -1,2,3
}
其中 b 是指向 a 数组的指针,但是通过 b 访问数组中元素的写法和 a 类似的。还可以通过 for range 来迭代数组指针指向的数组元素。其实数组指针类型除了类型和数组不同之外,通过数组指针操作数组的方式和通过数组本身的操作类似,而且数组指针赋值时只会拷贝一个指针。但是数组指针类型依然不够灵活,因为数组的长度是数组类型的组成部分,指向不同长度数组的数组指针类型也是完全不同的。
还是要说固定长度,比如上面定义为 var a = [...]int{1, 2, 3} 如果增加 a[3]=4 是会报错,编译不过去的 out of bounds for the element array。 这个特别是用惯了切片的同学,要注意了。
遍历
我们使用下面常用的几种方式来遍历数组。
// 1:迭代器
for i := range a {
fmt.Printf("a[%d]: %d\n", i, a[i])
}
// 2:迭代器下标
for i, v := range b {
fmt.Printf("b[%d]: %d\n", i, v)
}
// 3:for循环下标
for i := 0; i < len(c); i++ {
fmt.Printf("c[%d]: %d\n", i, c[i])
}
建议使用迭代器的方式来遍历数组,因为性能会更好一点,不会出现数组越界的情况,每轮迭代对数组元素的访问时可以省去对下标越界的判断。
存储类型
数组不仅仅可以用于数值类型,还可以定义字符串数组、结构体数组、函数数组、接口数组、管道数组等
// 字符串数组
var s1 = [2]string{"hello", "world"}
var s2 = [...]string{"你好", "世界"}
var s3 = [...]string{1: "世界", 0: "你好", }
// 结构体数组
var line1 [2]image.Point
var line2 = [...]image.Point{image.Point{X: 0, Y: 0}, image.Point{X: 1, Y: 1}}
var line3 = [...]image.Point{{0, 0}, {1, 1}}
// 图像解码器数组
var decoder1 [2]func(io.Reader) (image.Image, error)
var decoder2 = [...]func(io.Reader) (image.Image, error){
png.Decode,
jpeg.Decode,
}
// 接口数组
var unknown1 [2]interface{}
var unknown2 = [...]interface{}{123, "你好"}
// 管道数组
var chanList = [2]chan int{}
还可以定义空数组:
var d [0]int // 定义一个长度为 0 的数组
var e = [0]int{} // 定义一个长度为 0 的数组
var f = [...]int{} // 定义一个长度为 0 的数组
为什么会有长度为0的数组,有什么意义?建个茅坑不拉屎的。 其实空数组虽然很少用,但是可以用于强调某种特有类型的操作时,避免分配额外的内存空间,一般情况下,是用于管道的同步操作,如:
c1 := make(chan [0]int)
go func() {
fmt.Println("c1")
c1 <- [0]int{}
}()
<-c1
因为根本就不关心管道中传输数据的真实类型,只是用于消息的同步。对于这种场景,我们可以用空数组来代替管道类型,减少管道元素赋值时的开销,当然咯,目前用的多的,更加建议使用无类型的匿名结构体来代替,如:
c2 := make(chan struct{})
go func() {
fmt.Println("c2")
c2 <- struct{}{} // struct{} 部分是类型, {} 表示对应的结构体值
}()
<-c2
在 Go 语言中,数组类型是切片和字符串等结构的基础。以上数组的很多操作都可以直接用于字符串或切片中。
使用的坑
数组是值传递的,无法通过修改数组类型的参数返回结果,如果有这个需求,要么使用指针,要么使用切片。
func main() {
var a = [...]int{1, 2, 3}
testArr(a)
fmt.Println(a) // 1,2,3
}
func testArr(arr [3]int) {
arr[0] = -1
fmt.Println(arr) //-1,2,3
}
字符串
Go 语言字符串底层数据对应的字节数组,但是字符串的只读属性禁止了在程序中对底层字节数组的元素的修改。字符串赋值只是复制了数据地址和对应的长度,而不会导致底层数据的复制。
一个字符串时一个不可改变的字节序列,字符串通常是来包含人类可读的文本数据。
这意味着一旦创建了一个字符串,就无法直接修改它的内容。Go 中的字符串是由字节组成的不可变序列,而且字符串的内容在创建后不能被修改。当你尝试修改字符串时,实际上是创建了一个新的字符串。
和数组不一样的是,字符串的元素不可修改,是一个只读的字节数组,每个字符串的长度虽然固定 ,但是字符串的长度并不是字符串类型的一部分。由于Go语言的源码要求是UTF8编码,导致Go源码中出现的字符串面值常量一般也是UTF8编码。
源代码中的文本字符串通常被解释为采用 UTF8 编码的 Unicode 码点(rune)序列。因为字节序列对应的是只读的字节序列,因此字符串可以包含任意的数据,包括 byte 值 0。我们也可以用字符串表示 GBK 等非 UTF8 编码的数据,不过这种时候将字符串看作是一个只读的二进制数组更准确,因为 for range 等语法并不能支持非 UTF8 编码的字符串的遍历。
底层结构
str := "hello,world;"
fmt.Printf("%p\n", &str) // 0xc000052250
str = "hello"
fmt.Printf("%p", &str) // 0xc000052250
不是说,修改内容是相当于创建了新的字符串码?为什么这两个地址是一样的呢?这个和java有什么区别吗?
