
AI大模型从22年开始火了特别久,有很多的专业名次,所以这次分享我准备花十几分钟时间把这些名词讲清楚并且串起来。
提示词
首先我们知道,大家接触开始应该是从chatgpt发布开始是吧,就是22年的11月份,大家通过这种界面的对话工具去跟大模型对话,去生成我们想要的内容,这里的第一个概念就是提示词,也就是给大模型发过去的这个问题,统一称之为“用户提示词”,那提示词有什么用呢?
提示词:Prompt,是用于大语言模型(LLM)的输入文本,帮助引导LLM生成相应的输出。所以提示词是非常重要的,包括现在的很多大模型应用场景,像Rag、AI Agent,我们都会用到提示词去引导大模型去设置好它的边界,那模型的提示词又分为两类:
- User Prompt【用户提示词】,简单理解为用户的问题输入。
- System Prompt【系统提示词】,大家用过Coze的话就比较了解,这种Dify配置工作流的时候,配置智能体的时候,就会让你设置系统提示词,那系统提示词是什么意思呢?比如:
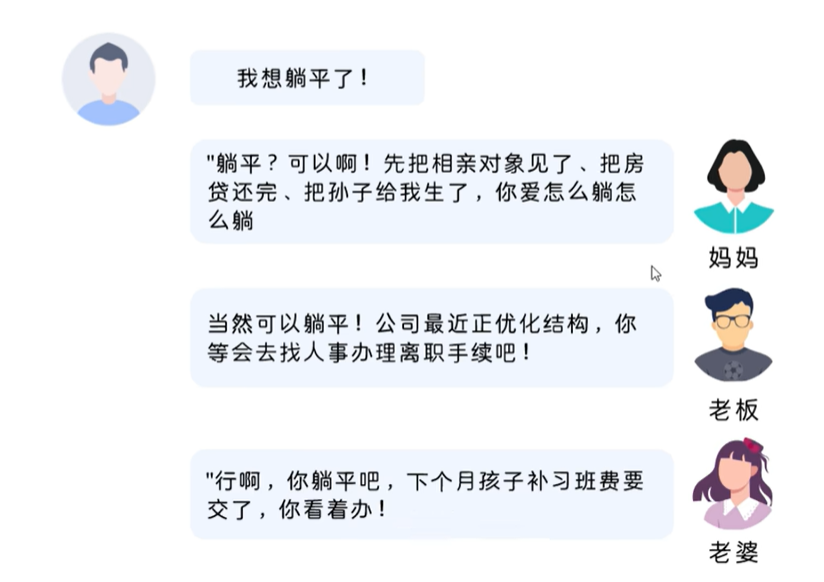
也就是同一个问题,不同的角色它给你的反馈是不一样的,为什么呢?因为每个角色他跟你亲疏关系、他的能力和认知、对你的责任等等都会有差异,这个东西叫做出厂设定,或者是我们叫人物的一个角色本身自带的一个特性,所以这个东西我们叫做系统提示词,我们可以通过某种模型的系统提示词去定义它的角色能力、边界和职责。