客观别急,这就涉及到底层结构了。
Go 语言字符串的底层结构在 reflect.StringHeader 中定义:
type StringHeader struct {
Data uintptr
Len int
}
- Data是字符串指向的底层字节数组
- Len是字符串的字节的长度
在 Go 语言中,字符串是不可变的,但底层的字节数组是可变的。当你创建一个字符串时,实际上创建了一个不可变的字节序列,但是这个字节序列对应的底层字节数组是可以在不改变原始字符串的情况下被修改的。 我们看完底层结构可以得知,虽然字符串本身不可变,但是可以通过切片操作获得一个新的字符串,这个新字符串可能会共享底层的字节数组。
字符串其实是一个结构体,因此字符串的赋值操作也就是 reflect.StringHeader 结构体的复制过程,并不会涉及底层字节数组的复制。
比如字符串"Hello,world"本身对应的内存结构:
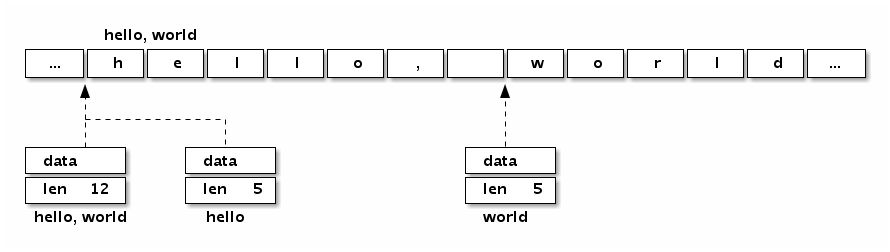
分析可以发现,“Hello, world”字符串底层数据和以下数组是完全一致的:
var data = [...]byte{
'h', 'e', 'l', 'l', 'o', ',', ' ', 'w', 'o', 'r', 'l', 'd',
}
字符串虽然不是切片,但是支持切片操作,不同位置的切片底层也访问的同一块内存数据(因为字符串是只读的,相同的字符串面值常量通常是对应同一个字符串常量):
s := "hello, world"
hello := s[:5]
world := s[7:]
// 骚操作
s1 := "hello, world"[:5]
s2 := "hello, world"[7:]
“Hello, 世界”字符串的内存结构布局:

Go 语言的字符串中可以存放任意的二进制字节序列,而且即使是 UTF8 字符序列也可能会遇到坏的编码。如果遇到一个错误的 UTF8 编码输入,将生成一个特别的 Unicode 字符‘\uFFFD’,这个字符在不同的软件中的显示效果可能不太一样,在印刷中这个符号通常是一个黑色六角形或钻石形状,里面包含一个白色的问号‘�’。
下面的字符串中,我们故意损坏了第一字符的第二和第三字节,因此第一字符将会打印为“�”,第二和第三字节则被忽略,后面的“abc”依然可以正常解码打印(错误编码不会向后扩散是 UTF8 编码的优秀特性之一)。
fmt.Println("\xe4\x00\x00\xe7\x95\x8cabc") // �界abc
打印
根据 Go 语言规范,Go 语言的源文件都是采用 UTF8 编码。因此,Go 源文件中出现的字符串面值常量一般也是 UTF8 编码的(对于转义字符,则没有这个限制)。提到 Go 字符串时,我们一般都会假设字符串对应的是一个合法的 UTF8 编码的字符序列。可以用内置的 print 调试函数或 fmt.Print 函数直接打印,也可以用 for range 循环直接遍历 UTF8 解码后的 Unicode 码点值。
下面的“Hello, 世界”字符串中包含了中文字符,可以通过打印转型为字节类型来查看字符底层对应的数据:
fmt.Printf("%#v\n", []byte("Hello, 世界"))
//[]byte{0x48, 0x65, 0x6c, 0x6c, 0x6f, 0x2c, 0x20, 0xe4, 0xb8, 0x96, 0xe7, 0x95, 0
//x8c}
分析可以发现0xe4, 0xb8, 0x96对应中文“世”,0xe7, 0x95, 0x8c对应中文“界”。我们也可以在字符串面值中直指定 UTF8 编码后的值(源文件中全部是 ASCII 码,可以避免出现多字节的字符)。
fmt.Println("\xe4\xb8\x96") // 打印: 世
fmt.Println("\xe7\x95\x8c") // 打印: 界
由于遍历的是码点值,所以我们如果这么遍历的话,是不能达到效果的:
str := "hello,world;"
for _, i := range str {
fmt.Print(i) //104 101 108 108 111 44 119 111 114 108 100 59
}
for i := 0; i < len(str); i++ {
fmt.Print(str[i]) //104 101 108 108 111 44 119 111 114 108 100 59
}