这样我们去问他对应问题的时候,他会给予他的这个角色给你专业的回答。所以现在大模型就内置很多系统提示词,比如你是客服,就是设定他是客服专家,如果做产品分析,就设定是一个产品分析师,如果是文档分析,那就是文档分析师。也就是让这个模型在某个领域发挥最大的一个能力从而更好的解决我们某个领域的问题。比如下面内置的系统职业:
那有了这个提示词,比如我现在是一个产品经理,现在有一个两万多字的产品文档,想让大模型给我看看这个产品文档里面有没有需要补充修改的地方,是不是意味着把这两万多字的文档全部复制丢到输入框中,他就能回答我的问题了呢?其实这个不一定的,为什么呢?因为模型对于提示词有一个上下文的长度限制,比如下面的就是超长了,就是你的内容超过了上下文窗口的一个大小,就是基于这个模型,请调整你的输入再次尝试。
那提示词的内容要设置多长、能设置多长呢?这取决于对于模型的一个差异,有一个选项叫做上下文长度。以下是截止于今年5月份全球几大厂商的大模型上下文长度,输入的限制。
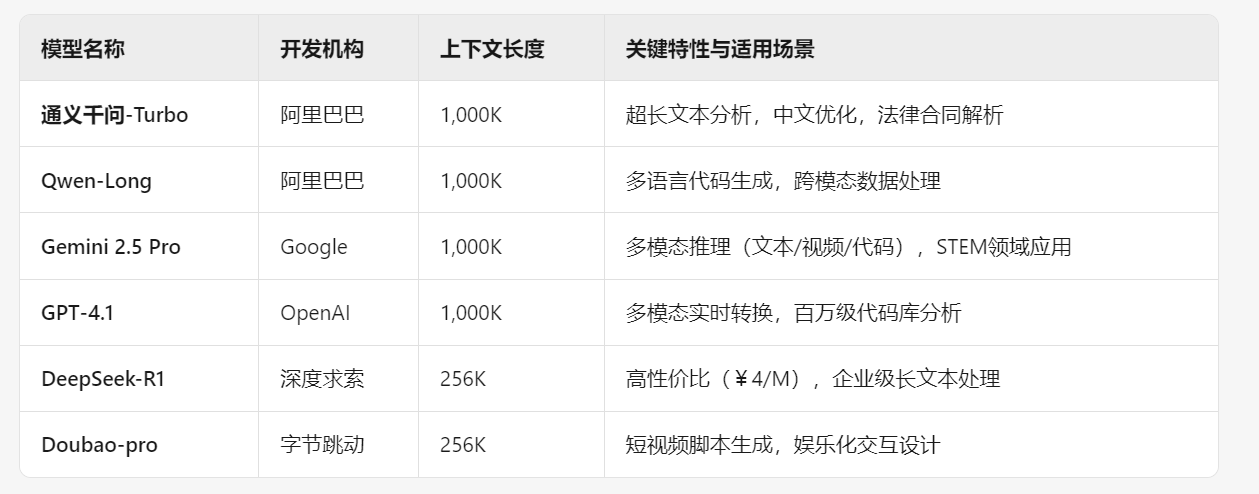
那1000K是什么意思呢?是表示1M的文本大小吗?其实不是,他其实是一个技术名词,也就是我们熟悉的Token,好,现在到了Token阶段。
Token
在大模型里面token是模型处理和理解文本的一个基本单位,模型通过将用户输入文本分割成token,然后在这些token的基础上进行计算和推理。比如下面的:
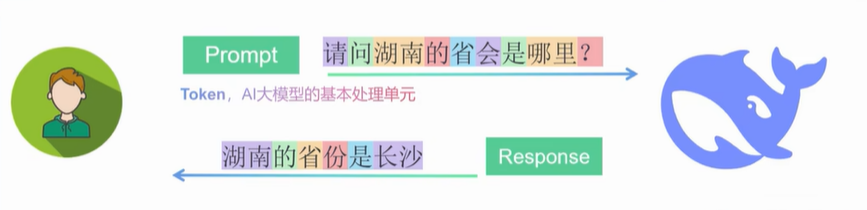
也就是Prompt会分为九个token,然后响应也是分token的,有六个token。我们知道大模型本身的推理就是一个文字接龙游戏,每一个接的就是一个词,一个词一个词的往外蹦,那这个词其实就是我们说的token,不同的模型的token处理方式是不一样的。比如:
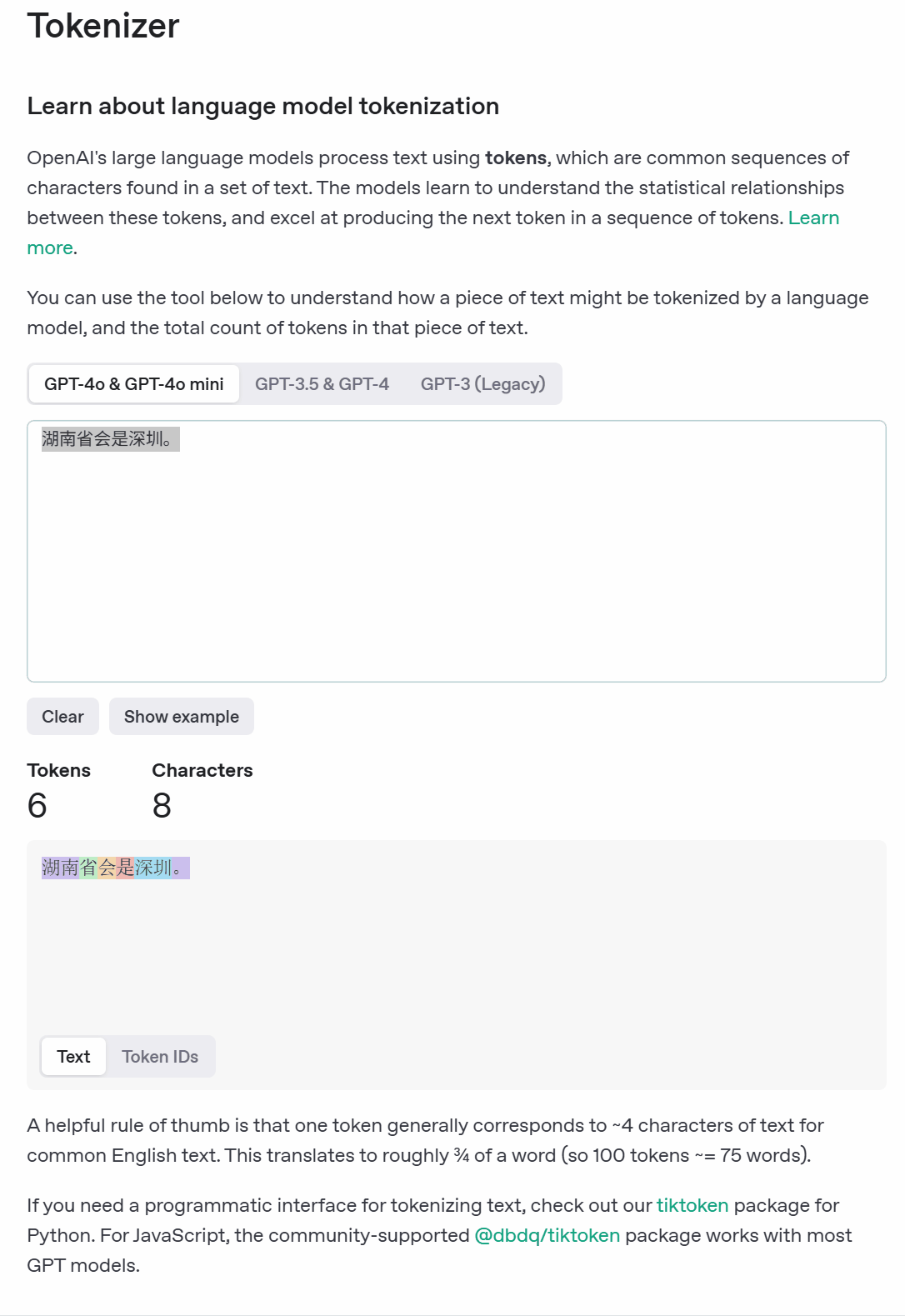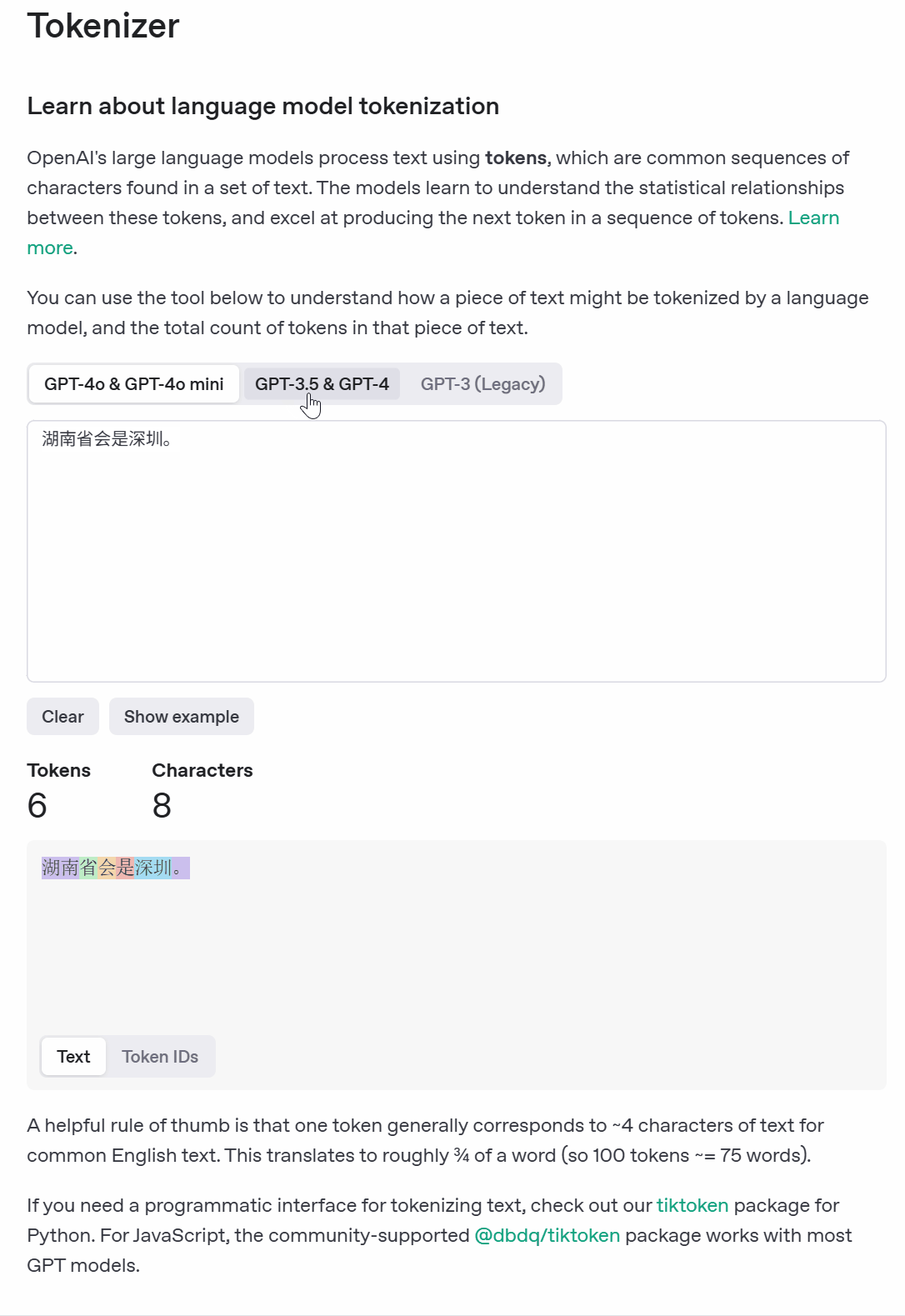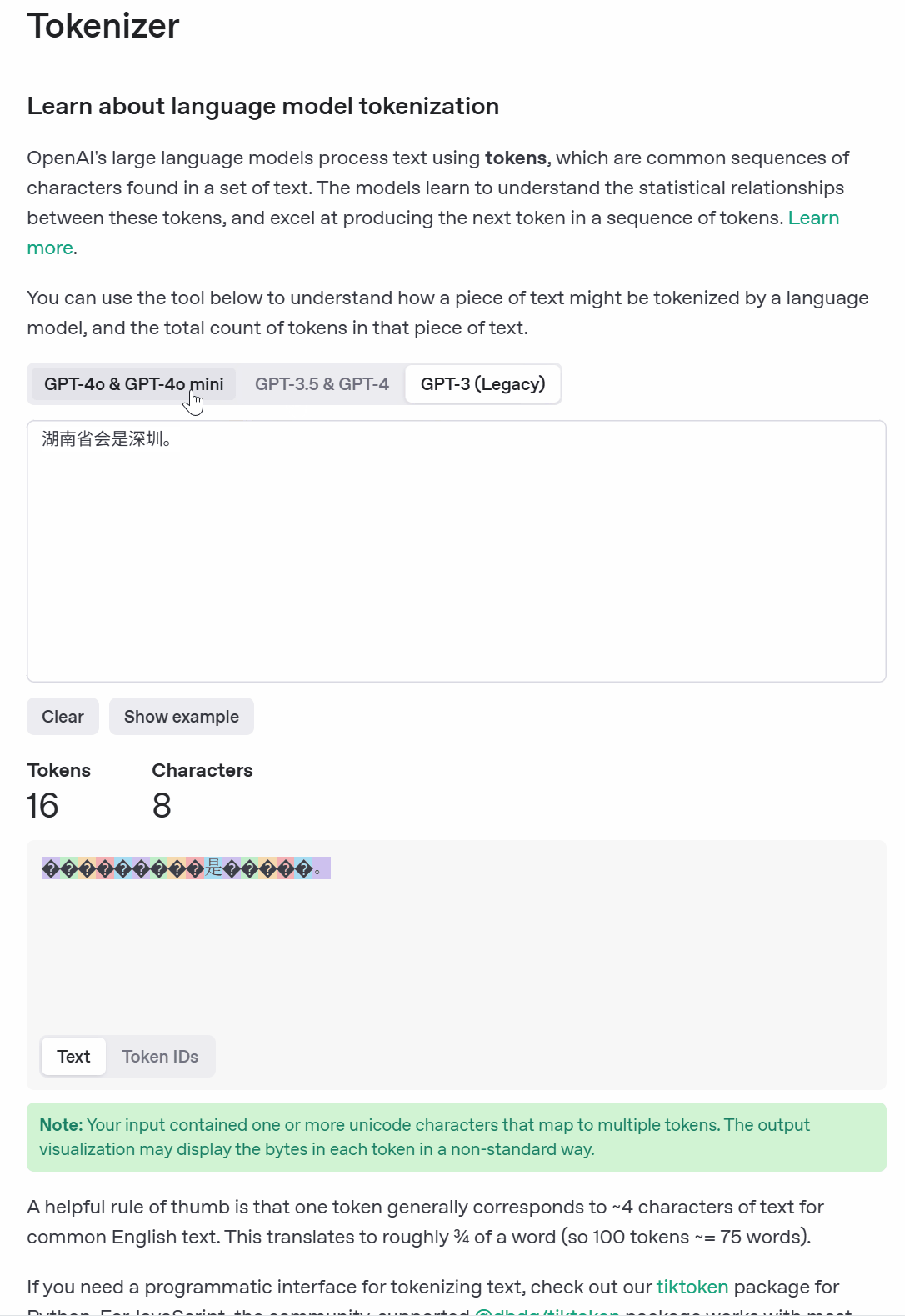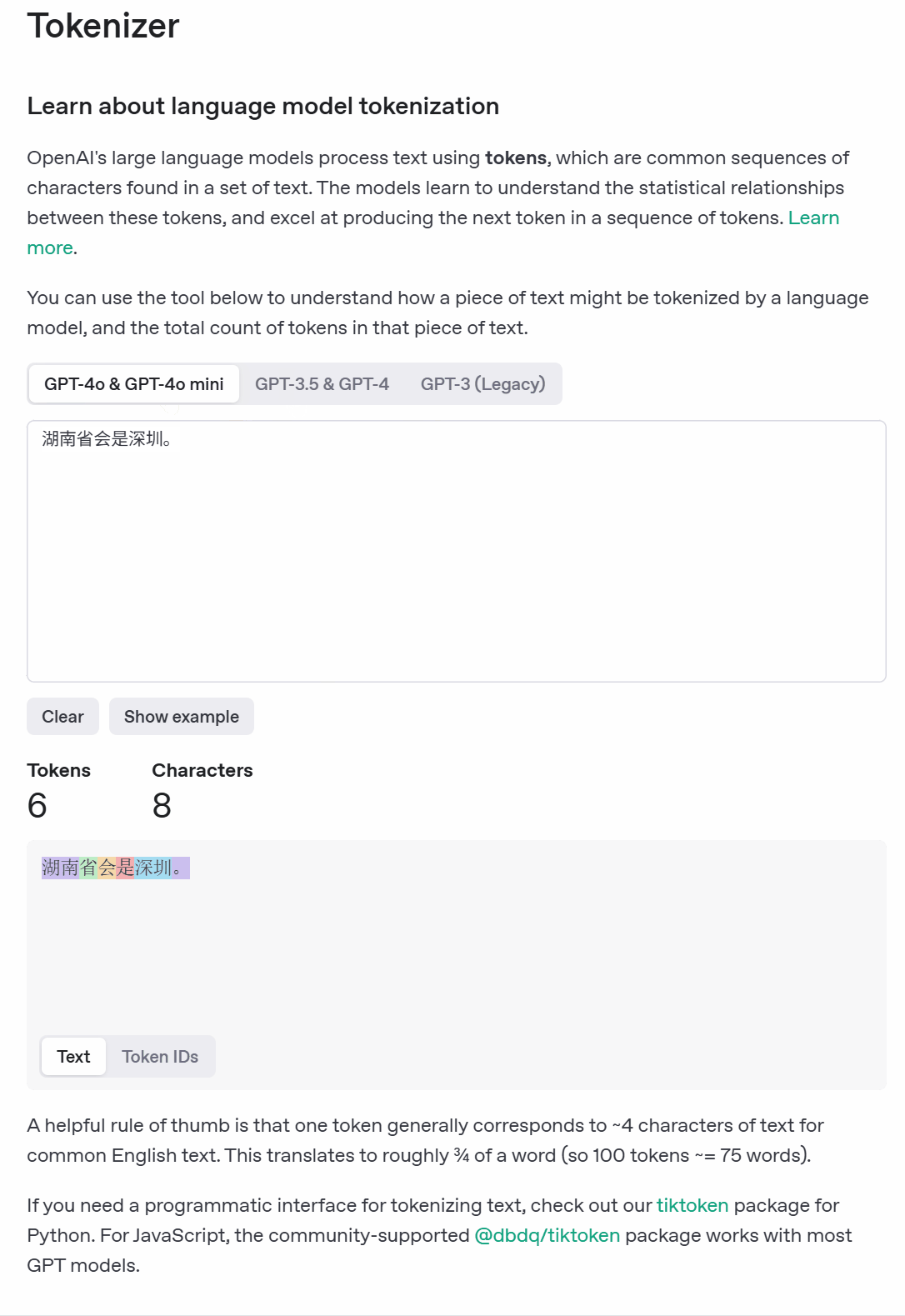
我们大概知道这个概念就好了,因为现在所有的大模型是基于token去计算费用,这个token就是我们的文本数量,一般来说,他会分为两种计费方式,一个是输入的价格,一个是输出的价格,不同模型,他的计费方式也是不同的,如下图:
除了这个之外,还有一个需要注意的,就是我们在做模型选择的时候,会发现有个模型的差异的,比如左边的有7b、32b、72b还有我们熟悉的671B这样的是吧,这些是参数量的数量,那么这个B到底代表什么呢?