所以,如果想要单个把字符拿出来的话,应该是这样的:
for _, char := range str {
//fmt.Printf("%c ", char)
s := fmt.Sprintf("%c", char)
fmt.Println(s)
}
这个比其他语言要稍微麻烦点。
切片
切片的行为更为灵活,切片的结构和字符串结构类似,但是解除了只读限制。切片的底层数据虽然也是对应数据类型的数组,但是每个切片还有独立的长度和容量信息,切片赋值和函数传参数时也是将切片头信息部分按传值方式处理。因为切片头含有底层数据的指针,所以它的赋值也不会导致底层数据的复制。
简单地说,切片就是一种简化版的动态数组。因为动态数组的长度是不固定,切片的长度自然也就不能是类型的组成部分了。数组虽然有适用它们的地方,但是数组的类型和操作都不够灵活,因此在 Go 代码中数组使用的并不多。而切片则使用得相当广泛,理解切片的原理和用法是一个 Go 程序员的必备技能。
定义
一般来说,切片有如下定义:
var (
a []int // nil 切片, 和 nil 相等, 一般用来表示一个不存在的切片
b = []int{} // 空切片, 和 nil 不相等, 一般用来表示一个空的集合
c = []int{1, 2, 3} // 有 3 个元素的切片, len 和 cap 都为 3
d = c[:2] // 有 2 个元素的切片, len 为 2, cap 为 3
e = c[0:2:cap(c)] // 有 2 个元素的切片, len 为 2, cap 为 3
f = c[:0] // 有 0 个元素的切片, len 为 0, cap 为 3
g = make([]int, 3) // 有 3 个元素的切片, len 和 cap 都为 3
h = make([]int, 2, 3) // 有 2 个元素的切片, len 为 2, cap 为 3
i = make([]int, 0, 3) // 有 0 个元素的切片, len 为 0, cap 为 3
)
在工作中,我们常用的都是 g = make([]int, 3) 在知道切片的确切长度下,尽量使用初始化定义长度来初始化。
刚刚数组说过,数组是值传递,但是切片是引用传递,如:
func main() {
var arr []int
arr = append(arr, 1, 2, 3, 4)
testArr(arr)
fmt.Println(arr) //[-1 2 3 4]
}
func testArr(arr []int) {
arr[0] = -1
fmt.Println(arr) //[-1 2 3 4]
}
底层结构
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
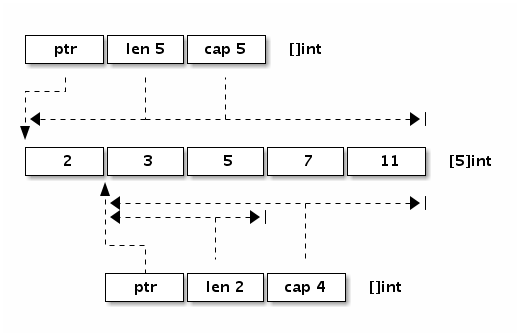
可以看出切片的开头部分和 Go 字符串是一样的,但是切片多了一个 Cap 成员表示切片指向的内存空间的最大容量(对应元素的个数,而不是字节数)。
下图是 x := []int{2,3,5,7,11} 和 y := x[1:3] 两个切片对应的内存结构。
遍历
遍历切片的方式和遍历数组的方式类似:
for i := range a {
fmt.Printf("a[%d]: %d\n", i, a[i])
}
for i, v := range b {
fmt.Printf("b[%d]: %d\n", i, v)
}
for i := 0; i < len(c); i++ {
fmt.Printf("c[%d]: %d\n", i, c[i])
}
其实除了遍历之外,只要是切片的底层数据指针、长度和容量没有发生变化的话,对切片的遍历、元素的读取和修改都和数组是一样的。在对切片本身赋值或参数传递时,和数组指针的操作方式类似,只是复制切片头信息(reflect.SliceHeader),并不会复制底层的数据。对于类型,和数组的最大不同是,切片的类型和长度信息无关,只要是相同类型元素构成的切片均对应相同的切片类型。
如前所说,切片是一种简化版的动态数组,这是切片类型的灵魂。除了构造切片和遍历切片之外,添加切片元素、删除切片元素都是切片处理中经常遇到的问题。
添加
内置的泛型函数 append 可以在切片的尾部追加 N 个元素:
var a []int
a = append(a, 1) // 追加 1 个元素
a = append(a, 1, 2, 3) // 追加多个元素, 手写解包方式