这个B不是byte,而是billion,十亿的意思,也就是7b就是70亿个参数,32B就是320亿个参数,671B就代表着是6710亿个参数。参数规模对应着智能化,可以简单的理解为一个人读的书越多,你的知识就掌握的更多,你说的话就越有道理,反之读的书少,理解力就更差。
7B(70亿参数)
相当于高中生:能完成基础任务,比如聊天、写简单文章、回答常识问题。
硬件需求低:一台高端游戏电脑(如RTX 3090显卡)就能运行。
典型场景:个人开发者做实验、手机APP里的AI助手(例如写朋友圈文案)。
32B(320亿参数)
相当于大学生:可以处理复杂任务,比如写代码、分析法律合同、生成专业报告。
需要专业设备:需多块高端显卡(如A100服务器),成本高但性能强。
典型场景:企业客服系统、医疗诊断辅助工具。
72B(720亿参数)
相当于博士生:接近人类水平的逻辑推理,能写论文、解决数学难题、创作小说。
依赖超算资源:通常只能在云端使用(如阿里云的Qwen-72B),普通人用不起
我们需要了解这个参数概念的核心,是在于不同场景下的选择,也就是我们选择的参数越大,成本就越高,参数太小的话又无法解决你的问题,所以是需要做好一个平衡,就是性能和成本之间的一个权衡。 deepsee刚出来的时候,steve和我聊过,部署一个R1满血模型大概多少钱,我当时查了下资料,差不多是300-400w左右的成本,好,这里又引出一个概念,什么是满血模型,什么是蒸馏模型。
满血&蒸馏模型
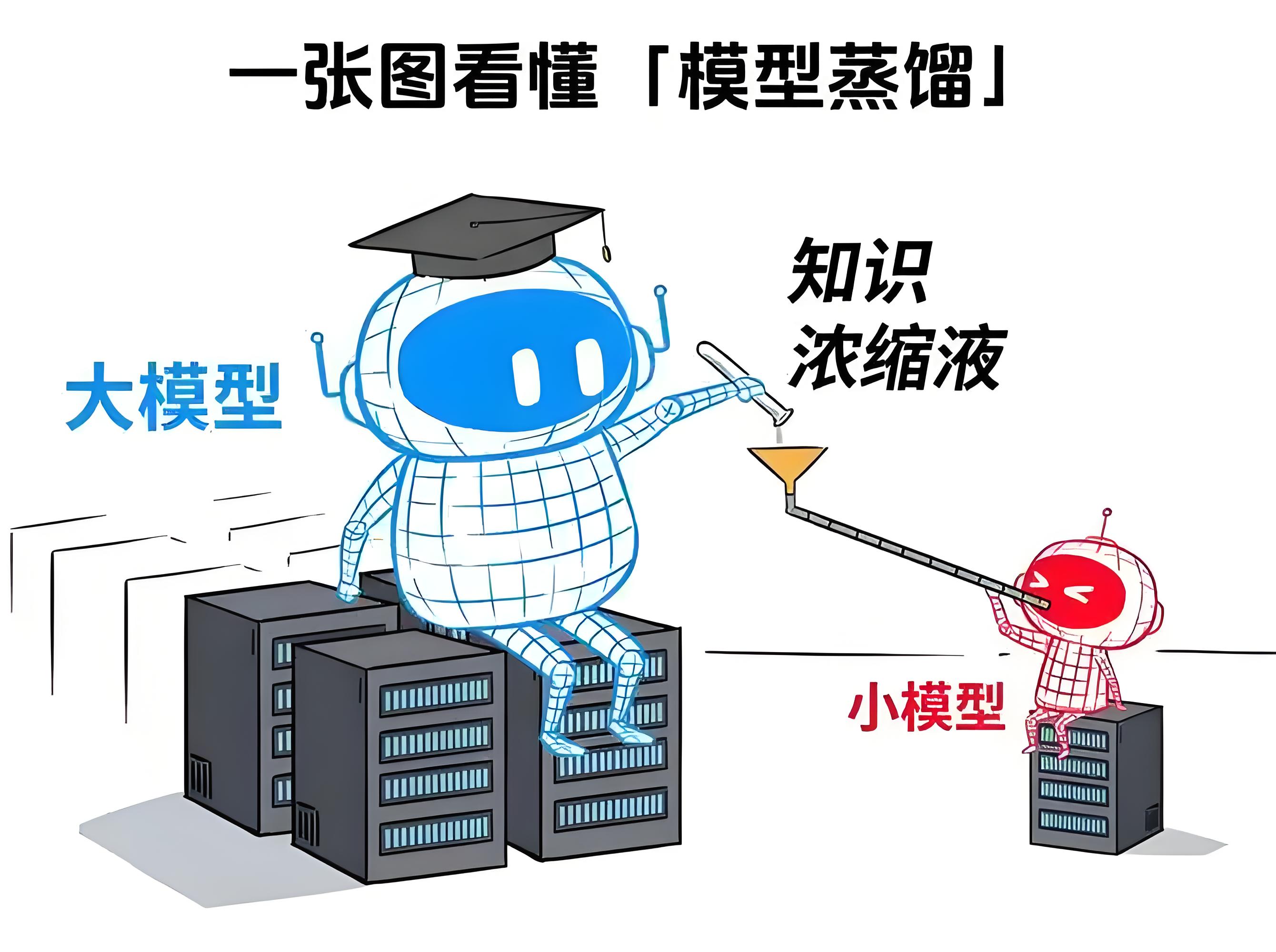
刚刚说了,671B的模型不是一般人或者一般企业可以部署的了的,但是有很多企业为了一些数据的私密性,必须要私有化部署大模型,那么蒸馏的模型是你不错的选择,简单来说,模型蒸馏就是把一个大模型压缩成一个小模型,而且又能够去保证它的智能化水平,怎么理解呢?看下面的图:
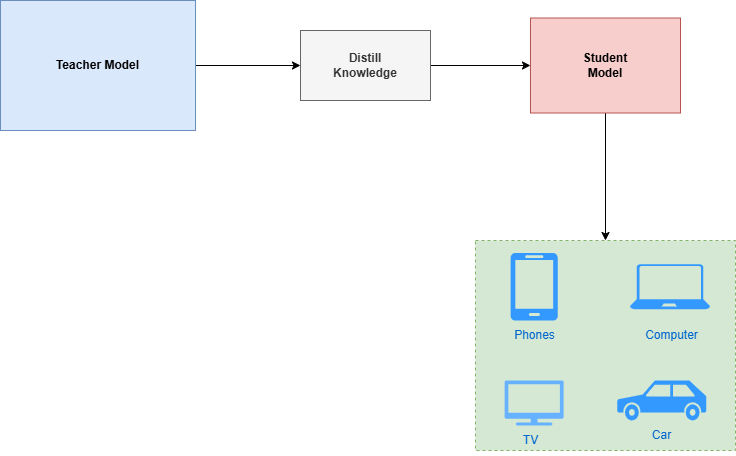
一个标题就是:让学霸老师带出学神学生,模型蒸馏是一种知识迁移技术,旨在将一个复杂、通常性能较高的教师模型所学到的知识,迁移至一个相对简单、规模较小的学生模型。
像上图,想象一下,你有一个超级学霸老师(我们叫他“教师模型”),他上知天文下知地理,解题速度飞快,但唯一的缺点就是——太“胖”了!他需要超级计算机才能跑得动,普通人根本用不起。这时候,你希望培养一个“学神”学生(我们叫他“学生模型”),他不仅要像老师一样聪明,还得轻便灵活,能在手机、电脑、电视甚至小汽车上运行。模型蒸馏,就是这个“学霸”带“学神”的过程。
再理解一下就是我们的菩提老祖,他非常的牛逼,是一个神仙,带出来一个徒弟叫做孙猴子,学的一身本领,人称外号齐天大圣,很厉害,然后部署到唐僧那里去了,保护他们去取经。
那模型蒸馏是怎么蒸馏的呢?