a = append(a, []int{1,2,3}...) // 追加 1 个切片, 切片需要解包
不过要注意的是,在容量不足的情况下,append 的操作会导致重新分配内存,可能导致巨大的内存分配和复制数据代价。即使容量足够,依然需要用 append 函数的返回值来更新切片本身,因为新切片的长度已经发生了变化。
当然,我们还可以再头部进行添加。
var a = []int{1,2,3}
a = append([]int{0}, a...) // 在开头添加 1 个元素
a = append([]int{-3,-2,-1}, a...) // 在开头添加 1 个切片
如何实现队列和栈,不用多说了吧。
虽然,在开头一般都会导致内存的重新分配,而且会导致已有的元素全部复制 1 次。因此,从切片的开头添加元素的性能一般要比从尾部追加元素的性能差很多。
注意的是,在容量不足的情况下,append 的操作会导致重新分配内存,可能导致巨大的内存分配和复制数据代价。即使容量足够,依然需要用 append 函数的返回值来更新切片本身,因为新切片的长度已经发生了变化。
由于 append 函数返回新的切片,也就是它支持链式操作。我们可以将多个 append 操作组合起来,实现在切片中间插入元素:
var a []int
a = append(a[:i], append([]int{x}, a[i:]...)...) // 在第 i 个位置插入 x
a = append(a[:i], append([]int{1,2,3}, a[i:]...)...) // 在第 i 个位置插入切片
每个添加操作中,都会创建一个临时切片,并将内容复制到新创建的切片中,然后将临时创建的切片再追加。
删除
根据要删除元素的位置有三种情况:从开头位置删除,从中间位置删除,从尾部删除。
其中删除切片尾部的元素最快:
a = []int{1, 2, 3} a = a[:len(a)-1] // 删除尾部 1 个元素 a = a[:len(a)-N] // 删除尾部 N 个元素删除开头的元素可以直接移动数据指针:
a = []int{1, 2, 3}
a = a[1:] // 删除开头 1 个元素
a = a[N:] // 删除开头 N 个元素
- 也可以用 copy 完成删除开头的元素:
a = []int{1, 2, 3}
a = a[:copy(a, a[1:])] // 删除开头 1 个元素
a = a[:copy(a, a[N:])] // 删除开头 N 个元素
删除中间的元素,
a = []int{1, 2, 3, ...} a = append(a[:i], a[i+1:]...) // 删除中间 1 个元素 a = append(a[:i], a[i+N:]...) // 删除中间 N 个元素 a = a[:i+copy(a[i:], a[i+1:])] // 删除中间 1 个元素 a = a[:i+copy(a[i:], a[i+N:])] // 删除中间 N 个元素
删除开头的元素和删除尾部的元素都可以认为是删除中间元素操作的特殊情况。
切片高效操作的要点是要降低内存分配的次数,尽量保证 append 操作不会超出 cap 的容量,降低触发内存分配的次数和每次分配内存大小。
使用的坑
切片会导致整个底层数组被锁定,底层数组无法释放内存。如果底层数组较大会对内存产生很大的压力。
func main() {
headerMap := make(map[string][]byte)
for i := 0; i < 5; i++ {
name := "/path/to/file"
data, err := ioutil.ReadFile(name)
if err != nil {
log.Fatal(err)
}
headerMap[name] = data[:1]
}
// do some thing
}
解决的方法是将结果克隆一份,这样可以释放底层的数组:
func main() {
headerMap := make(map[string][]byte)
for i := 0; i < 5; i++ {
name := "/path/to/file"
data, err := ioutil.ReadFile(name)
if err != nil {
log.Fatal(err)
}
headerMap[name] = append([]byte{}, data[:1]...)
}
// do some thing
}