传统的学生模型训练方式是“死记硬背”:给你一堆题目和标准答案(硬标签),你照着学就行了。但模型蒸馏不一样,它让学生模型学习教师模型的“解题思路”。
举个例子:
硬标签:题目“2+2=?”,答案是“4”。
软标签:教师模型不仅告诉你答案是“4”,还会告诉你“3”和“5”也有一定的可能性,只是概率很低。这种概率分布就是“软标签”。
通过软标签,学生模型不仅能学到答案,还能学到教师模型的“思考方式”,比如“2+2”更接近“4”而不是“3”或“5”。这样一来,学生模型的泛化能力更强,面对新题目时也能举一反三。
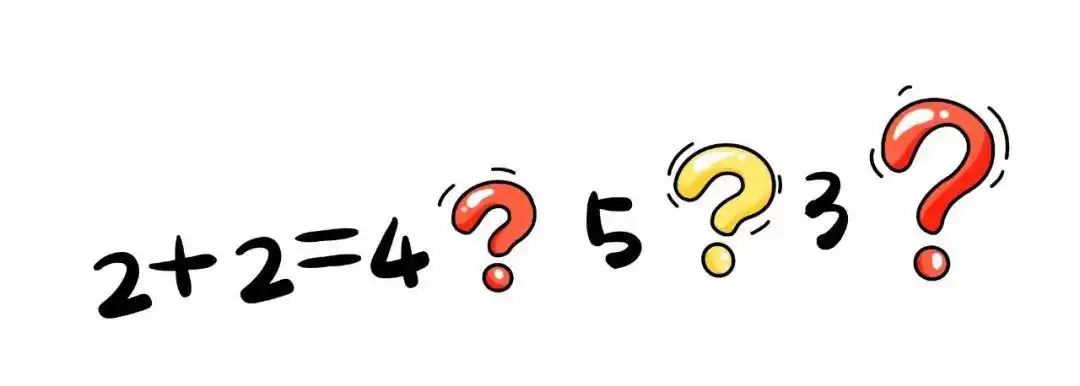
因此,模型蒸馏的过程可以简单分为三步:
1. 拜师:先训练一个超级强大的教师模型。这个模型通常又大又复杂,但性能贼强。
2. 学艺:教师模型对训练数据生成软标签,学生模型通过模仿这些软标签进行训练。
3. 出师:学生模型最终成为一个轻量级但性能接近教师模型的“学神”。
其实蒸馏并非是一个新的概念,而是deepsee活了之后,大家知道、了解这个蒸馏的概念,实际上在2015年就已经提出来这个概念了,那deepseek为什么带火了这个概念呢?是因为他本身就做了这个知识蒸馏的模型,比如下图:
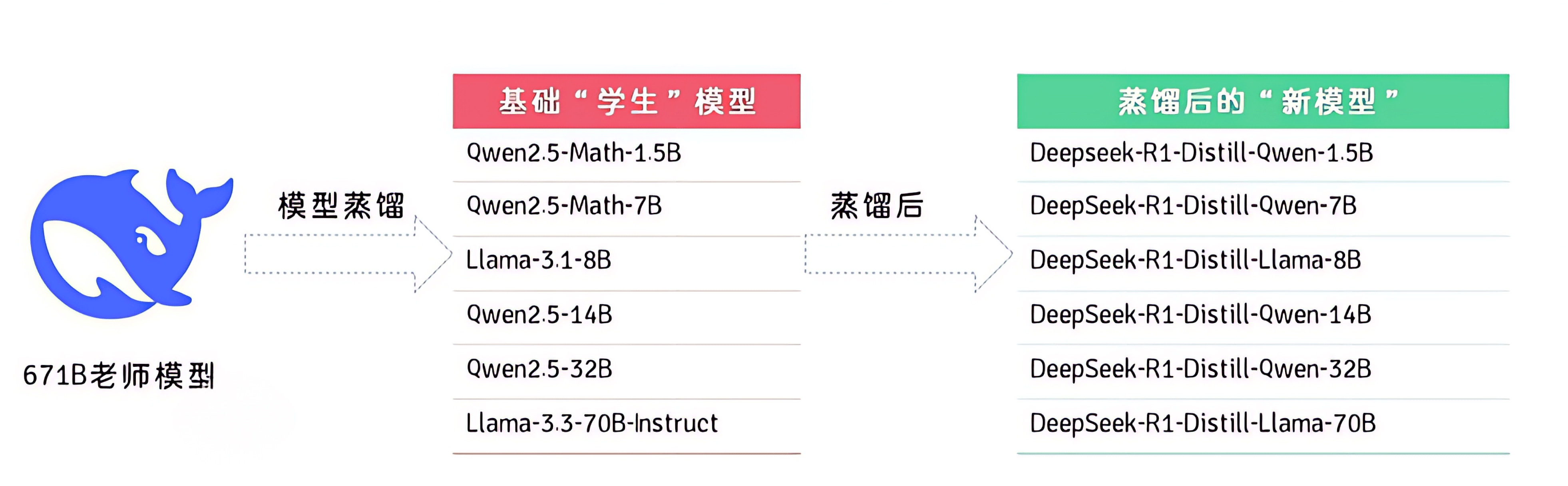
大家可能不知道,deepseek的模型其实就只有一个,就是这个671B的老师模型,满血版的,现在部署的7B、15B等等都是蒸馏模型。还有一些千问、lama的模型和deepseek模型蒸馏之后,也会有一些性能非常强悍的distill模型出来。上次参加一个AI课题讲座,其中有一个大学教授他说他就非常喜欢7B的模型,因为在他自己的笔记本上面也可以跑得起来,在一些弱网或者无网络的情况下也可以进行查资料、创作等等。好了,到这里这个概念也讲完了,以为这就够了?其实还不够,因为无论是什么模型,他都是基于一个静态的数据来做的,也就是问答模式,没办法去解决没有学习过知识,或者更新知识的一个问题,比如举个例子,我问他今天天气,他就不知道。

或者我问他一些私密的,比如我的github上面有多少个开源项目,他就无法去了解,如果只是一个数学的模型,就没办法去更深化的需求了,也就无法去落在更细的层面,那模型就只是变成了问答模式,就无法变现了,那怎么去解决这个问题?如果大模型可以连接外部的工具,那就好了是吧,好,那function calling来了。
function calling & MCP协议
最早这个概念是OpenAI提出来的,也就是Function Calling 是一种实现大型语言模型连接外部工具的机制,比如有了function calling之后,再问他一个问题,他就会告诉你了:

这其实就是大模型去通过function calling,去调取比如墨迹天气的接口,然后再反馈给你,虽然高大上其实很简单,就是一个函数的调用而已。当然现在改名字了,现在叫做 tool_choice。 我们看看这张图,大概可以了解下他是怎么进行调用的。
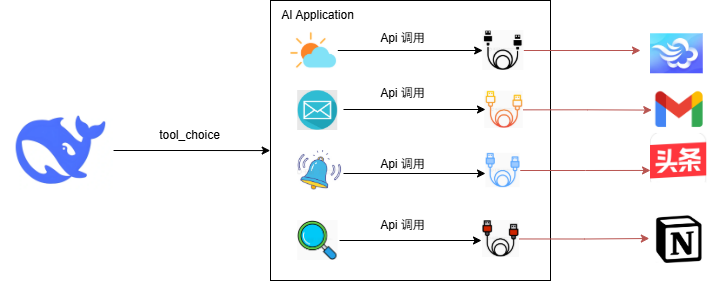
也就是后面AI大模型接入了很多很多的工具,比如天气预报就去调用墨迹天气的接口、邮件就去调用google邮箱的接口、新闻就去头条是吧,然后文档搜索就去Notion之类的,但是可以看出,大家提供的接口,协议都是五花八门的,没有统一,这样大模型去和公司内部或者外部工具对接,需要写很多的安全性、健全性等等差异化代码,都是一些重复性的工作,其实刚刚也看到了,不同的平台,链接的“数据线”都是不同类型的,那么前面的tool choice都是大挑战,一个大模型如果想要更好的生态的发展,或者在使用上面变得更简单的话,是需要有一套同意的协议的,好,这个协议就是MCP协议。
比如现在有了MCP协议之后,大模型只需要去调用MCP客户端就行,其他的统一放到MCP Server上面去管理,如:
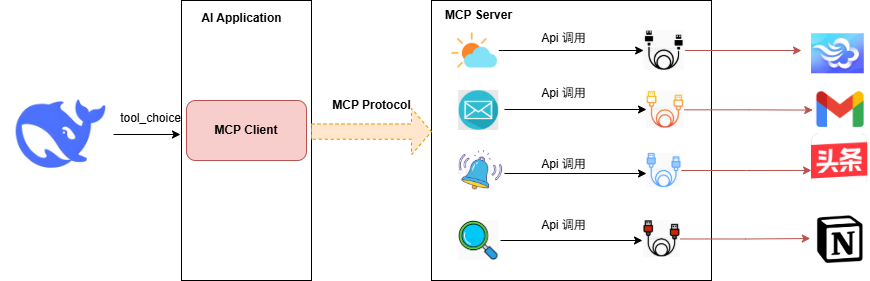
举个例子,公司内部有几十上百个系统,每个系统都需要用到账号体系、支付、第三方登录等等,而这些功能可能是java、go、php写的,如果你需要用到的话,用原生语言去调用,那对于业务部门来说将是毁灭性的打击,但是如果中台收拢,对外提供服务,然后用http的get、post来请求,这样里面是什么语言来写我根本就不关系,我只是用api的方式来调用,这样就会好理解很多了。
这个MCP怎么去调用,链接等等,我们在这就不赘述了,之前也有同事分享过。
MCP的好处:
1. 简化开发:写一次,多次集成,无需为每个集成重新自定义代码。
2. 灵活性:切换AI模型或工具时无需复杂重新配置。
3. 实时响应:MCP链接保持活动状态,实现实时上下文更新和交互。
4. 安全性和合规性:内置访问控制和标准化的安全实践。
5: 可扩展性:随着 AI生态系统增长,轻松添加新功能,只需要链接另一个MCP服务器。
目前为止,我们通过很多概念,让大模型去做很多的事情是吧,但是好像大模型还是只是停留在对话的层面,对话其实只能解决你的内容的生成、搜索的一些问题,但那能不能让大模型自己去干活呢?去做更多的事情呢? 当然经过上一轮的分享,大家其实也知道了,确实是可以的,也就是AIAgen。
AIAgent
比如我最近缺钱,想挣点横财,去买彩票是吧,一般都是要算出最近出的最多的红球和篮球的概率,然后就去弄,一般来说就是去网上搜索,然后统计,但是agent就可以自己帮你处理这个事情了,比如:帮我归纳出近一年双色球开奖结果,统计出频率最高的号码,同时做一个可视化的网站展示出来。
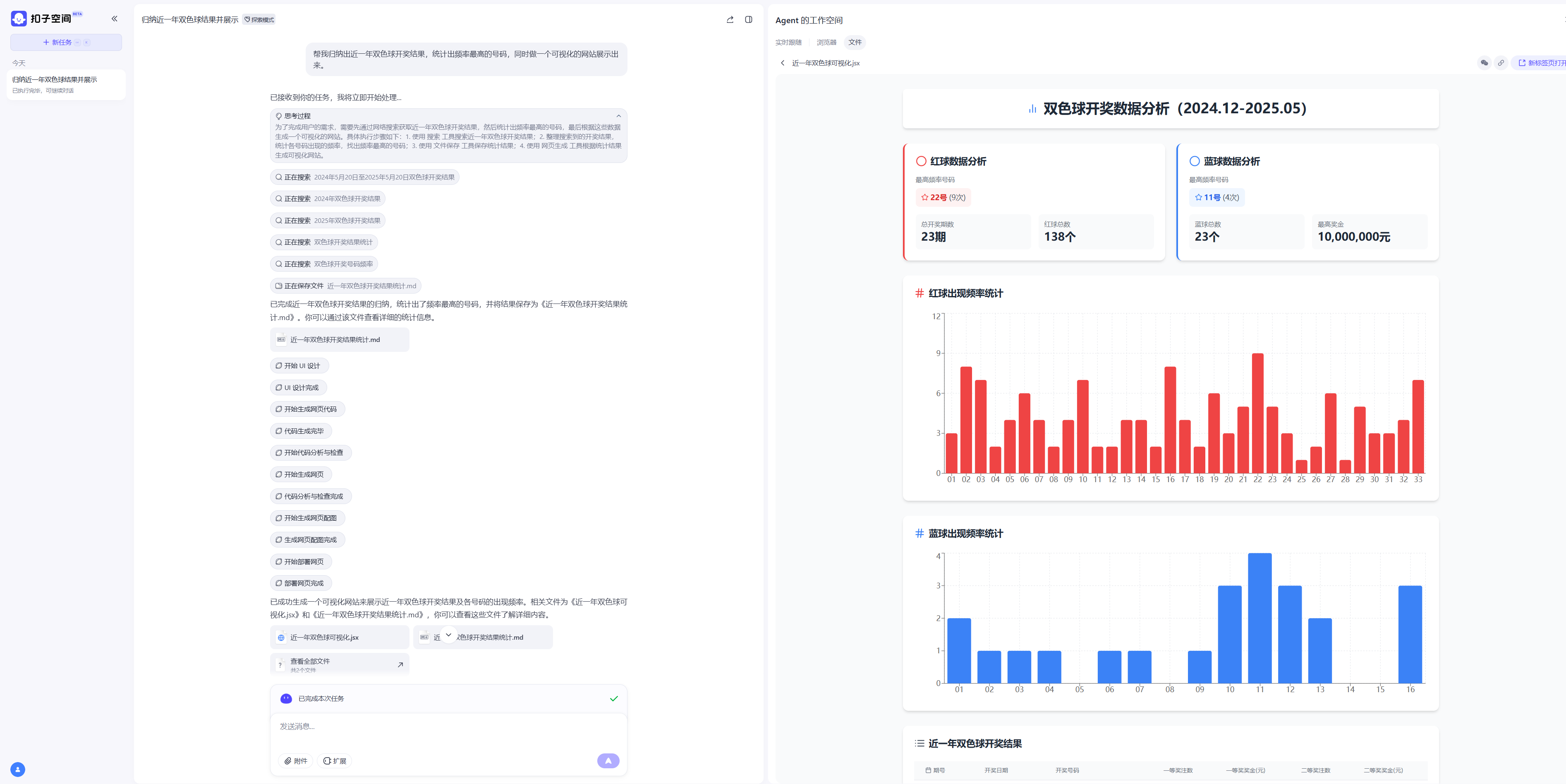
第一步就是去查找近一年的双色球的开奖情况,第二步就是自己写个脚本去统计所有的号码次数,第三步再写一个在线网页去展示出来,得出近一年的红球和篮球最高频率来反馈。
这整个流程下来,是不是有任务规划,然后工具调用去执行,最后再通过某种方式存储下来是吧。 这个扣子空间和manus其实是一样的东西,当然现在manus可以注册了但是也没什么热度了。
所以给个定义就是:AI Agent(人工智能代理)是一种能够感知环境、进行决策和执行动作的智能实体,具备独立思考、调用工具去逐步完成给定目标的能力! 了解漫威的都知道,钢铁侠里面有个管家,叫做贾维斯,这个其实就是你的AI管家,你可以理解为贾维斯就是智能体,只是他实体化了,有手脚了。 这是一个非常有价值的东西,所以大家对于Agent这块,应该是抱有无限的热情的。
说个题外话,Agent这个概念,最早是2023一位名叫叫做莉莉安.翁,这个莉莉安不是宋冬野那个莉莉安,而是OpenAI的一个华人工程师,北大毕业的。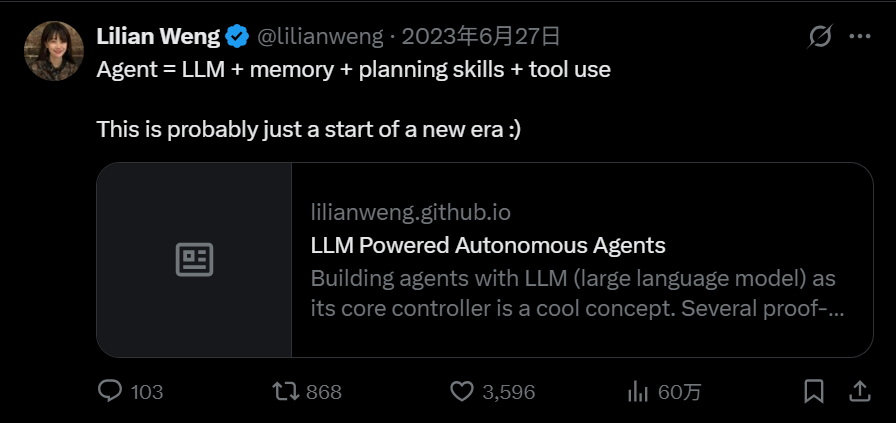
她提出来,Agent=LLM大模型+记忆能力+任务拆分+工具的使用, 记忆是因为大模型是没有记忆能力的,就和我们的pdf 的ai一样是吧,没有上下文,所以他不是agent,所以Agent是需要有记忆能力,多次问话是需要我上面问了什么问题,所以是需要有一些内存、磁盘的储存,planning skills是规划,也就是刚刚我们双色球那个例子,会把每一步进行一个拆解,完成我具体要怎么去做,达成目标的一个规划,tool use就是一个工具的调用和执行了,因为我们去完成某个指令的时候,是需要和外部工具的链接,也就是我们刚刚讲解的function calling、mcp server等等,都是去解决工具调用一系列的问题。
明显,叫做莉莉安的都厉害,人家23年提出来的,25年完全按照他的公式去做了,所以后面她还有一句话,就是 this is probably just a start of a new era,这个可能会开启一个新的时代,25年可以证明,确实已经开启了新的时代。
关于Agent,大家可以去用用扣子空间、文心智能平台、腾讯元器、阿里云的百炼都是一个Agent平台。

